
Python安装和使用Pandas教程介绍
Pandas 是一个开源 Python 库,主要用于数据分析。Pandas 包中的工具集合是在 Python 中准备、转换和聚合数据的重要资源。
Pandas 库基于 NumPy 包,并与大量现有模块兼容。添加了两个新的表格数据结构Series和DataFrames,使用户能够利用类似于关系数据库或电子表格中的功能。
Python如何安装和使用Pandas?本文将向你展示如何安装 Python Pandas并介绍基本的 Pandas 命令。
如何安装 Python Pandas
Python 的流行导致创建了许多发行版和软件包。包管理器是用于自动化安装过程、管理升级、配置和删除 Python 包和依赖项的高效工具。
注意: Python 3.6.1或更高版本是 Pandas 安装的先决条件。使用我们的详细指南检查你当前的 Python 版本。如果你没有所需的 Python 版本,你可以使用以下详细指南之一:
- 如何在 Ubuntu 18.04 或 Ubuntu 20.04 上安装 Python 3.8。
- 如何在 Windows 10 上安装 Python 3
- 如何在 Centos 7 上安装最新版本的 Python 3
使用 Anaconda 安装 Pandas
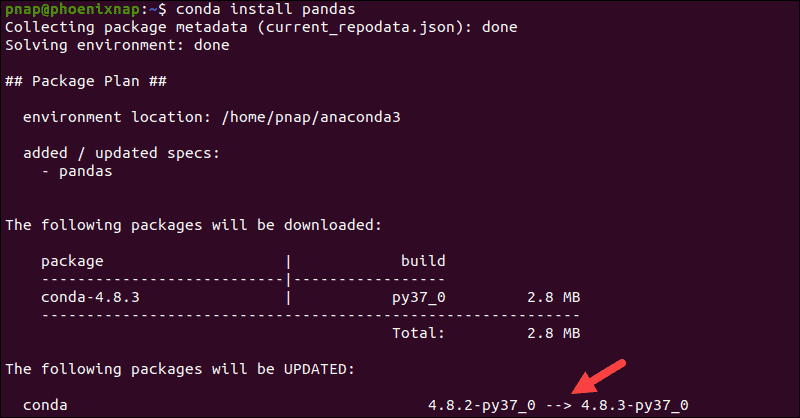
Python Pandas如何安装和使用?该Anaconda包已包含Pandas库。通过在终端中键入以下命令来检查当前的 Pandas 版本:
conda list pandas输出确认 Pandas 版本和构建。

如果你的系统上没有 Pandas,你还可以使用该conda工具安装 Pandas:
conda install pandasAnaconda 通过安装一组模块和依赖项来管理整个事务。
Python安装和使用Pandas教程:使用 pip 安装 Pandas
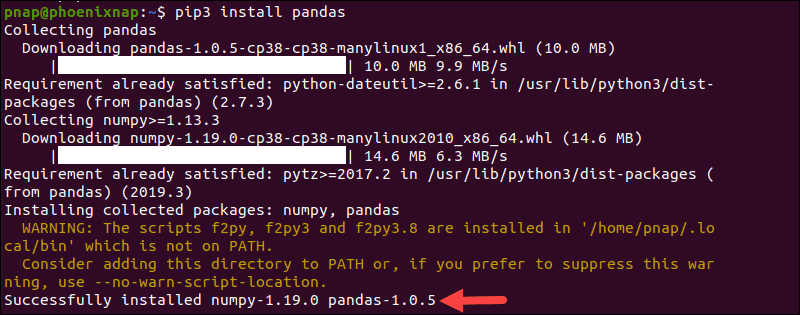
PyPI 软件存储库定期管理并维护基于 Python 的软件的最新版本。安装PyPI 包管理器pip,并使用它来部署 Python pandas:
pip3 install pandas下载和安装过程需要一些时间才能完成。
在 Linux 上安装 Pandas
安装预先打包的解决方案可能并不总是首选。你可以使用与其他模块相同的方法在任何 Linux 发行版上安装 Pandas。例如,使用以下命令在 Ubuntu 20.04 上安装基本的 Pandas 模块:
sudo apt install python3-pandas -y 请记住,Linux 存储库中的软件包通常不包含最新的可用版本。
使用 Python Pandas
