
介绍
Python缺失数据如何处理?在处理真实数据集时,缺失数据是一个常见问题。了解和分析缺失值的原因有助于更清晰地了解解决问题的步骤。Python 提供了很多方法来分析和解决数据未入账的问题。
Python如何处理缺失数据?本教程通过Python中的一个实际例子来解释缺失或缺失数据的原因和解决方法。
先决条件
- 安装并配置了 Python 3
- 安装的Pandas和NumPy模块
- 具有缺失值的数据集
注意:不确定机器上安装的是哪个版本的 Python?按照我们的教程查找:如何在 Linux、Mac 和 Windows 中检查 Python 版本。
缺失数据如何影响你的算法?
缺失数据会通过三种方式影响你的算法和研究:
- 缺失值提供了关于数据本身的错误想法,导致歧义。例如,计算一半信息不可用或设置为零的列的平均值会给出错误的度量。
- 当数据不可用时,某些算法不起作用。一些包含NaN(非数字)值的数据集的机器学习算法会引发错误。
- 缺失数据的模式是一个重要因素。如果某个数据集中的数据随机缺失,则该信息在大多数情况下仍然有用。但是,如果系统地缺少信息,则所有分析都是有偏见的。
什么会导致数据缺失?
数据缺失的原因取决于数据收集方法。确定原因有助于确定在分析数据集时采用的路径。
以下是为什么数据集缺少值的一些示例:
调查。通过调查收集的数据通常缺少信息。无论是出于隐私原因还是只是不知道特定问题的答案,调查问卷通常都缺少数据。
物联网。使用 IoT 设备并将数据从传感器系统收集到边缘计算服务器时会出现许多问题。暂时的通信中断或传感器故障通常会导致数据缺失。
限制访问。某些数据的访问权限有限,尤其是受HIPAA、GDPR和其他法规保护的数据。
手动错误。由于工作性质或信息量大,手动输入的数据通常存在不一致的情况。
如何处理缺失的数据?
为了分析和解释如何在 Python 中处理缺失数据的过程,我们将使用:
- 在旧金山营建许可数据集
- Jupyter 笔记本环境
这些想法适用于不同的数据集以及其他Python IDE 和编辑器。
导入和查看数据
Python如何处理缺失数据?下载数据集并复制文件路径。使用熊猫库,导入和存储的Building_Permits.csv数据到一个变量:
import pandas as pd
data = pd.read_csv('<path to Building_Permits.csv>')要确认正确导入的数据,请运行:
