
Python如何提取YouTube评论?本文了解如何在浏览器中监控网络流量以编写 Python 脚本,该脚本使用 Python 中的请求库提取 YouTube 评论。
能够从互联网上最大的视频共享网站提取评论是一个方便的工具,你可以提取评论来执行文本分类等任务,或者你可能想要提取YouTube视频的评论来执行某些任务,可能性是无止境。
如何在Python中提取YouTube评论?在本教程中,包含了一个完整的Python提取YouTube评论示例,我们不仅会编写一个 Python 脚本来提取 YouTube 评论,还会尝试使用浏览器开发工具中的网络实用程序来捕获正确的评论请求,从而帮助我们编写代码。
注意:如果本教程的代码不适合你,请改用YouTube API 教程查看。
相关: 如何在 Python 中提取 YouTube 数据。
在我们开始之前,让我们安装需求:
pip3 install requests在浏览器中监控网络流量
Python如何提取YouTube评论?现在,为了跟随我,使用 Chrome 或任何其他浏览器进入你选择的任何 YouTube 视频,然后右键单击并选择检查元素并转到网络部分:
 注意我
注意我"comment"在过滤器输入字段中写的,这将帮助我们过滤掉不需要的 HTTP 请求,例如图像、样式和 Javascript 文件等。
现在转到视频页面并向下滚动,直到看到一些评论已加载。如果你返回到网络工具,你将看到如下内容:
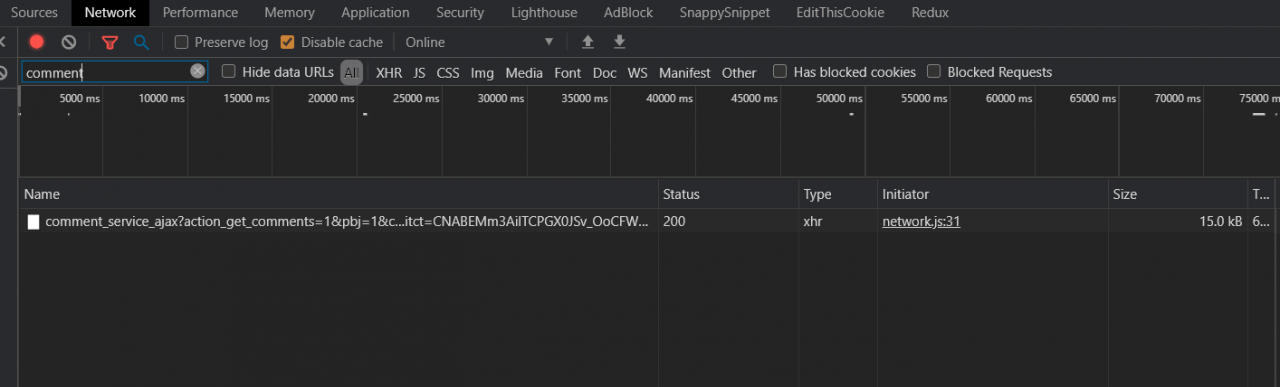
太好了,我们已经成功捕获了一个评论请求,如果你点击它,你会看到实际的请求 URL、方法和远程 IP 地址:
 到目前为止很好,记住这里的目标是在 Python 中模拟这个 HTTP 请求,但由于这是一个 POST 请求,我们需要更多的细节,比如 POST 正文和 URL 参数。
到目前为止很好,记住这里的目标是在 Python 中模拟这个 HTTP 请求,但由于这是一个 POST 请求,我们需要更多的细节,比如 POST 正文和 URL 参数。
Python提取YouTube评论示例介绍 - 如果我们向下滚动到同一部分 ( Headers)的底部,我们将看到查询字符串参数和表单数据,如下所示:
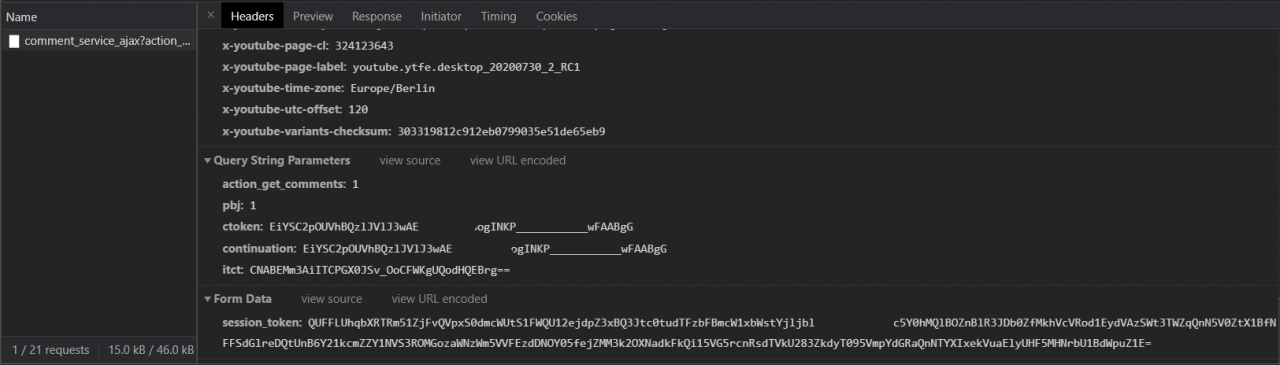 太棒了,所以我们需要
太棒了,所以我们需要action_get_comments, pbj, ctoken, continuation,itct和session_token参数。注意action_get_comments和pbj参数的值应为1,ctoken和continuation具有相同的值。在下一节中,我们将看到如何使用 Python 从 YouTube 视频页面源代码中提取它们。
此外,如果你继续向下滚动以加载更多评论,你会看到类似的请求被添加到请求列表中:
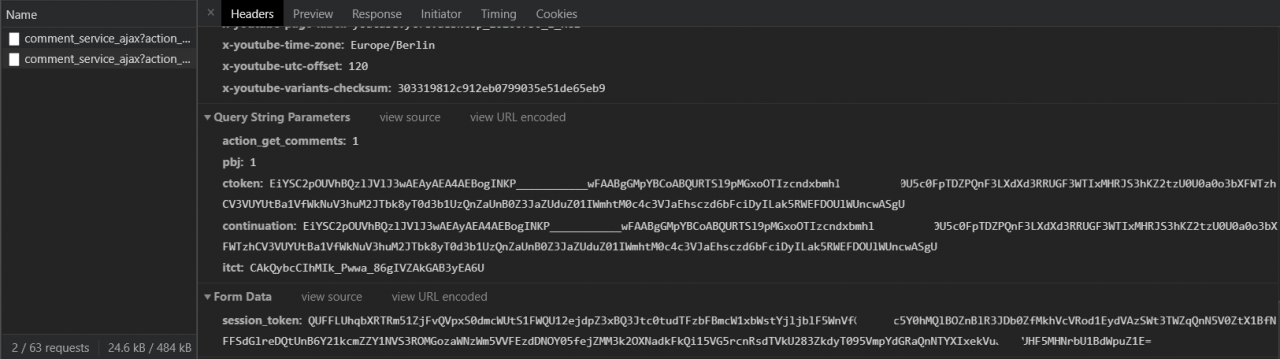 请注意,某些参数会在每个评论加载请求上更改其值。别担心,我们将在下一节中处理。
请注意,某些参数会在每个评论加载请求上更改其值。别担心,我们将在下一节中处理。
用 Python 编写注释提取器
现在我们了解了评论加载请求是如何发出的,让我们尝试在 Python 中模拟它,导入必要的模块:
import requests
import json
import time由于我们需要从视频页面的内容中解析一些数据(上一节中看到的参数),我们不会使用 HTML 解析器,例如BeautifulSoup,这是因为大部分数据都存在于script标签内的 Javascript 对象中. 因此,以下两个函数将帮助我们搜索内容:
# from https://github.com/egbertbouman/youtube-comment-downloader
def search_dict(partial, key):
"""
A handy function that searches for a specific `key` in a `partial` dictionary/list
"""
if isinstance(partial, dict):
for k, v in partial.items():
if k == key:
# found the key, return the value
yield v
else:
# value of the dict may be another dict, so we search there again
for o in search_dict(v, key):
yield o
elif isinstance(partial, list):
# if the passed data is a list
# iterate over it & search for the key at the items in the list
for i in partial:
for o in search_dict(i, key):
yield o
