
Windows 10 Apache Spark安装教程介绍
Apache Spark 是一个开源框架,可处理来自多个源的大量流数据。Spark 用于具有机器学习应用程序、数据分析和图形并行处理的分布式计算。
如何在Windows上安装Apache Spark?本指南将向你展示如何在 Windows 10 上安装 Apache Spark并测试安装。
先决条件
- 运行 Windows 10 的系统
- 具有管理员权限的用户帐户(安装软件、修改文件权限和修改系统路径所需)
- 命令提示符或 Powershell
- 提取 .tar 文件的工具,例如 7-Zip
在 Windows 上安装 Apache Spark
Windows 10如何安装Apache Spark?对于新手用户来说,在 Windows 10 上安装 Apache Spark 似乎很复杂,但是这个简单的教程会让你开始使用。如果你已经安装了 Java 8 和 Python 3,则可以跳过前两步。
第 1 步:安装 Java 8
Apache Spark 需要 Java 8。你可以使用命令提示符检查是否安装了 Java。
通过单击开始> 键入cmd > 单击命令提示符打开命令行。
在命令提示符中键入以下命令:
java -version如果安装了 Java,它将响应以下输出:
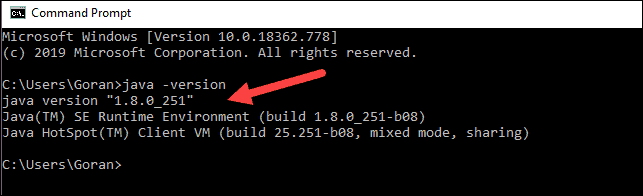
你的版本可能有所不同。第二个数字是 Java 版本——在本例中是 Java 8。
如果你没有安装 Java:
1. 打开浏览器窗口,并导航到https://java.com/en/download/。
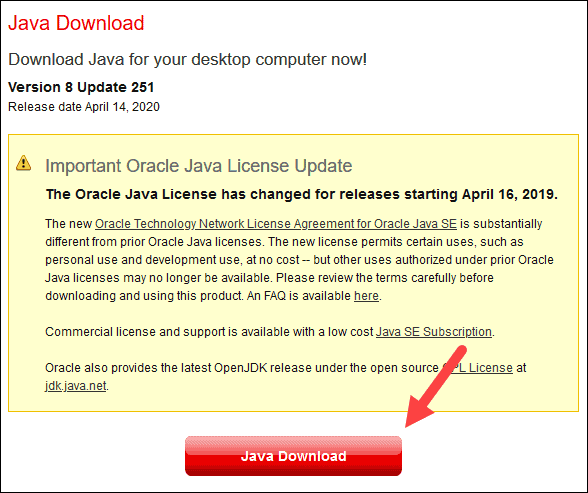
2. 单击Java 下载按钮并将文件保存到你选择的位置。
3. 下载完成后双击该文件以安装 Java。
注意:在撰写本文时,最新的 Java 版本为 1.8.0_251。安装更高版本仍然有效。此过程只需要 Java 运行时环境 (JRE) – 不需要完整的开发工具包 (JDK)。JDK 的下载链接是https://www.oracle.com/java/technologies/javase-downloads.html。
