
介绍
RDD vs DataFrame vs Dataset有什么区别?Apache Spark 提供了三种不同的 API 来处理大数据:RDD、Dataset、DataFrame。Spark 平台提供了在三种数据格式之间快速切换的功能。每个 API 都有优点,也有使用它们最有益的情况。
本文概述了 RDD 与 DataFrame 与 Dataset API 之间的主要区别及其功能。
RDD vs DataFrame vs Dataset比较差异汇总
下表概述了三个 Spark API 之间的显着区别:
| RDD | DataFrame | Dataset | |
|---|---|---|---|
| 发布版本 | Spark 1.0 | Spark 1.3 | Spark 1.6 |
| 数据表示 | 分布式元素集合。 | 组织成列的分布式数据集合。 | RDD 和 DataFrame 的组合。 |
| 数据格式 | 接受结构化和非结构化。 | 接受结构化和半结构化。 | 接受结构化和非结构化。 |
| 数据源 | 各种数据来源。 | 各种数据来源。 | 各种数据来源。 |
| 不变性和互操作性 | 可轻松转换为 DataFrame 的不可变分区。 | 转换为 DataFrame 会丢失原始 RDD。 | 原始RDD在转换后重新生成。 |
| 编译时类型安全 | 可用的编译时类型安全。 | 没有编译时类型安全。在运行时检测错误。 | 可用的编译时类型安全。 |
| 优化 | 没有内置的优化引擎。每个 RDD 都是单独优化的。 | 通过 Catalyst 优化器进行查询优化。 | 通过 Catalyst 优化器(如 DataFrames)进行查询优化。 |
| 序列化 | RDD 使用 Java 序列化来编码数据,并且成本很高。序列化需要在节点之间发送数据和结构。 | 不需要 Java 序列化和编码。序列化以二进制格式在内存中进行。 | Encoder 处理 JVM 对象和表之间的转换,这比 Java 序列化要快。 |
| 垃圾收集 | 创建和销毁单个对象会产生垃圾收集开销。 | 在创建或销毁对象时避免垃圾回收。 | 不需要垃圾收集 |
| 效率 | 单个对象序列化的效率降低。 | 内存中的序列化减少了开销。在不需要反序列化的情况下对序列化数据执行的操作。 | 无需反序列化整个对象即可访问单个属性。 |
| 懒惰评估 | 是的。 | 是的。 | 是的。 |
| 编程语言支持 | Java Scala Python R | Java Scala Python R | Java Scala |
| 图式投影 | 模式需要手动定义。 | 文件模式的自动发现。 | 文件模式的自动发现。 |
| 聚合 | 执行简单的聚合和分组操作困难、缓慢。 | 快速进行探索性分析。大型数据集的聚合统计数据是可能的,并且执行速度很快。 | 对大量数据集的快速聚合。 |
什么是RDD?
