
Python如何使用Google Drive API?了解如何使用 Google Drive API 列出文件、搜索特定文件或文件类型、在 Python 中从/向 Google Drive 下载和上传文件。
如何在Python中使用Google Drive API?Google Drive 可让你将文件存储在云中,你可以随时随地访问。在本教程中,你将学习如何使用 Python 以编程方式列出 Google Drive文件、搜索它们、下载存储的文件,甚至将本地文件上传到Drive中。
这是目录:
- Python Google Drive API用法示例
- 启用Drive API
- 列出文件和目录
- 上传文件
- 搜索文件和目录
- 下载文件
首先,让我们安装本教程所需的库:
pip3 install google-api-python-client google-auth-httplib2 google-auth-oauthlib tabulate requests tqdm启用Drive API
启用 Google Drive API 与其他 Google API(例如Gmail API、YouTube API或Google Search Engine API)非常相似。首先,你需要有一个启用了 Google Drive 的 Google 帐户,前往此页面并单击“启用 Drive API”按钮,如下所示:

将弹出一个新窗口,选择你的应用程序类型,我将坚持使用“桌面应用程序”,然后点击“创建”按钮。之后,你会看到另一个窗口出现,说你已经准备好了:
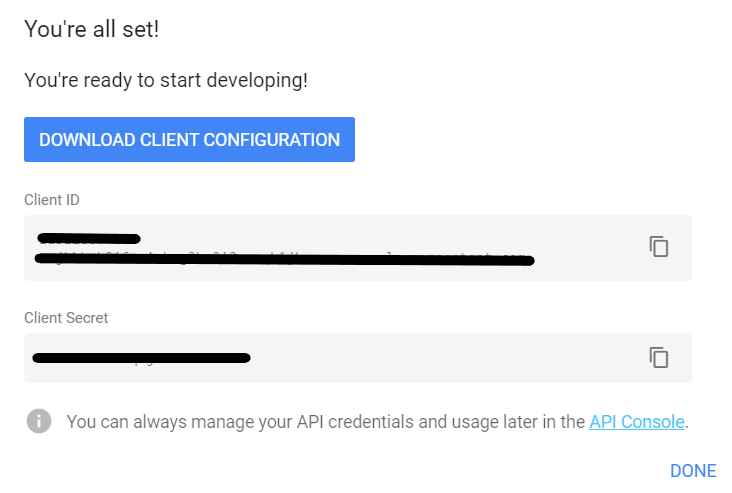
单击“下载客户端配置”按钮下载你的凭据,然后单击“完成”。
最后,你需要将credentials.json刚刚下载的文件放入你的工作目录(即你执行即将到来的 Python 脚本的位置)。
列出文件和目录
Python如何使用Google Drive API?在我们做任何事情之前,我们需要对我们的 Google 帐户验证我们的代码,以下函数执行此操作:
import pickle
import os
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from tabulate import tabulate
# If modifying these scopes, delete the file token.pickle.
SCOPES = ['https://www.googleapis.com/auth/drive.metadata.readonly']
def get_gdrive_service():
creds = None
# The file token.pickle stores the user's access and refresh tokens, and is
# created automatically when the authorization flow completes for the first
# time.
if os.path.exists('token.pickle'):
with open('token.pickle', 'rb') as token:
creds = pickle.load(token)
# If there are no (valid) credentials available, let the user log in.
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
# Save the credentials for the next run
with open('token.pickle', 'wb') as token:
pickle.dump(creds, token)
# return Google Drive API service
return build('drive', 'v3', credentials=creds)如何在Python中使用Google Drive API?我们已经导入了必要的模块,上面的功能是从Google Drive quickstart page 中抓取的。它基本上会查找token.pickle文件以使用你的 Google 帐户进行身份验证,如果没有找到,它将credentials.json用于提示你在浏览器中进行身份验证。之后,它将启动 Google Drive API 服务并返回它。
Python Google Drive API用法示例 - 转到 main 函数,让我们定义一个列出Drive中文件的函数:
def main():
"""Shows basic usage of the Drive v3 API.
Prints the names and ids of the first 5 files the user has access to.