# from https://github.com/egbertbouman/youtube-comment-downloader
def find_value(html, key, num_sep_chars=2, separator='"'):
# define the start position by the position of the key +
# length of key + separator length (usually : and ")
start_pos = html.find(key) + len(key) + num_sep_chars
# the end position is the position of the separator (such as ")
# starting from the start_pos
end_pos = html.find(separator, start_pos)
# return the content in this range
return html[start_pos:end_pos]如何在Python中提取YouTube评论?现在不要试图理解它们,它们会在令牌提取过程中帮助我们。现在让我们定义我们的核心函数,它接受一个 YouTube 视频 URL 并以字典列表的形式返回评论:
def get_comments(url):
session = requests.Session()
# make the request
res = session.get(url)res 有 YouTube 视频网页的 HTTP 响应,现在让我们从返回的 HTML 内容中获取会话令牌:
# extract the XSRF token
xsrf_token = find_value(res.text, "XSRF_TOKEN", num_sep_chars=3)XSRF 令牌是session_token请求中表单数据所需的令牌,如果你查看视频页面的页面源并搜索它,你会在那里找到它:
![]() 太好了,让我们继续提取其他字段,即
太好了,让我们继续提取其他字段,即ctoken和itct。
Python如何提取YouTube评论?下面一行负责提取包含我们需要的所有数据的 Javascript 对象:
# parse the YouTube initial data in the <script> tag
data_str = find_value(res.text, 'window["ytInitialData"] = ', num_sep_chars=0, separator="\n").rstrip(";")
# convert to Python dictionary instead of plain text string
data = json.loads(data_str)这是它在页面源中的外观:

Python提取YouTube评论示例介绍:现在data是一个包含所有 YouTube 视频数据的常规 Python 字典,现在我们需要搜索nextContinuationData具有所需参数的字典:
# search for the ctoken & continuation parameter fields
for r in search_dict(data, "itemSectionRenderer"):
pagination_data = next(search_dict(r, "nextContinuationData"))
if pagination_data:
# if we got something, break out of the loop,
# we have the data we need
break
continuation_tokens = [(pagination_data['continuation'], pagination_data['clickTrackingParams'])]回到页面源代码,这是我们要搜索的内容:
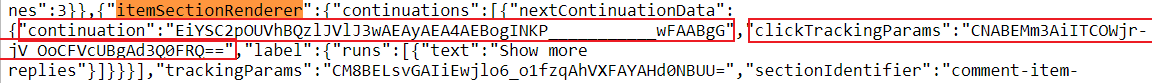 所以我们对
所以我们对continuation字段 ( ctoken) 和clickTrackingParams( itct)感兴趣
其余代码请求/comment_service_ajax获取和解析评论并在我们发出每个请求后收集继续令牌,直到没有更多评论:
while continuation_tokens:
# keep looping until continuation tokens list is empty (no more comments)
continuation, itct = continuation_tokens.pop()
# construct params parameter (the ones in the URL)
params = {
"action_get_comments": 1,
"pbj": 1,
"ctoken": continuation,
"continuation": continuation,
"itct": itct,
}
