
本文教你了解如何使用 Python 中的 YouTube API 提取 YouTube 数据,包括视频和频道详细信息、按关键字或频道搜索以及提取评论,其中包含一些Python提取YouTube数据示例。
YouTube 无疑是互联网上最大的视频共享网站。它是教育、娱乐、广告和更多领域的主要来源之一。由于它是一个数据丰富的网站,因此能够访问其 API 将使你能够获得几乎所有的 YouTube 数据。
Python如何提取YouTube数据?在本教程中,我们将介绍如何使用 YouTube API 和 Python 获取 YouTube 视频详细信息和统计信息、按关键字搜索、获取 YouTube 频道信息以及从视频和频道中提取评论。
如何使用YouTube API提取YouTube数据?这是本文的主要目录:
- 启用 YouTube API
- 获取视频详细信息
- 按关键字搜索
- 获取 YouTube 频道详细信息
- 提取 YouTube 评论
启用 YouTube API
要启用 YouTube 数据 API,你应该按照以下步骤操作:
- 转到 Google 的 API 控制台并创建一个项目,或使用现有的项目。
- 在 库面板中,搜索 YouTube Data API v3,单击它,然后单击启用。
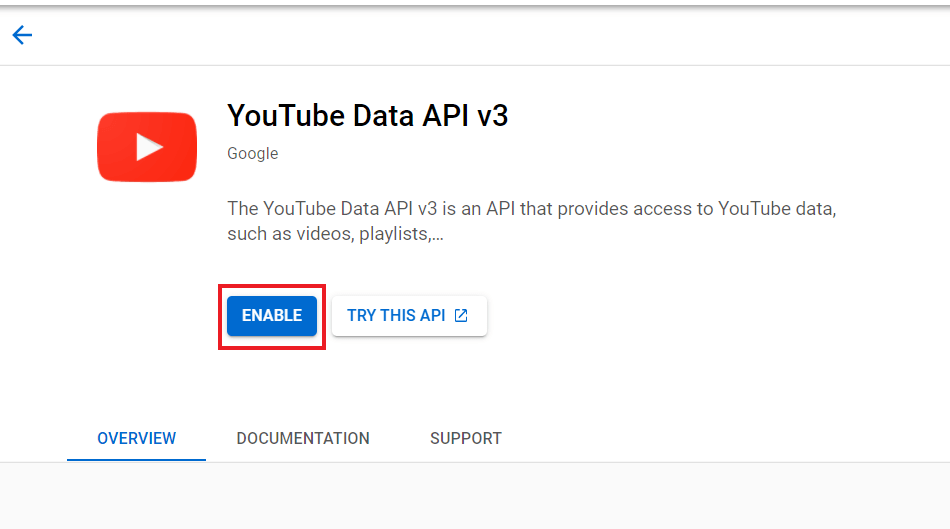
- 在 凭据面板中,单击 创建凭据,然后选择 OAuth 客户端 ID。
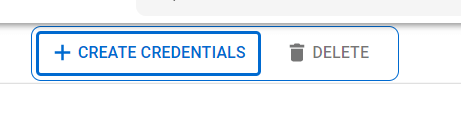
- 选择桌面应用程序作为应用程序类型并继续。
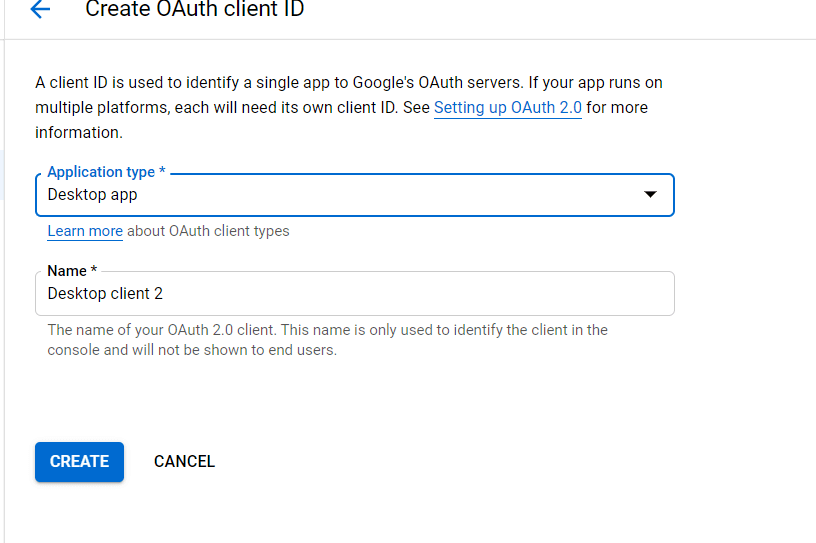
- 你会看到一个这样的窗口:
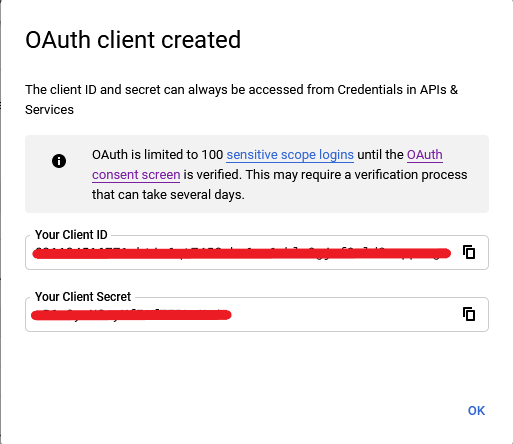
- 单击“ 确定”并下载凭据文件并将其重命名为
credentials.json:
注意: 如果这是你第一次使用 Google API,你可能只需要创建一个 OAuth 同意屏幕并将你的电子邮件添加为测试用户。
现在你已经设置了 YouTube API,在你的 notebook/Python 文件的当前目录中获取你的 credentials.json,让我们开始吧。
首先,安装所需的库:
$ pip3 install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib现在让我们导入我们需要的必要模块:
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
import urllib.parse as p
import re
import os
import pickle
SCOPES = ["https://www.googleapis.com/auth/youtube.force-ssl"]SCOPES 是使用 YouTube API 的范围列表,我们使用这个范围是为了能够毫无问题地查看所有 YouTube 数据。
Python提取YouTube数据示例 - 现在让我们制作使用 YouTube API 进行身份验证的函数:
def youtube_authenticate():
os.environ["OAUTHLIB_INSECURE_TRANSPORT"] = "1"
api_service_name = "youtube"
api_version = "v3"
client_secrets_file = "credentials.json"
creds = None
# the file token.pickle stores the user's access and refresh tokens, and is
# created automatically when the authorization flow completes for the first time
if os.path.exists("token.pickle"):
with open("token.pickle", "rb") as token:
creds = pickle.load(token)
# if there are no (valid) credentials availablle, let the user log in.
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(client_secrets_file, SCOPES)
creds = flow.run_local_server(port=0)
# save the credentials for the next run
with open("token.pickle", "wb") as token:
pickle.dump(creds, token)
return build(api_service_name, api_version, credentials=creds)
# authenticate to YouTube API
youtube = youtube_authenticate()youtube_authenticate()查找credentials.json 我们之前下载的文件,并尝试使用该文件进行身份验证,这将在你第一次运行时打开默认浏览器,因此你接受权限。之后,它将保存一个token.pickle 包含授权凭据的新文件 。
如果你之前使用过 Google API,例如Gmail API、 Google Drive API或其他东西,它应该看起来很熟悉 。默认浏览器中的提示是接受应用程序所需的权限,如果你看到一个窗口,表明该应用程序未经验证,你可能只想前往“ 高级” 并单击你的应用程序名称。
获取视频详细信息
Python如何提取YouTube数据?现在你已完成所有设置,让我们开始提取 YouTube 视频详细信息,例如标题、描述、上传时间,甚至统计数据,例如观看次数、喜欢次数和不喜欢次数。
以下函数将帮助我们从视频 URL 中提取视频 ID(我们将在 API 中需要):
def get_video_id_by_url(url):
"""
Return the Video ID from the video `url`
"""
# split URL parts
parsed_url = p.urlparse(url)
