
介绍
HDFS(Hadoop 分布式文件系统)是Apache Hadoop 项目的重要组成部分。Hadoop 是一个软件生态系统,可协同工作以帮助你管理大数据。Hadoop 的两个主要元素是:
- MapReduce——负责执行任务
- HDFS——负责维护数据
什么是HDFS?在本文中,我们将讨论两个模块中的第二个。你将了解 HDFS 是什么、它是如何工作的以及基本的 HDFS 术语。
注意:如果你运行的是 Ubuntu 系统并且想要设置 Hadoop,请参阅如何在 Ubuntu 上安装 Hadoop。
Hadoop分布式文件系统指南:什么是 HDFS?
Hadoop分布式文件系统是一种运行在商用硬件上的容错数据存储文件系统。它旨在克服传统数据库无法克服的挑战。因此,只有在处理大数据时才能充分发挥其潜力。
Hadoop 文件系统必须解决的主要问题是速度、成本和可靠性。
HDFS有什么好处?
HDFS 的好处实际上是文件系统为前面提到的挑战提供的解决方案:
- 它很快。由于其集群架构,它每秒可以提供超过 2 GB 的数据。
- 这是免费的。HDFS 是一种开源软件,无需许可或支持成本。
- 这是可靠的。 文件系统将多个数据副本存储在不同的系统中,以确保它始终可以访问。
这些优势在处理大数据时尤为重要,并且通过 HDFS 处理数据的特殊方式成为可能。
注意: Hadoop 只是大数据处理的一种解决方案。另一个流行的开源框架是 Spark。想更多地了解这些大数据处理解决方案之间的主要区别吗?查看Hadoop 与 Spark – 详细比较。
HDFS如何工作:HDFS 如何存储数据?
HDFS 将文件分成块并将每个块存储在一个 DataNode 上。多个 DataNode 链接到集群中的主节点 NameNode。主节点在整个集群中分发这些数据块的副本。它还指示用户在哪里可以找到想要的信息。
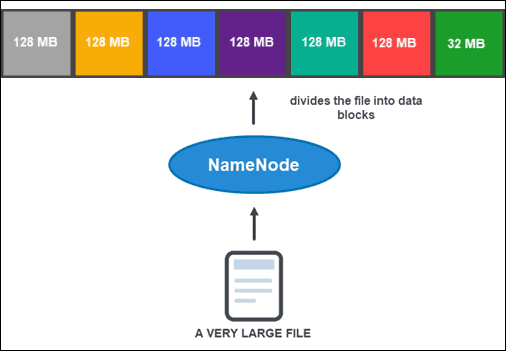
但是,在 NameNode 可以帮助你存储和管理数据之前,它首先需要将文件分区为更小的、可管理的数据块。这个过程称为数据块拆分。
数据块拆分
默认情况下,一个块的大小不能超过 128 MB。块数取决于文件的初始大小。除了最后一个块外,所有块的大小都相同 (128 MB),而最后一个块是文件的剩余部分。
例如,一个 800 MB 的文件被分成七个数据块。七个块中的六个是 128 MB,而第七个数据块是剩余的 32 MB。
然后,每个块被复制成多个副本。
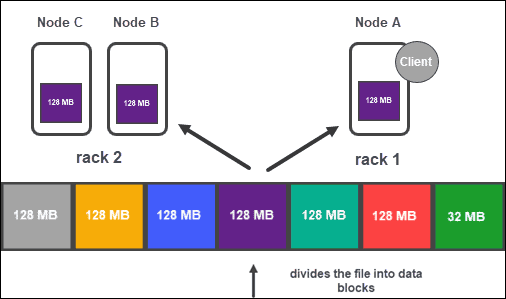
Hadoop分布式文件系统指南:数据复制
根据集群的配置,NameNode 使用复制方法为每个数据块创建多个副本。
建议至少有三个副本,这也是默认设置。主节点将它们存储到集群的单独 DataNode 上。节点的状态受到密切监控,以确保数据始终可用。
HDFS如何工作?为了确保高可访问性、可靠性和容错性,开发人员建议使用以下拓扑设置三个副本:
- 将第一个副本存储在客户端所在的节点上。
- 然后,将第二个副本存储在不同的机架上。
- 最后,将第三个副本存储在与第二个副本相同的机架上,但位于不同的节点上。
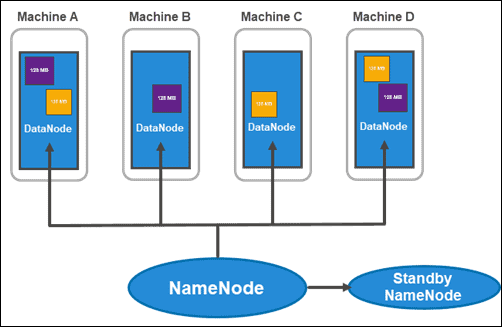
HDFS 架构:NameNodes 和 DataNodes
什么是HDFS?HDFS 具有主从架构。主节点是NameNode,它管理集群内的多个从节点,称为DataNodes。
名称节点
Hadoop 2.x 引入了每个机架具有多个 NameNode 的可能性。这种新颖性非常重要,因为拥有一个包含集群内所有信息的单一主节点会带来很大的漏洞。
通常的集群由两个 NameNode 组成:
- 一个活跃的 NameNode
- 和一个备用的 NameNode
第一个处理集群内的所有客户端操作,第二个在需要故障转移时与其所有工作保持同步。