Python如何安装和使用Pandas?Python 的灵活性使你可以在各种框架中使用 Pandas。这包括基本的 Python 代码编辑器、从终端的 Python shell 发出的命令、交互式环境(例如 Spyder、PyCharm、Atom 等)。本教程中的实际示例和命令是使用 Jupyter Notebook 呈现的。
导入 Python Pandas 库
要分析和处理数据,你需要在 Python 环境中导入 Pandas 库。使用以下命令启动 Python 会话并导入 Pandas:
import pandas as pdimport numpy as np它被认为是很好的做法,以导入Pandas作为pd和numpy的科学图书馆作为np。此操作允许你在键入命令时使用pd或np。否则,每次都需要输入完整的模块名称。

每次启动新的 Python 环境时都必须导入 Pandas 库。
Python安装和使用Pandas教程:Series和DataFrames
Python Pandas 使用 Series 和 DataFrames 来构建数据并为各种分析操作做好准备。这两种数据结构是 Pandas 多功能性的支柱。已经熟悉关系数据库的用户天生就了解基本的 Pandas 概念和命令。
Pandas Series
Series代表 Pandas 库中的一个对象。它们通过将每个数据元素与唯一标签配对来为简单的一维数据集提供结构。Series由两个数组组成 -保存数据的主数组和保存成对标签的索引数组。
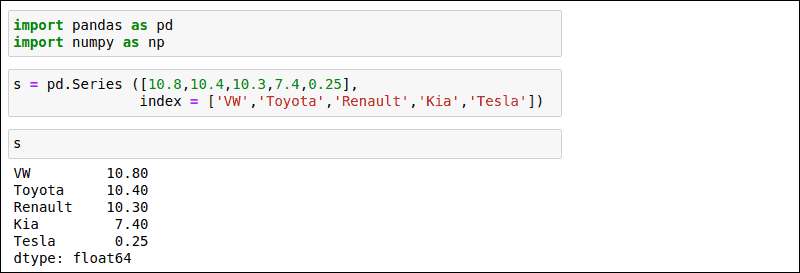
使用以下示例创建基本Series。在此示例中,Series构造按制造商索引的汽车销售编号:
s = pd.Series([10.8,10.7,10.3,7.4,0.25],
index = ['VW','Toyota','Renault','KIA','Tesla')
运行命令后,键入s以查看你刚刚创建的Series。结果根据输入的顺序列出制造商。
你可以在 Series 上执行一组复杂多样的函数,包括数学函数、数据操作和 Series 之间的算术运算。Pandas 官方页面上提供了Pandas 参数、属性和方法的完整列表。
Pandas DataFrames
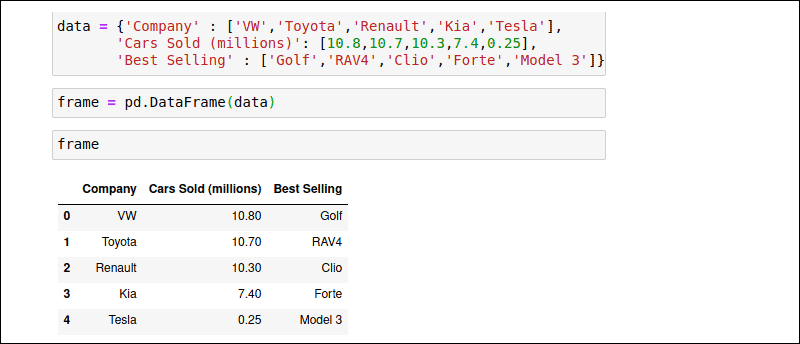
Python Pandas如何安装和使用?DataFrame 为 Series 数据结构引入了一个新维度。除了索引数组之外,一组严格排列的列为 DataFrame 提供了类似表格的结构。每列可以存储不同的数据类型。尝试使用相同的汽车销售数据手动创建一个名为 'data'的dict对象:
data = { 'Company' : ['VW','Toyota','Renault','KIA','Tesla'],
'Cars Sold (millions)' : [10.8,10.7,10.3,7.4,0.25],