"""
service = get_gdrive_service()
# Call the Drive v3 API
results = service.files().list(
pageSize=5, fields="nextPageToken, files(id, name, mimeType, size, parents, modifiedTime)").execute()
# get the results
items = results.get('files', [])
# list all 20 files & folders
list_files(items)因此,我们使用service.files().list()函数通过指定返回用户有权访问的前 5 个文件/文件夹pageSize=5,我们将一些有用的字段传递给fields参数以获取有关列出文件的详细信息,例如mimeType(文件类型),size以字节为单位,parent目录ID 和上次修改日期时间,请检查此页面以查看所有其他字段。
注意我们使用了list_files(items)函数,我们还没有定义这个函数。由于结果现在是一个字典列表,它不是那么可读,我们将项目传递给这个函数以便以人类可读的格式打印它们:
def list_files(items):
"""given items returned by Google Drive API, prints them in a tabular way"""
if not items:
# empty drive
print('No files found.')
else:
rows = []
for item in items:
# get the File ID
id = item["id"]
# get the name of file
name = item["name"]
try:
# parent directory ID
parents = item["parents"]
except:
# has no parrents
parents = "N/A"
try:
# get the size in nice bytes format (KB, MB, etc.)
size = get_size_format(int(item["size"]))
except:
# not a file, may be a folder
size = "N/A"
# get the Google Drive type of file
mime_type = item["mimeType"]
# get last modified date time
modified_time = item["modifiedTime"]
# append everything to the list
rows.append((id, name, parents, size, mime_type, modified_time))
print("Files:")
# convert to a human readable table
table = tabulate(rows, headers=["ID", "Name", "Parents", "Size", "Type", "Modified Time"])
# print the table
print(table)复制我们将字典项变量列表转换为元组行变量列表,然后将它们传递给我们之前安装的制表模块,以良好的格式打印它们,让我们调用main()函数:
if __name__ == '__main__':
main()查看我的输出:
Files:
ID Name Parents Size Type Modified Time
--------------------------------- ------------------------------ ----------------------- -------- ---------------------------- ------------------------
1FaD2BVO_ppps2BFm463JzKM-gGcEdWVT some_text.txt ['0AOEK-gp9UUuOUk9RVA'] 31.00B text/plain 2020-05-15T13:22:20.000Z
1vRRRh5OlXpb-vJtphPweCvoh7qYILJYi google-drive-512.png ['0AOEK-gp9UUuOUk9RVA'] 15.62KB image/png 2020-05-14T23:57:18.000Z
1wYY_5Fic8yt8KSy8nnQfjah9EfVRDoIE bbc.zip ['0AOEK-gp9UUuOUk9RVA'] 863.61KB application/x-zip-compressed 2019-08-19T09:52:22.000Z
1FX-KwO6EpCMQg9wtsitQ-JUqYduTWZub Nasdaq 100 Historical Data.csv ['0AOEK-gp9UUuOUk9RVA'] 363.10KB text/csv 2019-05-17T16:00:44.000Z
1shTHGozbqzzy9Rww9IAV5_CCzgPrO30R my_python_code.py ['0AOEK-gp9UUuOUk9RVA'] 1.92MB text/x-python 2019-05-13T14:21:10.000Z这些是我的 Google Drive 中的文件,注意Size列以字节为单位进行缩放,那是因为我们get_size_format()在list_files()函数中使用了函数,这是它的代码:
def get_size_format(b, factor=1024, suffix="B"):
"""
Scale bytes to its proper byte format
e.g:
1253656 => '1.20MB'
1253656678 => '1.17GB'
"""
for unit in ["", "K", "M", "G", "T", "P", "E", "Z"]:
if b < factor:
return f"{b:.2f}{unit}{suffix}"
b /= factor
return f"{b:.2f}Y{suffix}"上述函数应在运行该main()方法之前定义,否则会引发错误。为方便起见,请查看完整代码。请记住,在你运行脚本后,你将在默认浏览器中提示选择你的 Google 帐户并允许你的应用程序使用你之前指定的范围,别担心,这只会在你第一次运行时发生,然后token.pickle将被保存,并将从那里加载身份验证详细信息。
注意:有时你会在选择 Google 帐户后遇到“此应用程序未验证”警告(因为 Google 未验证你的应用程序),可以转到“高级”部分并允许应用程序访问你的帐户。
上传文件
Python如何使用Google Drive API?为了将文件上传到我们的 Google Drive,我们需要更改SCOPES我们之前指定的列表,我们需要添加添加文件/文件夹的权限:
from __future__ import print_function
import pickle
import os.path
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from googleapiclient.http import MediaFileUpload