第 2 步:安装 Python
1. 要安装 Python 包管理器,请在 Web 浏览器中导航到https://www.python.org/。
2. 将鼠标悬停在下载菜单选项上,然后单击Python 3.8.3。3.8.3 是撰写本文时的最新版本。
3. 下载完成后,运行该文件。
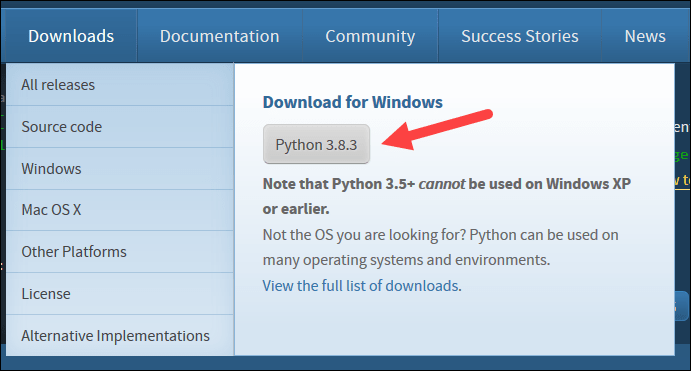
4. 在第一个设置对话框底部附近,勾选Add Python 3.8 to PATH。选中另一个框。
5. 接下来,单击自定义安装。
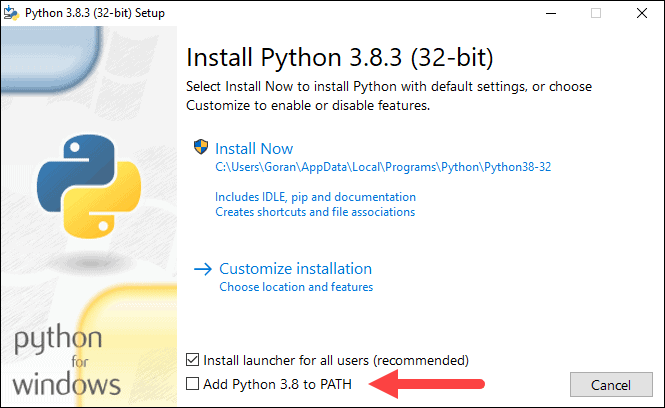
6. 你可以在此步骤中选中所有复选框,也可以取消选中你不想要的选项。
7. 单击下一步。
8. 选择为所有用户安装框,其他框保持原样。
9. 在自定义安装位置下,单击浏览并导航到 C 盘。添加一个新文件夹并将其命名为Python。
10. 选择该文件夹并单击确定。
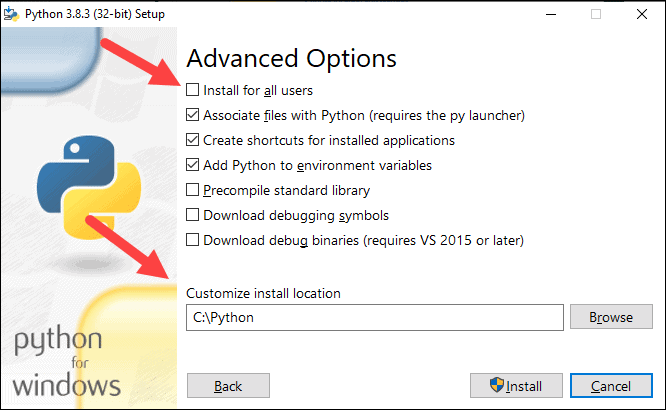
11. 点击安装,让安装完成。
12. 安装完成后,单击底部的禁用路径长度限制选项,然后单击关闭。
13. 如果你打开了命令提示符,请重新启动它。通过检查 Python 版本来验证安装:
python --version输出应该打印Python 3.8.3。
注意:有关如何在 Windows 上安装 Python 3 或如何解决潜在问题的详细说明,请参阅我们的在 Windows 上安装 Python 3指南。
第 3 步:Windows 10如何安装Apache Spark - 下载安装包
1. 打开浏览器并导航到https://spark.apache.org/downloads.html。
2. 在下载 Apache Spark标题下,有两个下拉菜单。使用当前的非预览版本。
- 在我们的例子中,在选择 Spark 版本下拉菜单中选择2.4.5 (Feb 05 2020)。