# get the video ID by parsing the query of the URL
video_id = p.parse_qs(parsed_url.query).get("v")
if video_id:
return video_id[0]
else:
raise Exception(f"Wasn't able to parse video URL: {url}")如何使用YouTube API提取YouTube数据?我们只是使用urllib.parse 模块从 URL 获取视频 ID。
下面的函数获取一个 YouTube 服务对象 (从youtube_authenticate() 函数返回 ),以及 API 接受的任何关键字参数,并返回特定视频的 API 响应:
def get_video_details(youtube, **kwargs):
return youtube.videos().list(
part="snippet,contentDetails,statistics",
**kwargs
).execute()请注意,我们指定了snippet、 contentDetails 和 的 部分 statistics,因为这些是 API 中响应的最重要部分。
我们也kwargs 直接传递 给API。接下来,让我们定义一个函数,该函数接受从上述get_video_details() 函数返回的响应 ,并打印视频中最有用的信息:
def print_video_infos(video_response):
items = video_response.get("items")[0]
# get the snippet, statistics & content details from the video response
snippet = items["snippet"]
statistics = items["statistics"]
content_details = items["contentDetails"]
# get infos from the snippet
channel_title = snippet["channelTitle"]
title = snippet["title"]
description = snippet["description"]
publish_time = snippet["publishedAt"]
# get stats infos
comment_count = statistics["commentCount"]
like_count = statistics["likeCount"]
dislike_count = statistics["dislikeCount"]
view_count = statistics["viewCount"]
# get duration from content details
duration = content_details["duration"]
# duration in the form of something like 'PT5H50M15S'
# parsing it to be something like '5:50:15'
parsed_duration = re.search(f"PT(\d+H)?(\d+M)?(\d+S)", duration).groups()
duration_str = ""
for d in parsed_duration:
if d:
duration_str += f"{d[:-1]}:"
duration_str = duration_str.strip(":")
print(f"""\
Title: {title}
Description: {description}
Channel Title: {channel_title}
Publish time: {publish_time}
Duration: {duration_str}
Number of comments: {comment_count}
Number of likes: {like_count}
Number of dislikes: {dislike_count}
Number of views: {view_count}
""")最后,让我们使用这些函数从演示视频中提取信息:
video_url = "https://www.youtube.com/watch?v=jNQXAC9IVRw&ab_channel=jawed"
# parse video ID from URL
video_id = get_video_id_by_url(video_url)
# make API call to get video info
response = get_video_details(youtube, id=video_id)
# print extracted video infos
print_video_infos(response)我们首先从 URL 中获取视频 ID,然后从 API 调用中获取响应,最后打印数据,输出如下:
Title: Me at the zoo
Description: The first video on YouTube. Maybe it's time to go back to the zoo?
Channel Title: jawed
Publish time: 2005-04-24T03:31:52Z
Duration: 19
Number of comments: 11018071
Number of likes: 5962957
Number of dislikes: 153444
Number of views: 138108884你会看到我们使用 id 参数来获取特定视频的详细信息,你也可以使用相同的 get_video_details() 函数通过传递myRating="like" 或 myRating="dislike" 代替 来获取你喜欢/不喜欢的视频 id=video_id。
你还可以设置多个以逗号分隔的视频 ID,因此你可以通过单个 API 调用来获取有关多个视频的 详细信息,请查看 文档以获取更多详细信息。
按关键字搜索
Python提取YouTube数据示例:使用 YouTube API 进行搜索很简单,我们只需q为查询传递 参数,与我们在 YouTube 搜索栏中使用的查询相同:
def search(youtube, **kwargs):
return youtube.search().list(