# If modifying these scopes, delete the file token.pickle.
SCOPES = ['https://www.googleapis.com/auth/drive.metadata.readonly',
'https://www.googleapis.com/auth/drive.file']不同的范围意味着不同的权限,你需要删除token.pickle工作目录中的文件并再次运行代码以使用新范围进行身份验证。
我们将使用相同的get_gdrive_service()函数来验证我们的帐户,让我们创建一个函数来创建一个文件夹并将示例文件上传到其中:
def upload_files():
"""
Creates a folder and upload a file to it
"""
# authenticate account
service = get_gdrive_service()
# folder details we want to make
folder_metadata = {
"name": "TestFolder",
"mimeType": "application/vnd.google-apps.folder"
}
# create the folder
file = service.files().create(body=folder_metadata, fields="id").execute()
# get the folder id
folder_id = file.get("id")
print("Folder ID:", folder_id)
# upload a file text file
# first, define file metadata, such as the name and the parent folder ID
file_metadata = {
"name": "test.txt",
"parents": [folder_id]
}
# upload
media = MediaFileUpload("test.txt", resumable=True)
file = service.files().create(body=file_metadata, media_body=media, fields='id').execute()
print("File created, id:", file.get("id"))如何在Python中使用Google Drive API?我们使用service.files().create()方法来创建一个新文件夹,我们传递了folder_metadata具有我们要创建的文件夹的类型和名称的字典,我们传递fields="id"了检索文件夹 id 以便我们可以将文件上传到该文件夹中。
接下来,我们使用MediaFileUploadclass 上传示例文件并将其传递给相同的service.files().create()方法,确保你有一个名为 的测试文件test.txt,这次我们"parents"在元数据字典中指定了属性,我们只是将我们刚刚创建的文件夹放入。让我们运行它:
if __name__ == '__main__':
upload_files()运行代码后,在我的 Google Drive 中创建了一个新文件夹:
 我们使用文本文件进行演示,但你可以上传任何类型的文件。查看上传文件到 Google Drive的完整代码。
我们使用文本文件进行演示,但你可以上传任何类型的文件。查看上传文件到 Google Drive的完整代码。
Python Google Drive API用法示例:搜索文件和目录
Google Drive 使我们能够使用以前使用的list()方法只通过传递'q'参数来搜索文件和目录,以下函数接受 Drive API 服务和查询,并返回过滤的项目:
def search(service, query):
# search for the file
result = []
page_token = None
while True:
response = service.files().list(q=query,
spaces="drive",
fields="nextPageToken, files(id, name, mimeType)",
pageToken=page_token).execute()
# iterate over filtered files
for file in response.get("files", []):
result.append((file["id"], file["name"], file["mimeType"]))
page_token = response.get('nextPageToken', None)
if not page_token:
# no more files
break
return result让我们看看如何使用这个函数:
def main():
# filter to text files
filetype = "text/plain"
# authenticate Google Drive API
service = get_gdrive_service()
# search for files that has type of text/plain
search_result = search(service, query=f"mimeType='{filetype}'")
# convert to table to print well
table = tabulate(search_result, headers=["ID", "Name", "Type"])
print(table)所以我们在这里过滤text/plain文件,通过使用"mimeType='text/plain'"作为query参数,如果你想按名称过滤,你可以简单地"name='filename.ext'"用作查询参数。有关更多详细信息,请参阅Google Drive API 文档。
让我们执行这个:
if __name__ == '__main__':
main()复制输出:
ID Name Type
--------------------------------- ------------- ----------
15gdpNEYnZ8cvi3PhRjNTvW8mdfix9ojV test.txt text/plain
1FaE2BVO_rnps2BFm463JwPN-gGcDdWVT some_text.txt text/plain在此处查看完整代码。
相关: 如何在 Python 中使用 Gmail API。
下载文件
Python如何使用Google Drive API?现在要下载文件,我们需要先获取我们要下载的文件,我们可以使用前面的代码搜索它,也可以手动获取其Drive ID。在本节中,我们将按名称搜索文件并将其下载到我们的本地磁盘:
import pickle
import os
import re
import io
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from googleapiclient.http import MediaIoBaseDownload
