
Spark DataFrame 是一种集成数据结构,具有易于使用的 API,用于简化分布式大数据处理。DataFrame 可用于通用编程语言,例如 Java、Python 和 Scala。
它是 Spark RDD API 的扩展,优化用于在保持强大的同时更高效地编写代码。
如何使用Spark DataFrame?这篇文章解释了 Spark DataFrame 是什么、特性以及在收集数据时如何使用 Spark DataFrame。
先决条件
- Spark 安装和配置(按照我们的指南:如何在 Ubuntu上安装 Spark,如何在 Windows 10 上安装 Spark)。
- 配置为在 Java、Python 或 Scala 中使用 Spark 的环境(本指南使用 Python)。
什么是Spark DataFrame?
Spark DataFrame有什么特性?DataFrame 是 Spark SQL 模块中的一个编程抽象。DataFrames 类似于关系数据库表或带有标题的 Excel 电子表格:数据驻留在不同数据类型的行和列中。

处理是使用复杂的用户定义函数和熟悉的数据操作函数来实现的,例如排序、连接、分组等。
分布式数据的信息被组织成模式。DataFrame 中的每一列都包含列名、数据类型和可为空的属性。当nullable设置为true 时,列也接受null属性。

DataFrame是如何工作的?
DataFrame API 是 Spark SQL 模块的一部分。该 API 提供了一种在 Spark SQL 框架内处理数据的简单方法,同时与 Java、Python 和 Scala 等通用语言集成。
虽然Python Pandas和 R DataFrame有相似之处,但 Spark 做了一些不同的事情。此 API 是为与大规模数据集成以进行数据科学和机器学习而量身定制的,并带来了众多优化。
Spark DataFrame 可跨多个集群分发并使用 Catalyst 进行优化。Catalyst 优化器接受查询(包括应用于 DataFrame 的SQL 命令)并创建最佳并行计算计划。
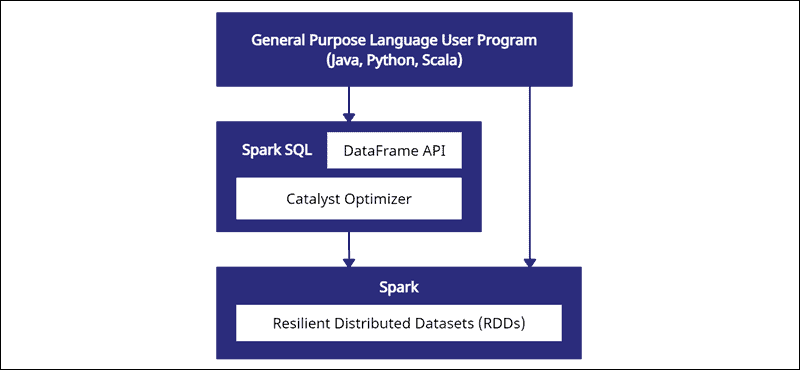
如果你有 Python 和 R DataFrame经验,Spark DataFrame 代码看起来很熟悉。另一方面,如果你使用 Spark RDD(弹性分布式数据集),则获得有关数据结构的信息可提供优化机会。
什么是Spark DataFrame?Spark 的创建者设计了 DataFrames 以最有效的方式应对大数据挑战。开发人员可以通过熟悉但更优化的 API 来利用分布式计算的强大功能。
Spark DataFrame的特点
Spark DataFrame有什么特性?Spark DataFrame 具有许多有价值的功能:
- 支持多种数据格式,如Hive、CSV、XML、JSON、RDDs、Cassandra、Parquet 等。
- 支持与各种大数据工具的集成。
- 在较小的机器上处理千字节数据和在集群上处理 PB 数据的能力。
- 用于跨多种语言进行高效数据处理的催化剂优化器。
- 通过数据示意图进行结构化数据处理。
- 与 RDD 相比,自定义内存管理可减少过载并提高性能。
- 适用于 Java、R、Python 和 Spark 的 API。
注意:在我们的帖子RDD vs. DataFrame vs. Dataset 中熟悉由 Apache Spark 提供的三种不同的大数据 API 。
如何创建 Spark DataFrame?