- 在第二个下拉选择包类型中,保留选择Pre-built for Apache Hadoop 2.7。
3. 点击spark-2.4.5-bin-hadoop2.7.tgz 链接。
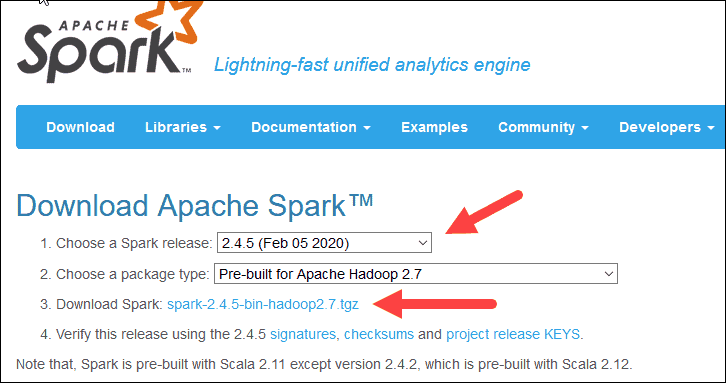
4. 加载镜像列表的页面,你可以在其中查看要下载的不同服务器。从列表中选择任何一个并将文件保存到你的下载文件夹。
步骤 4:验证 Spark 软件文件 - Windows 10 Apache Spark安装教程
1. 通过检查文件的校验和来验证下载的完整性。这可确保你使用未更改、未损坏的软件。
2. 导航回Spark 下载页面并打开校验和链接,最好在新选项卡中。
3.接下来,打开命令行并输入以下命令:
certutil -hashfile c:\users\username\Downloads\spark-2.4.5-bin-hadoop2.7.tgz SHA5124.将用户名更改为你的用户名。系统会显示一个长字母数字代码以及消息Certutil: -hashfile completed successfully。
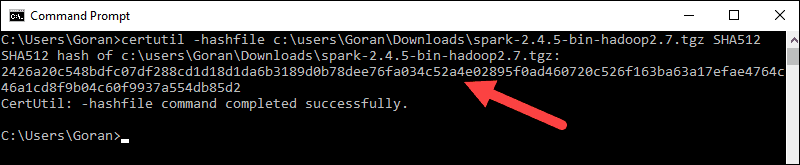
5. 将代码与你在新浏览器选项卡中打开的代码进行比较。如果它们匹配,则你的下载文件未损坏。
第 5 步:安装 Apache Spark
如何在Windows上安装Apache Spark?安装 Apache Spark 涉及将下载的文件解压缩到所需位置。
1.在 C: 驱动器的根目录中创建一个名为Spark的新文件夹。从命令行,输入以下内容:
cd \
mkdir Spark2. 在资源管理器中,找到你下载的 Spark 文件。
3. 右键单击该文件并使用系统上的工具(例如 7-Zip)将其解压缩到C:\Spark。
4. 现在,你的C:\Spark文件夹中有一个新文件夹spark-2.4.5-bin-hadoop2.7,其中包含必要的文件。
第 6 步:添加 winutils.exe 文件