part="snippet",
**kwargs
).execute()如何使用YouTube API提取YouTube数据?这次我们关心的是代码片段,我们在之前定义的 函数中使用 search() 了videos()like代替 get_video_details()。
例如,让我们搜索 "python" 并将结果限制为仅 2 个:
# search for the query 'python' and retrieve 2 items only
response = search(youtube, q="python", maxResults=2)
items = response.get("items")
for item in items:
# get the video ID
video_id = item["id"]["videoId"]
# get the video details
video_response = get_video_details(youtube, id=video_id)
# print the video details
print_video_infos(video_response)
print("="*50)我们设置 maxResults 为 2,因此我们检索前两项,这是输出的一部分:
Title: Learn Python - Full Course for Beginners [Tutorial]
Description: This course will give you a full introduction into all of the core concepts in python...<SNIPPED>
Channel Title: freeCodeCamp.org
Publish time: 2018-07-11T18:00:42Z
Duration: 4:26:52
Number of comments: 30307
Number of likes: 520260
Number of dislikes: 5676
Number of views: 21032973
==================================================
Title: Python Tutorial - Python for Beginners [Full Course]
Description: Python tutorial - Python for beginners
Learn Python programming for a career in machine learning, data science & web development...<SNIPPED>
Channel Title: Programming with Mosh
Publish time: 2019-02-18T15:00:08Z
Duration: 6:14:7
Number of comments: 38019
Number of likes: 479749
Number of dislikes: 3756
Number of views: 15575418你还可以order 在search() function 中指定 参数 对搜索结果进行排序,可以是 'date'、 'rating'、 'viewCount'、 'relevance' (默认) 'title'、 和 'videoCount'。另一个有用的参数是 type,它可以是 'channel', 'playlist' 或者 'video',默认为所有的人。
请查看 此页面以获取有关该search().list() 方法的更多信息。
获取 YouTube 频道详细信息
Python如何提取YouTube数据?在本节中,我们将获取频道 URL 并使用 YouTube API 提取频道信息。
首先,我们需要帮助函数来解析频道 URL,下面的函数将帮助我们做到这一点:
def parse_channel_url(url):
"""
This function takes channel `url` to check whether it includes a
channel ID, user ID or channel name
"""
path = p.urlparse(url).path
id = path.split("/")[-1]
if "/c/" in path:
return "c", id
elif "/channel/" in path:
return "channel", id
elif "/user/" in path:
return "user", id
def get_channel_id_by_url(youtube, url):
"""
Returns channel ID of a given `id` and `method`
- `method` (str): can be 'c', 'channel', 'user'
- `id` (str): if method is 'c', then `id` is display name
if method is 'channel', then it's channel id
if method is 'user', then it's username
"""
# parse the channel URL
method, id = parse_channel_url(url)
if method == "channel":
# if it's a channel ID, then just return it
return id
elif method == "user":
# if it's a user ID, make a request to get the channel ID
response = get_channel_details(youtube, forUsername=id)
items = response.get("items")
if items:
channel_id = items[0].get("id")
return channel_id
elif method == "c":
# if it's a channel name, search for the channel using the name
# may be inaccurate
response = search(youtube, q=id, maxResults=1)