data.head()该命令以表格格式显示数据的前几行:
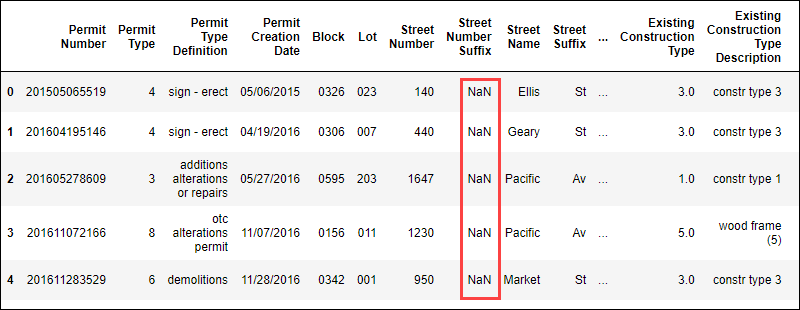
NaN值的存在表明此数据集中缺少数据。
查找缺失值
Python处理缺失数据的方法:通过运行查找每列有多少缺失值:
data.isnull().sum()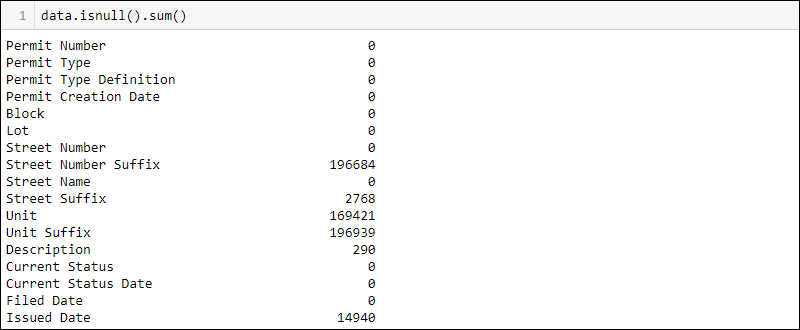
当以百分比显示时,数字提供了更多含义。要将总和显示为百分比,请将数字除以数据集的总长度:
data.isnull().sum()/len(data)要首先显示缺失数据百分比最高的列,请添加.sort_values(ascending=False)到上一行代码:
data.isnull().sum().sort_values(ascending = False)/len(data)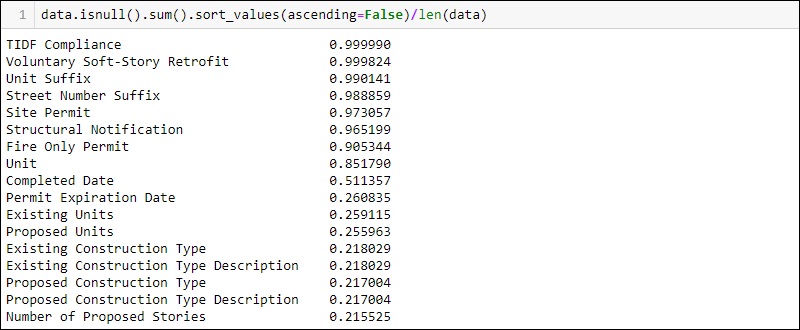
在删除或更改任何值之前,请检查文档以了解数据缺失的任何原因。例如,TIDF 合规性列几乎缺失了所有数据。但是,文档指出这是一项新的法律要求,因此缺少大多数值是有道理的。
标记缺失值
通过运行以下命令显示数据集的一般统计数据:
data.describe()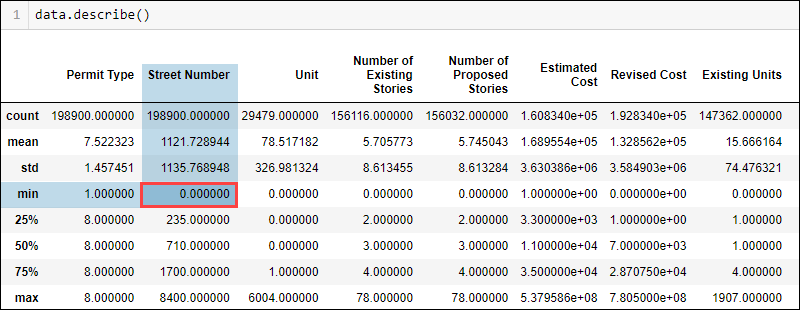
Python缺失数据如何处理?根据数据类型和领域知识,某些值在逻辑上不适合。例如,街道号码不能为零。但是,最小值显示为零,表示街道编号列中可能存在缺失值。
要查看有多少街道编号值为 0,请运行:
(data['Street Number'] == 0).sum()使用 NumPy 库,交换 NaN 的值以指示缺失的信息:
import numpy as np
data['Street Number'] = data['Street Number'].replace(0, np.nan)现在检查更新的统计数据表明最小街道编号为 1。
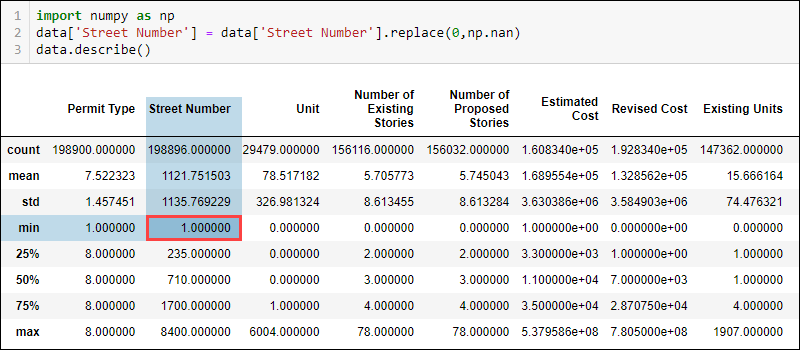
同样,NaN 值的总和现在显示街道编号列中缺少数据。
Street Number 列中的其他值也会发生变化,例如计数和平均值。由于只有少数值是 0,因此差异并不大。但是,随着错误标记数据的数量越来越多,指标的差异也更加明显。
删除缺失值
Python如何处理缺失数据?在 Python 中处理缺失值的最简单方法是删除存在缺失信息的行或列。