为你下载的 Spark 安装的底层 Hadoop 版本下载winutils.exe文件。
1. 导航到此 URL https://github.com/cdarlint/winutils并在bin文件夹中找到winutils.exe并单击它。
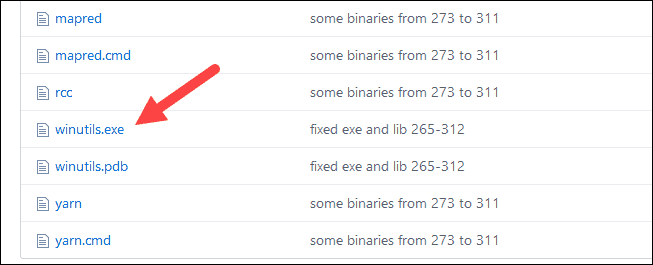
2. 找到右侧的下载按钮下载文件。
3. 现在,使用 Windows 资源管理器或命令提示符在 C 上创建新文件夹Hadoop 和bin。
4. 将 winutils.exe 文件从 Downloads 文件夹复制到C:\hadoop\bin。
步骤 7:配置环境变量
Windows 10如何安装Apache Spark?在 Windows 中配置环境变量会将 Spark 和 Hadoop 位置添加到你的系统 PATH。它允许你直接从命令提示符窗口运行 Spark shell。
1. 单击开始并键入environment。
2. 选择标记为Edit the system environment variables的结果。
3. 系统属性对话框出现。在右下角,单击环境变量,然后在下一个窗口中单击新建。
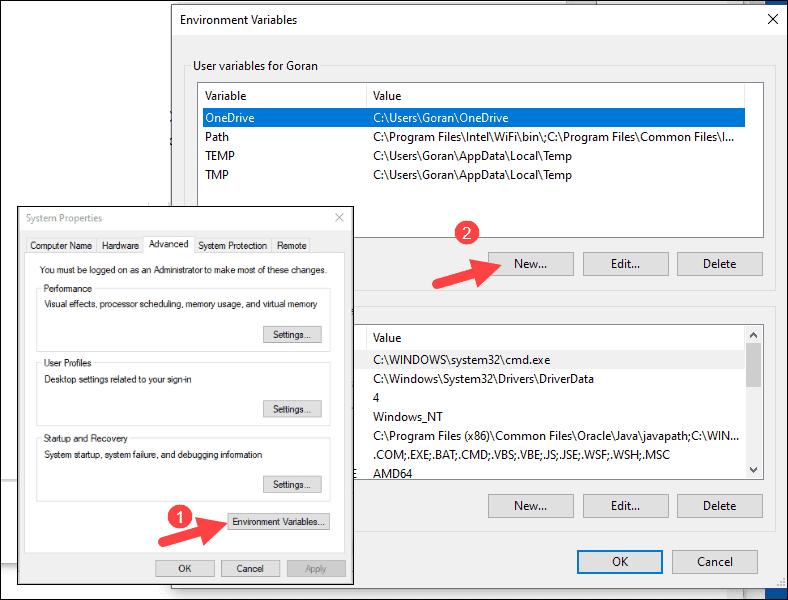
4. 对于变量名称,输入SPARK_HOME。
5. 对于变量值,键入C:\Spark\spark-2.4.5-bin-hadoop2.7,然后单击确定。如果你更改了文件夹路径,请改用该路径。
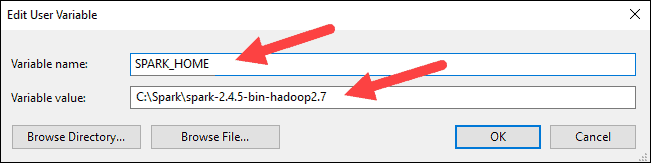
6. 在顶部框中,单击路径条目,然后单击编辑。编辑系统路径时要小心。避免删除列表中已有的任何条目。
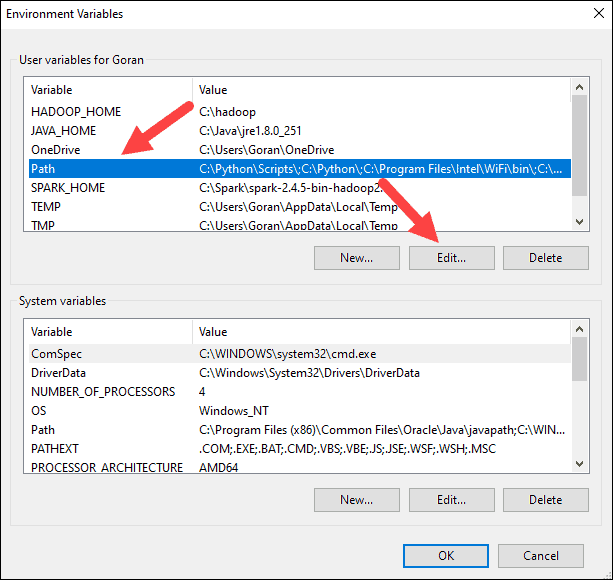
7. 你应该会在左侧看到一个带有条目的框。在右侧,单击新建。
8. 系统高亮显示新行。输入 Spark 文件夹的路径C:\Spark\spark-2.4.5-bin-hadoop2.7\bin。我们建议使用%SPARK_HOME%\bin以避免路径可能出现的问题。