items = response.get("items")
if items:
channel_id = items[0]["snippet"]["channelId"]
return channel_id
raise Exception(f"Cannot find ID:{id} with {method} method")现在我们可以解析频道 URL,让我们定义调用 YouTube API 的函数:
def get_channel_videos(youtube, **kwargs):
return youtube.search().list(
**kwargs
).execute()
def get_channel_details(youtube, **kwargs):
return youtube.channels().list(
part="statistics,snippet,contentDetails",
**kwargs
).execute()我们将 get_channel_videos() 用于获取特定频道的视频,并 get_channel_details() 允许我们提取有关特定 YouTube 频道的信息。
现在我们拥有了一切,让我们举一个具体的例子:
channel_url = "https://www.youtube.com/channel/UC8butISFwT-Wl7EV0hUK0BQ"
# get the channel ID from the URL
channel_id = get_channel_id_by_url(youtube, channel_url)
# get the channel details
response = get_channel_details(youtube, id=channel_id)
# extract channel infos
snippet = response["items"][0]["snippet"]
statistics = response["items"][0]["statistics"]
channel_country = snippet["country"]
channel_description = snippet["description"]
channel_creation_date = snippet["publishedAt"]
channel_title = snippet["title"]
channel_subscriber_count = statistics["subscriberCount"]
channel_video_count = statistics["videoCount"]
channel_view_count = statistics["viewCount"]
print(f"""
Title: {channel_title}
Published At: {channel_creation_date}
Description: {channel_description}
Country: {channel_country}
Number of videos: {channel_video_count}
Number of subscribers: {channel_subscriber_count}
Total views: {channel_view_count}
""")
# the following is grabbing channel videos
# number of pages you want to get
n_pages = 2
# counting number of videos grabbed
n_videos = 0
next_page_token = None
for i in range(n_pages):
params = {
'part': 'snippet',
'q': '',
'channelId': channel_id,
'type': 'video',
}
if next_page_token:
params['pageToken'] = next_page_token
res = get_channel_videos(youtube, **params)
channel_videos = res.get("items")
for video in channel_videos:
n_videos += 1
video_id = video["id"]["videoId"]
# easily construct video URL by its ID
video_url = f"https://www.youtube.com/watch?v={video_id}"
video_response = get_video_details(youtube, id=video_id)
print(f"================Video #{n_videos}================")
# print the video details
print_video_infos(video_response)
print(f"Video URL: {video_url}")
print("="*40)
print("*"*100)
# if there is a next page, then add it to our parameters
# to proceed to the next page
if "nextPageToken" in res:
next_page_token = res["nextPageToken"]在以上Python提取YouTube数据示例中,我们首先从 URL 中获取频道 ID,然后我们进行 API 调用以获取频道详细信息并打印它们。
之后,我们指定要提取的视频页数。默认为每页 10 个视频,我们也可以通过传递maxResults 参数来更改它 。
我们对每个视频进行迭代并进行 API 调用以获取有关视频的各种信息,并使用我们的预定义 print_video_infos() 来打印视频信息。
这是输出的一部分:
================Video #1================
Title: Async + Await in JavaScript, talk from Wes Bos
Description: Flow Control in JavaScript is hard! ...