RDD vs DataFrame vs Dataset有什么区别?一个RDD(弹性分布式数据集)是Spark的表示一个不变的组跨集群节点分配元件,从而允许并行计算的基本抽象。数据结构可以包含任何 Java、Python、Scala 或用户创建的对象。
RDD 提供两种类型的操作:
1.转换以一个 RDD 作为输入,并产生一个或多个 RDD 作为输出。
2. Actions将一个 RDD 作为输入并产生一个已执行的操作作为输出。
低级 API 是对MapReduce局限性的回应。结果是迭代算法的延迟降低了几个数量级。这种改进对于机器学习训练算法尤其重要。
注意:查看我们关于Spark 与 Hadoop 的比较文章。
RDD 的优点
使用 RDD 的优点和有价值的特性是:
- 性能。将数据存储在内存中以及并行处理使 RDD 高效且快速。
- 一致性。RDD 的内容是不可变的,不可修改,提供数据稳定性。
- 容错。RDD 是有弹性的,如果节点发生故障,可以重新计算丢失或损坏的分区以进行完全恢复。
何时使用 RDD
在以下情况下使用 RDD:
- 数据是非结构化的。非结构化数据源(如媒体或文本流)受益于 RDD 提供的性能优势。
- 转换是低级的。当靠近数据源时,数据操作应该快速而直接。
- 架构并不重要。由于 RDD 不强加模式,因此在按列或属性访问特定数据不相关时使用它们。
什么是DataFrame和Dataset
Spark DataFrame 是一组不可变的对象,组织成列并分布在集群中的节点上。DataFrames 是 SparkSQL 数据抽象,类似于关系数据库表或Python Pandas DataFrames。
Dataset也是 SparkSQL 结构,代表DataFrame API 的扩展。Dataset API 结合了 DataFrames 的性能优化和 RDDs 的便利性。此外,API 更适合强类型语言。提供的类型安全和面向对象的编程接口使 Dataset API仅可用于 Java 和 Scala。
将DataFrame与Dataset合并
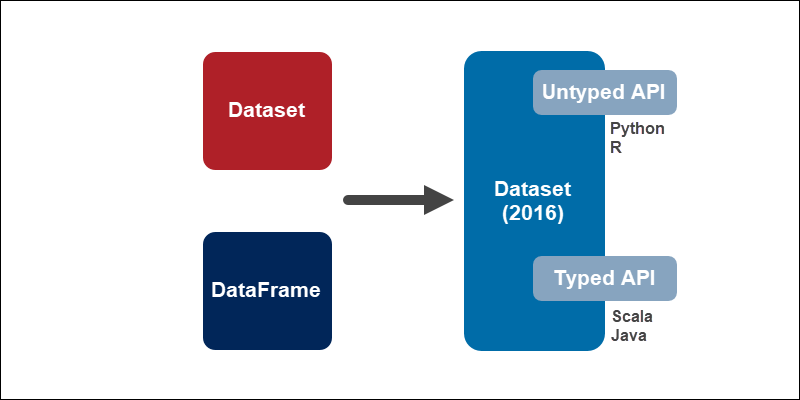
RDD vs DataFrame vs Dataset有什么区别?在 Spark 2.0 中,Dataset 和 DataFrame 合并为一个单元,以降低学习 Spark 的复杂度。Dataset API 有两种形式:
1.强类型API。Java 和 Scala 使用这个 API,其中 DataFrame 本质上是一个组织成列的Dataset。在幕后,DataFrame 是 Dataset JVM 对象的一行。
2.无类型 API。Python 和 R 使用无类型 API,因为它们是动态语言,因此Dataset不可用。但是,Dataset API 中提供的大部分好处已经在 DataFrame API 中可用。
Dataset的优势
使用Dataset的主要优点是:
- 富有成效的。编译时类型安全使Dataset对开发人员最有效。编译器会捕获大多数错误。但是,DataFrames 中不存在的列名在运行时检测。
- 易于使用。一组丰富的语义和高级函数使 Dataset API 易于使用。
- 快速和优化。Catalyst 代码优化器提供内存和速度效率。
何时使用Dataset
在以下情况下使用Dataset:
- 数据需要一个结构。DataFrames 推断结构化和半结构化数据的模式。
- 转换是高级别的。如果你的数据需要高级处理、列函数和SQL 查询,请使用 Datasets 和 DataFrames。
- 高度的类型安全是必要的。编译时类型安全充分利用了开发速度和效率。
注意:了解如何使用 PySpark 在 Python 中手动创建 Spark DataFrame。
RDD vs DataFrame vs Dataset比较总结
虽然 RDD 提供对数据的低级控制,但 Dataset 和 DataFrame API 带来了结构和高级抽象。请记住,从 RDD 到 Dataset 或 DataFrame 的转换很容易执行。
如需更多实践教程,请尝试我们的Spark Streaming 初学者指南,了解 RDD 和 DataFrame 如何协同工作以处理实时数据流。