'Best Selling Model' : ['Golf','RAV4','Clio','Forte','Model 3']}将“数据”对象传递给pd.DataFrame()构造函数:
frame = pd.DataFrame(data)使用 DataFrame 的名称frame, 来运行对象:
frame生成的 DataFrame 将值格式化为行和列。
DataFrame 结构允许你根据列和行选择和过滤值、分配新值以及转置数据。与 Series 一样,Pandas 官方页面提供了DataFrame 参数、属性和方法的完整列表。
使用Pandas读写
Python如何安装和使用Pandas?通过 Series 和 DataFrames,Pandas 引入了一组功能,使用户能够导入文本文件、复杂的二进制格式和存储在数据库中的信息。在 Pandas 中读写数据的语法很简单:
pd.read_filetype = (filename or path)– 将其他格式的数据导入 Pandas。df.to_filetype = (filename or path)– 将数据从 Pandas 导出为其他格式。
最常见的格式包括CSV、XLXS、JSON、HTML和SQL。
| 读 | 写 |
|---|---|
| pd.read_csv ('文件名.csv') | df.to_csv ('文件名或路径') |
| pd.read_excel ('文件名.xlsx') | df.to_excel ('文件名或路径') |
| pd.read_json ('文件名.json') | df.to_json ('文件名或路径') |
| pd.read_html ('文件名.htm') | df.to_html ('文件名或路径') |
| pd.read_sql ('表名') | df.to_sql ('数据库名称') |
在此示例中,nz_population CSV 文件包含新西兰过去 10 年的人口数据。使用以下命令将 CSV 文件导入 Pandas 库:
pop_df = pd.read_csv('nz_population.csv')用户可以自由定义 DataFrame 的名称 ( pop_df )。键入新创建的 DataFrame 的名称以显示数据数组:
pop_df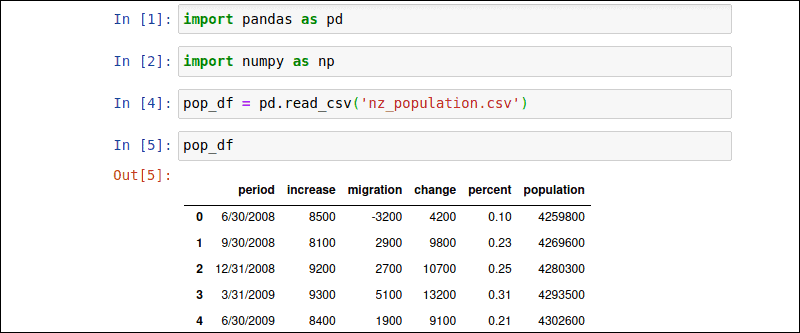
Python安装和使用Pandas教程:常见的 Pandas 命令
将文件导入 Pandas 库后,你可以使用一组简单的命令来探索和操作数据集。
基本DataFrames命令
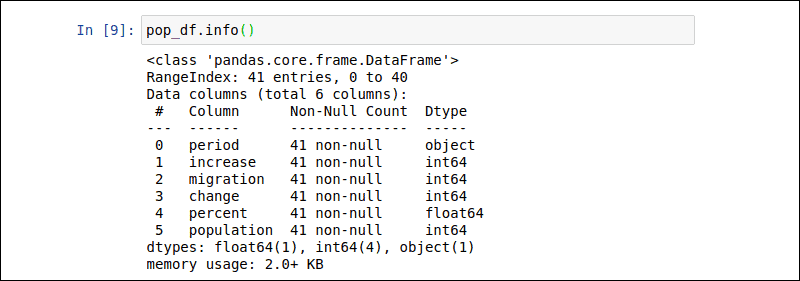
Python如何安装和使用Pandas?输入以下命令以检索上一个示例中pop_df DataFrame的概览:
pop_df.info()输出提供条目数、每列的名称、数据类型和文件大小。