的活性的NameNode 跟踪每个数据块及其副本的元数据。这包括文件名、权限、ID、位置和副本数。它将所有信息保存在fsimage 中,这是一个存储在文件系统本地内存中的命名空间映像。此外,它还维护称为EditLogs 的事务日志,记录系统上所做的所有更改。
注意:每当添加、复制或删除新块时,它都会记录在 EditLogs 中。
Stanby NameNode 的主要目的是解决单点故障问题。它读取对 EditLogs 所做的任何更改并将其应用到其命名空间(数据中的文件和目录)。如果主节点出现故障,Zookeeper服务会执行故障转移,允许备用节点保持活动会话。
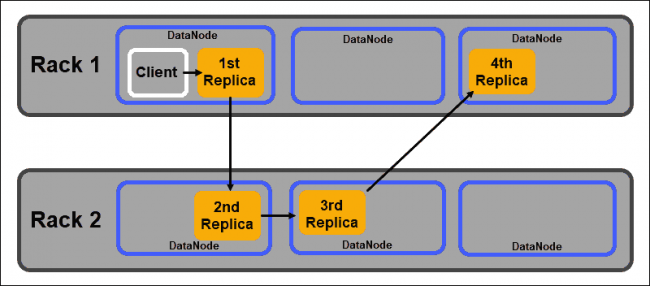
数据节点
DataNode 是从守护进程,用于存储 NameNode 分配的数据块。如上所述,默认设置确保每个数据块具有三个副本。你可以更改副本的数量,但是,建议不要低于三个。
HDFS如何工作?应根据 Hadoop 的机架感知策略分发副本,该策略指出:
- 副本的数量必须大于机架的数量。
- 一个DataNode只能存储一个数据块的一个副本。
- 一个机架不能存储两个以上的数据块副本。
通过遵循这些准则,你可以:
- 最大化网络带宽。
- 防止数据丢失。
- 提高性能和可靠性。
注意:如果在裸机云基础架构上运行,可以充分体验 Hadoop 的可扩展性,该基础架构提供按小时计费和轻松配置数千台服务器的能力。要了解更多信息,请阅读什么是裸机云。
Hadoop分布式文件系统指南:HDFS 的主要特性
这些是 Hadoop 分布式文件系统的主要特征:
1. 管理大数据。 HDFS 在处理大型数据集方面非常出色,并提供了传统文件系统无法提供的解决方案。它通过将数据分成可管理的块来实现这一点,从而实现快速处理。
2. 机架感知。 它遵循机架感知准则,确保系统高度可用和高效。
3. 容错。 由于数据存储在多个机架和节点上,因此会被复制。这意味着如果集群中的任何一台机器发生故障,该数据的副本将从不同的节点获得。
4. 可扩展。你可以根据文件系统的大小扩展资源。HDFS 包括垂直和水平可扩展性机制。
HDFS 现实生活中的使用
什么是HDFS?处理大量数据的公司早就开始迁移到 Hadoop,Hadoop 是处理大数据的领先解决方案之一,因为它具有存储和分析功能。
金融服务。Hadoop 分布式文件系统旨在支持预计呈指数增长的数据。该系统是可扩展的,而不会降低复杂数据处理的速度。
零售。由于了解客户是零售业成功的关键因素,因此许多公司保留大量结构化和非结构化客户数据。他们使用 Hadoop 跟踪和分析收集到的数据,以帮助规划未来的库存、定价、营销活动和其他项目。
电信。电信行业管理着大量数据,并且必须处理数 PB 级的数据。它使用 Hadoop 分析来管理呼叫数据记录、网络流量分析和其他电信相关流程。
能源行业。能源行业一直在寻找提高能源效率的方法。它依赖于 Hadoop 及其文件系统等系统来帮助分析和理解消费模式和实践。
保险。医疗保险公司依赖数据分析。这些结果是他们制定和实施政策的基础。对于保险公司来说,洞察客户历史是无价的。能够在不断增长的同时维护易于访问的数据库,这就是许多人转向 Apache Hadoop 的原因。
注意:存储在 HDSF 中的数据由 Apache Hive 查询、管理和分析,Apache Hive 是一个构建在 Hadoop 之上的数据仓库系统。如果你有 Ubuntu 系统并想开始使用 Hive,请参阅如何在 Ubuntu 上安装 Hive以及如何在 Hive 中创建表。
Hadoop分布式文件系统指南结论
阅读本文后,你应该对 HDFS 是什么以及它在 Apache Hadoop 生态系统中扮演的角色有了更好的了解。
如果你正在处理大数据,或者希望增长到如此规模,Hadoop 和 HDFS 可以让事情变得更容易。