import requests
from tqdm import tqdm
# If modifying these scopes, delete the file token.pickle.
SCOPES = ['https://www.googleapis.com/auth/drive.metadata',
'https://www.googleapis.com/auth/drive',
'https://www.googleapis.com/auth/drive.file'
]我在这里添加了 2 个范围,那是因为我们需要创建使文件可共享和可下载的权限,这是主要功能:
def download():
service = get_gdrive_service()
# the name of the file you want to download from Google Drive
filename = "bbc.zip"
# search for the file by name
search_result = search(service, query=f"name='{filename}'")
# get the GDrive ID of the file
file_id = search_result[0][0]
# make it shareable
service.permissions().create(body={"role": "reader", "type": "anyone"}, fileId=file_id).execute()
# download file
download_file_from_google_drive(file_id, filename)如何在Python中使用Google Drive API?你在之前的秘籍中看到了前三行,我们只需使用我们的 Google 帐户进行身份验证并搜索我们想要下载的所需文件。
之后,我们提取文件 ID 并创建允许我们下载文件的新权限,这与在 Google Drive 网络界面中创建可共享链接按钮相同。
最后,我们使用我们定义的download_file_from_google_drive()函数下载文件,你有它:
def download_file_from_google_drive(id, destination):
def get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def save_response_content(response, destination):
CHUNK_SIZE = 32768
# get the file size from Content-length response header
file_size = int(response.headers.get("Content-Length", 0))
# extract Content disposition from response headers
content_disposition = response.headers.get("content-disposition")
# parse filename
filename = re.findall("filename=\"(.+)\"", content_disposition)[0]
print("[+] File size:", file_size)
print("[+] File name:", filename)
progress = tqdm(response.iter_content(CHUNK_SIZE), f"Downloading {filename}", total=file_size, unit="Byte", unit_scale=True, unit_divisor=1024)
with open(destination, "wb") as f:
for chunk in progress:
if chunk: # filter out keep-alive new chunks
f.write(chunk)
# update the progress bar
progress.update(len(chunk))
progress.close()
# base URL for download
URL = "https://docs.google.com/uc?export=download"
# init a HTTP session
session = requests.Session()
# make a request
response = session.get(URL, params = {'id': id}, stream=True)
print("[+] Downloading", response.url)
# get confirmation token
token = get_confirm_token(response)
if token:
params = {'id': id, 'confirm':token}
response = session.get(URL, params=params, stream=True)
# download to disk
save_response_content(response, destination) 在以上Python Google Drive API用法示例中,我从下载文件教程中获取了上述代码的一部分,它只是GET向我们构造的目标 URL发出请求,session.get()方法是将文件 ID 作为参数传递给方法。
我已经使用tqdm打印进度条以查看它何时完成,这对于大文件来说会很方便。让我们执行它:
if __name__ == '__main__':
download()这将搜索bbc.zip文件,下载它并将其保存在你的工作目录中。检查完整代码。
结论
Python如何使用Google Drive API?好的,你知道了,这些基本上是 Google Drive 的核心功能,现在你知道如何在不手动单击鼠标的情况下在 Python 中完成它们!
请记住,每当你更改SCOPES列表时,你都需要删除token.pickle文件以使用新范围再次对你的帐户进行身份验证。有关更多信息以及范围列表及其解释,请参阅此页面。
随意编辑代码以接受文件名作为参数以下载或上传它们,通过引入argparse 模块来尝试使脚本尽可能动态以制作一些有用的脚本,让我们看看你构建了什么!