如何使用Spark DataFrame?有多种方法可以创建 Spark DataFrame。以下是如何使用 Jupyter notebook 环境在 Python 中创建一个示例:
1. 初始化并创建 API 会话:
#Add pyspark to sys.path and initialize
import findspark
findspark.init()
#Load the DataFrame API session into Spark and create a session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2. 将玩具数据创建为字典列表:
#Generate toy data using a dictionary list
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]3. 使用createDataFrame函数创建 DataFrame并传递data列表:
#Create a DataFrame from the data list
df = spark.createDataFrame(data)4. 打印schema和table,查看创建的DataFrame:
#Print the schema and view the DataFrame in table format
df.printSchema()
df.show()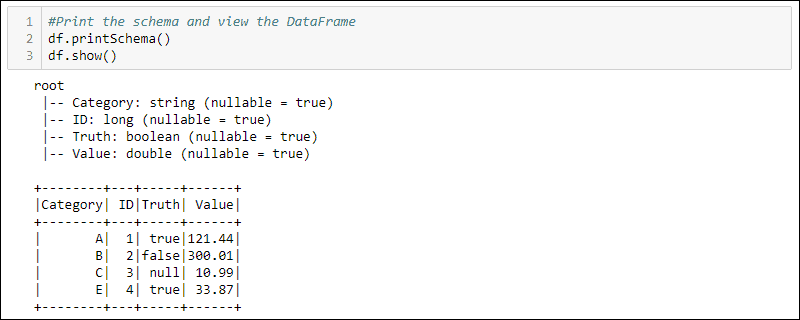
注意:有关分步教程,请阅读我们的文章如何创建 Spark DataFrame。
如何使用Spark DataFrame
DataFrame中存储的结构化数据提供了两种操作方法
- 使用领域特定语言
- 使用 SQL 查询。
接下来的两种方法使用上一个示例中的 DataFrame 来选择 Truth 列设置为 true 的所有行,并按 Value 列对数据进行排序。
方法 1:使用特定于域的查询
Python 提供了用于过滤和排序数据的内置方法。使用df.<column name>以下命令选择特定列:
df.filter(df.Truth == True).sort(df.Value).show()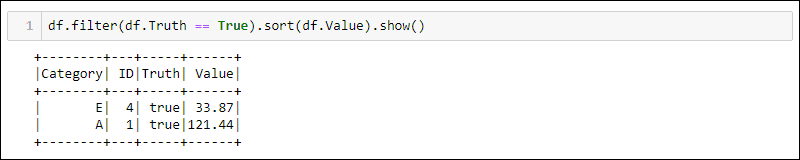
方法 2:使用 SQL 查询
要在 DataFrame 中使用 SQL 查询,请使用createOrReplaceTempView内置方法创建一个视图并使用以下spark.sql方法运行 SQL 查询:
df.createOrReplaceTempView('table')
spark.sql('''SELECT * FROM table WHERE Truth=true ORDER BY Value ASC''')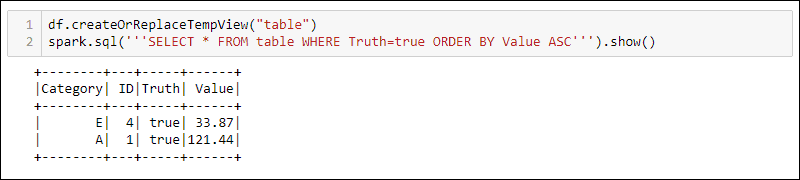
输出显示了应用于 DataFrame 临时视图的 SQL 查询结果。这允许对同一数据创建多个视图和查询以进行复杂的数据处理。
注意: DataFrames 和 SQL 操作是 Spark Streaming Operations 的一部分。在我们的Spark Streaming 初学者指南中了解更多信息。
结论
什么是Spark DataFrame?Spark 提供数据结构,用于使用 SQL 查询和 Java、Python 和 Scala 等编程语言处理大数据。阅读本文后,你将了解什么是 DataFrame 以及数据的结构。