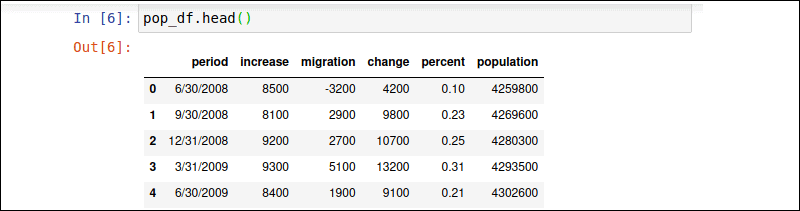
使用该pop_df.head()命令显示 DataFrame 的前 5 行。
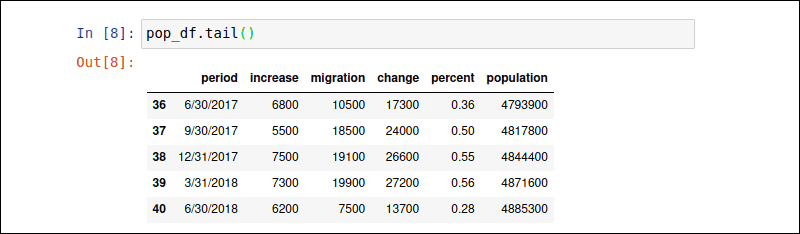
键入pop_df.tail()命令以显示pop_df DataFrame的最后 5 行。
使用名称和iloc属性选择特定的行和列。使用方括号内的名称选择单个列:
pop_df['population']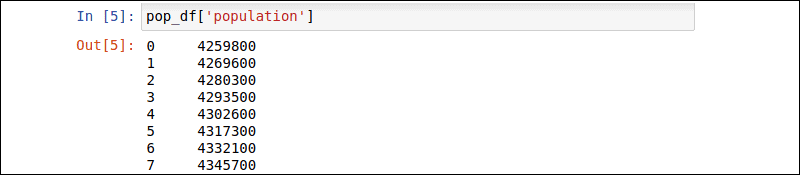
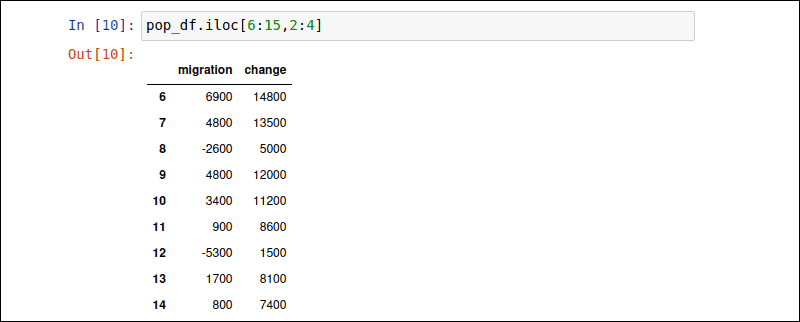
该iloc属性允许你检索行和列的子集。在逗号前面指定行,在逗号后面指定列。以下命令检索第 6 到 16 行和第 2 到 4 列的数据:
pop_df.iloc [6:15,2:4]冒号:指示 Pandas 显示整个指定的子集。
条件表达式
你可以根据条件表达式选择行。条件在方括号内定义[]。以下命令过滤 'percent' 列值大于 0.50% 的行。
pop_df [pop_df['percent'] > 0.50]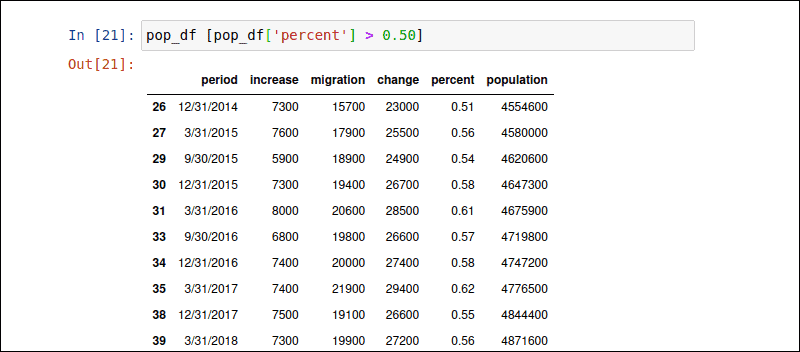
数据聚合
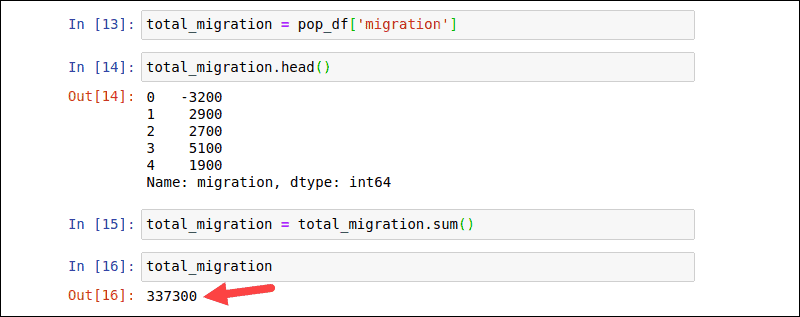
Python Pandas如何安装和使用?使用函数计算整个数组的值并生成单个结果。方括号[]还允许用户选择单个列并将其转换为 DataFrame。以下命令从 pop_df 中的迁移列创建一个新的total_migration DataFrame:
total_migration = pop_df['migration']通过检查前 5 行来验证数据:
total_migration.head()使用以下df.sum()函数计算进入新西兰的净迁移:
total_migration = total_migration.sum()total_migration输出产生一个单一的结果,表示total_migration DataFrame中的值的总和。
一些更常见的聚合函数包括:
df.mean()– 计算值的平均值。df.median()– 计算值的中位数。df.describe()– 提供统计摘要。df.min()/df.max()– 数据集中的最小值和最大值。df.idxmin()/df.idxmax()– 最小和最大索引值。
这些基本功能仅代表 Pandas 必须提供的可用操作和操作的一小部分。
Python安装和使用Pandas教程结论
Python如何安装和使用Pandas?你已经成功安装了 Python Pandas 并学习了如何管理简单的数据结构。本教程中概述的示例和命令序列向你展示了如何在 Python Pandas 中准备、处理和聚合数据。