Channel Title: freeCodeCamp.org
Publish time: 2018-04-16T16:58:08Z
Duration: 15:52
Number of comments: 52
Number of likes: 2353
Number of dislikes: 28
Number of views: 74562
Video URL: https://www.youtube.com/watch?v=DwQJ_NPQWWo
========================================
================Video #2================
Title: Protected Routes in React using React Router
Description: In this video, we will create a protected route using...
Channel Title: freeCodeCamp.org
Publish time: 2018-10-16T16:00:05Z
Duration: 15:40
Number of comments: 158
Number of likes: 3331
Number of dislikes: 65
Number of views: 173927
Video URL: https://www.youtube.com/watch?v=Y0-qdp-XBJg
...<SNIPPED>你还可以获得其他信息,你可以打印response 字典以获取更多信息,或查看 此端点的文档。
Python如何提取YouTube数据?提取 YouTube 评论
YouTube API 也允许我们提取评论,如果你想为你的文本分类项目或类似项目获取评论,这将非常有用。下面的函数负责对 进行 API 调用 commentThreads():
def get_comments(youtube, **kwargs):
return youtube.commentThreads().list(
part="snippet",
**kwargs
).execute()以下代码从 YouTube 视频中提取评论:
# URL can be a channel or a video, to extract comments
url = "https://www.youtube.com/watch?v=jNQXAC9IVRw&ab_channel=jawed"
if "watch" in url:
# that's a video
video_id = get_video_id_by_url(url)
params = {
'videoId': video_id,
'maxResults': 2,
'order': 'relevance', # default is 'time' (newest)
}
else:
# should be a channel
channel_id = get_channel_id_by_url(url)
params = {
'allThreadsRelatedToChannelId': channel_id,
'maxResults': 2,
'order': 'relevance', # default is 'time' (newest)
}
# get the first 2 pages (2 API requests)
n_pages = 2
for i in range(n_pages):
# make API call to get all comments from the channel (including posts & videos)
response = get_comments(youtube, **params)
items = response.get("items")
# if items is empty, breakout of the loop
if not items:
break
for item in items:
comment = item["snippet"]["topLevelComment"]["snippet"]["textDisplay"]
updated_at = item["snippet"]["topLevelComment"]["snippet"]["updatedAt"]
like_count = item["snippet"]["topLevelComment"]["snippet"]["likeCount"]
comment_id = item["snippet"]["topLevelComment"]["id"]
print(f"""\
Comment: {comment}
Likes: {like_count}
Updated At: {updated_at}
==================================\
""")
if "nextPageToken" in response:
# if there is a next page
# add next page token to the params we pass to the function
params["pageToken"] = response["nextPageToken"]
else:
# must be end of comments!!!!
break
print("*"*70)你还可以将url 变量更改 为 YouTube 频道 URL,因此它将allThreadsRelatedToChannelId 而不是 videoId 作为参数传递 给 commentThreads() API。
Python提取YouTube数据示例 - 我们每页提取 2 条评论和 2 页,所以总共 4 条评论,这是输出:
Comment: We're so honored that the first ever YouTube video was filmed here!
Likes: 877965
Updated At: 2020-02-17T18:58:15Z
==================================
Comment: Wow, still in your recommended in 2021? Nice! Yay
Likes: 10951
Updated At: 2021-01-04T15:32:38Z
==================================
**********************************************************************
Comment: How many are seeing this video now
Likes: 7134
Updated At: 2021-01-03T19:47:25Z
==================================
Comment: The first youtube video EVER. Wow.
Likes: 865
Updated At: 2021-01-05T00:55:35Z
==================================
**********************************************************************如何使用YouTube API提取YouTube数据?我们正在提取评论本身、点赞数和上次更新日期,你可以浏览回复字典以获取各种其他有用信息。
你可以自由编辑我们传递的参数,例如增加maxResults,或更改 order. 请检查 此 API 端点的页面。
结论
Python如何提取YouTube数据?YouTube 数据 API 提供的内容比我们在此处介绍的要多得多,如果你有 YouTube 频道,那么你可以上传、更新和删除视频等等。
我邀请你在YouTube API 文档中探索更多 有关高级搜索技术、获取播放列表详细信息、成员等的信息。
如果你想提取 YouTube 数据但不想使用 API,那么我们还有一个关于如何通过网络抓取获取 YouTube 数据的教程 (更像是一种非官方的方法)。