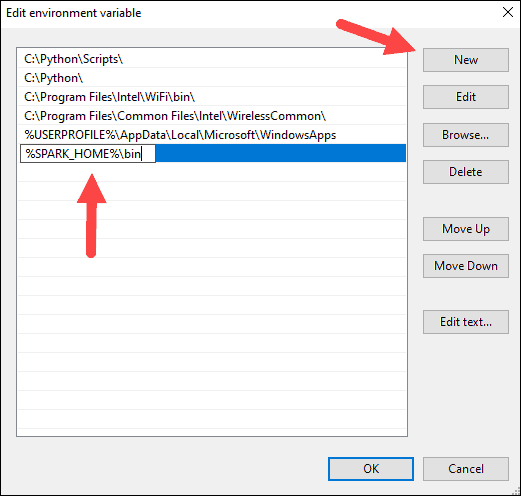
9. 对 Hadoop 和 Java 重复此过程。
- 对于 Hadoop,变量名是HADOOP_HOME ,值使用你之前创建的文件夹的路径:C:\hadoop。将C:\hadoop\bin添加到Path 变量字段,但我们建议使用%HADOOP_HOME%\bin。
- 对于 Java,变量名是JAVA_HOME,值使用 Java JDK 目录的路径(在我们的例子中是C:\Program Files\Java\jdk1.8.0_251)。
10. 单击确定关闭所有打开的窗口。
注意:通过重新启动命令提示符来应用更改。如果这不起作用,你将需要重新启动系统。
第 8 步:启动 Spark
1. 如何在Windows上安装Apache Spark?使用右键单击并以管理员身份运行打开一个新的命令提示符窗口:
2. 要启动 Spark,请输入:
C:\Spark\spark-2.4.5-bin-hadoop2.7\bin\spark-shell如果正确设置环境路径,则可以键入spark-shell以启动 Spark。
3. 系统应显示多行指示应用程序的状态。你可能会看到 Java 弹出窗口。选择允许访问以继续。
最后,会出现 Spark 徽标,并且提示会显示Scala shell。
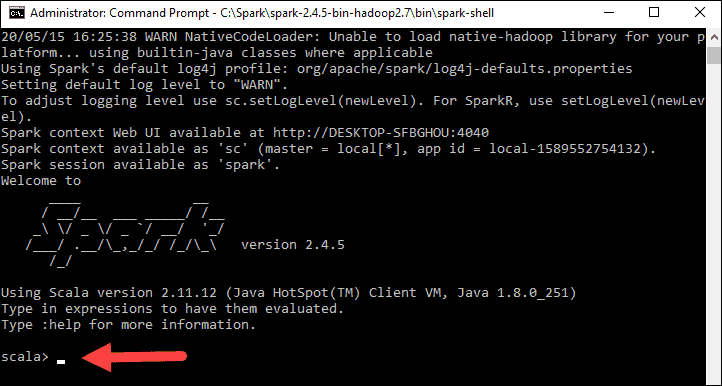
4., 打开网页浏览器并导航到http://localhost:4040/。
5. 你可以将localhost替换为你的系统名称。
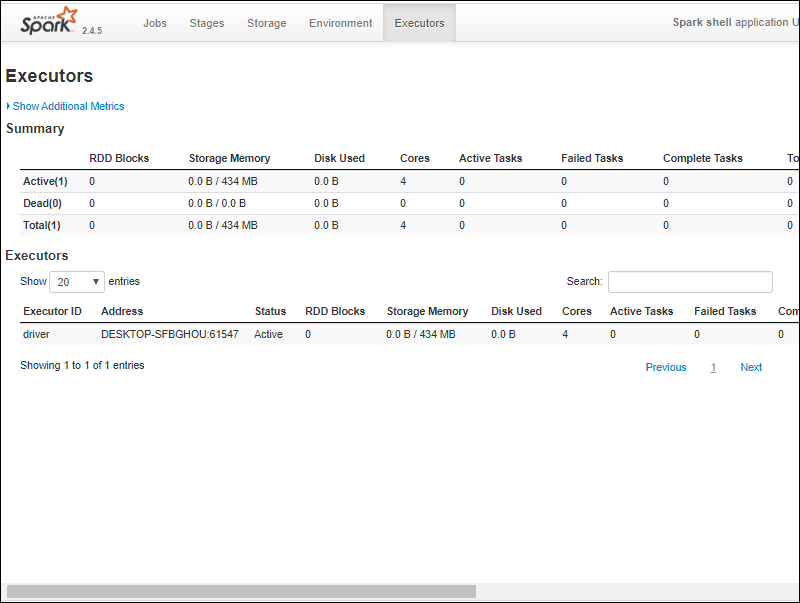
6. 你应该会看到一个 Apache Spark shell Web UI。下面的示例显示了Executors页面。
7. 要退出 Spark 并关闭 Scala shell,请ctrl-d 在命令提示符窗口中按 。
注意:如果你安装了 Python,则可以使用 Python 使用以下命令运行 Spark:
pyspark
使用 quit() 退出。
Windows 10 Apache Spark安装教程:测试Spark
Windows 10如何安装Apache Spark?在本例中,我们将启动 Spark shell 并使用 Scala 读取文件的内容。你可以使用现有文件,例如Spark 目录中的README文件,也可以创建自己的文件。我们用一些文本创建了pnaptest。
1. 打开命令提示符窗口并导航到要使用的文件所在的文件夹,然后启动 Spark shell。
2. 首先,用文件名声明一个在 Spark 上下文中使用的变量。如果有,请记住添加文件扩展名。
val x =sc.textFile("pnaptest")3. 输出显示已创建 RDD。然后,我们可以通过使用此命令调用操作来查看文件内容:
x.take(11).foreach(println)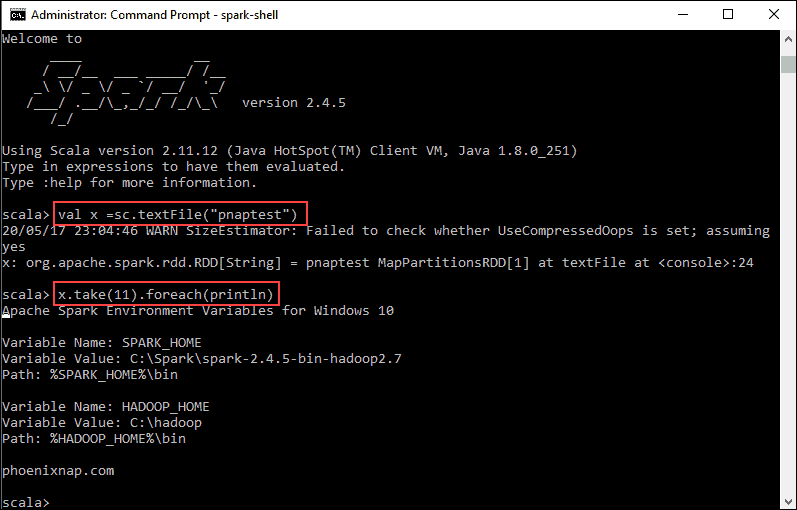
如何在Windows上安装Apache Spark?此命令指示 Spark 从你指定的文件中打印 11 行。要对该文件执行操作(值 x),请添加另一个值y,并进行映射转换。
4. 例如,你可以使用以下命令反向打印字符:
val y = x.map(_.reverse)5. 系统创建与第一个相关的子 RDD。然后,指定要从值y打印多少行:
y.take(11).foreach(println)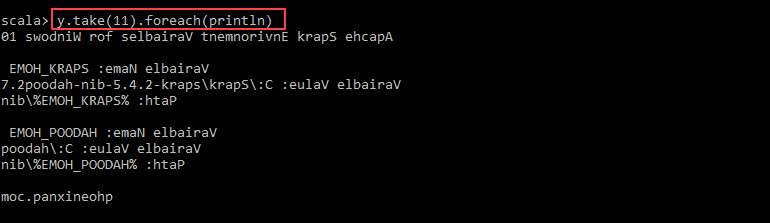
输出以相反的顺序打印pnaptest文件的11 行。
完成后,使用ctrl-d.
Windows 10 Apache Spark安装教程结论
Windows 10如何安装Apache Spark?你现在应该在 Windows 10 上安装了 Apache Spark,并安装了所有依赖项。开始在你的 Windows 环境中运行 Spark 实例。
我们的建议是还可以了解更多有关Spark DataFrame是什么、其功能以及在收集数据时如何使用 Spark DataFrame 的信息。