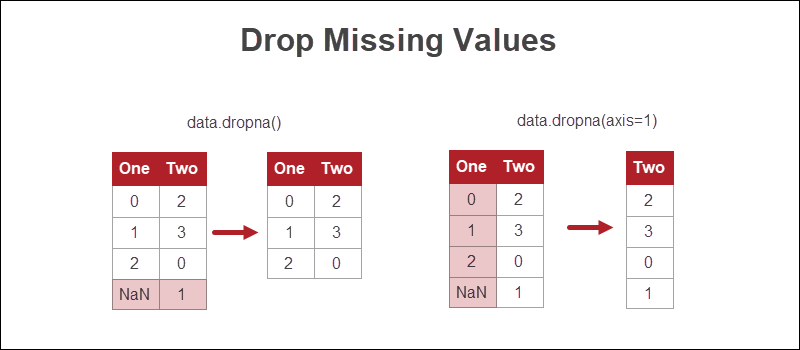
虽然这种方法是最快的,但缺失数据并不是最可行的选择。如果可能,最好采用其他方法。
删除缺失值的行
Python处理缺失数据的方法:要删除缺失值的行,请使用以下dropna函数:
data.dropna()当应用于示例数据集时,该函数删除了所有数据行,因为每行数据至少包含一个NaN 值。
删除缺失值的列
要删除具有缺失值的列,请使用该dropna函数并提供轴:
data.dropna(axis = 1)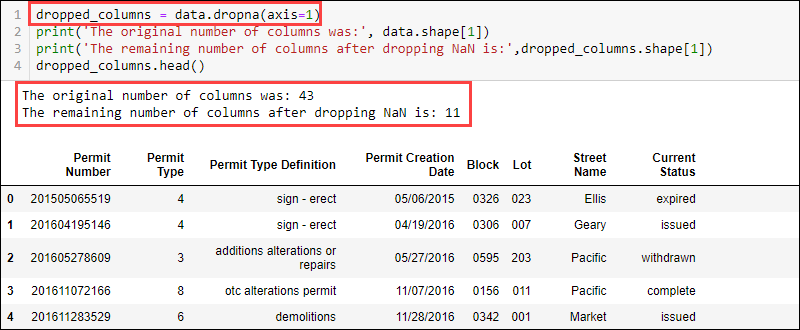
与最初可用的 43 列相比,数据集现在包含 11 列。
估算缺失值
Python如何处理缺失数据?插补是一种使用特定策略用数字填充缺失值的方法。考虑进行插补的一些选项是:
- 该列的平均值、中位数或众数。
- 一个不同的值,例如 0 或 -1。
- 从现有集合中随机选择的值。
- 使用预测模型估计的值。
Pandas DataFrame 模块提供了一种使用各种策略填充 NaN 值的方法。例如,要将所有 NaN 值替换为 0:
data.fillna(0)Python缺失数据如何处理?该fillna函数提供了用于替换缺失值的不同方法。回填是一种常用的方法,它用后面的任何值填充缺失的信息:
data.fillna(method = 'bfill')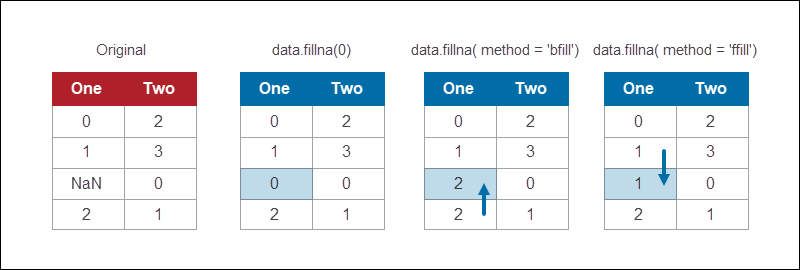
如果缺少最后一个值,则用所需的值填充所有剩余的 NaN。例如,要回填所有可能的值并用 0 填充剩余的值,请使用:
data.fillna(method = 'bfill', axis = 0).fillna(0)同样,使用ffill向前填充值。当数据具有逻辑顺序时,向前填充和向后填充方法都可以工作。
支持缺失值的算法
Python处理缺失数据的方法:有一些机器学习算法对缺失数据很稳健。一些例子包括:
- kNN(k-最近邻)
- 朴素贝叶斯
其他算法,例如分类或回归树,使用不可用信息作为唯一标识符。
注意:了解如何在 Python 中注释。注释对于在较长时间后调试和理解你自己的代码很有用。
结论
Python如何处理缺失数据?解决缺失值是数据科学和机器学习数据准备的重要组成部分。该过程需要一些领域知识和在每种情况下的正确决策。
要通过机器学习模型运行数据,请安装 Keras并尝试为数据集创建深度学习模型。