# construct POST body data, which consists of the XSRF token
data = {
"session_token": xsrf_token,
}
# construct request headers
headers = {
"x-youtube-client-name": "1",
"x-youtube-client-version": "2.20200731.02.01"
}
# make the POST request to get the comments data
response = session.post("https://www.youtube.com/comment_service_ajax", params=params, data=data, headers=headers)
# convert to a Python dictionary
comments_data = json.loads(response.text)
for comment in search_dict(comments_data, "commentRenderer"):
# iterate over loaded comments and yield useful info
yield {
"commentId": comment["commentId"],
"text": ''.join([c['text'] for c in comment['contentText']['runs']]),
"time": comment['publishedTimeText']['runs'][0]['text'],
"isLiked": comment["isLiked"],
"likeCount": comment["likeCount"],
# "replyCount": comment["replyCount"],
'author': comment.get('authorText', {}).get('simpleText', ''),
'channel': comment['authorEndpoint']['browseEndpoint']['browseId'],
'votes': comment.get('voteCount', {}).get('simpleText', '0'),
'photo': comment['authorThumbnail']['thumbnails'][-1]['url'],
"authorIsChannelOwner": comment["authorIsChannelOwner"],
}
# load continuation tokens for next comments (ctoken & itct)
continuation_tokens = [(next_cdata['continuation'], next_cdata['clickTrackingParams'])
for next_cdata in search_dict(comments_data, 'nextContinuationData')] + continuation_tokens
# avoid heavy loads with popular videos
time.sleep(0.1)完美,让我们测试一下:
if __name__ == "__main__":
from pprint import pprint
url = "https://www.youtube.com/watch?v=jNQXAC9IVRw"
for count, comment in enumerate(get_comments(url)):
if count == 3:
break
pprint(comment)
print("="*50)这将提取前 3 条评论并打印出来:
{'author': 'wizard yt',
'authorIsChannelOwner': False,
'channel': 'UCNg8yS4kYFvvkOQFIwR5NqA',
'commentId': 'UgwiWPPBdLMwnBSCPwJ4AaABAg',
'isLiked': False,
'likeCount': 0,
'photo': 'https://yt3.ggpht.com/a/AATXAJyyoOqaBjwEGRqKzuykxNosYd76Tmj-AFUcgAzB=s48-c-k-c0xffffffff-no-rj-mo',
'text': 'Sub2sub pls i request you i want 50 subs',
'time': '2 seconds ago',
'votes': '0'}
==================================================
{'author': 'Abdou Rockikz',
'authorIsChannelOwner': False,
'channel': 'UCA4FBhVyVNMO5LcRfJKwrEA',
'commentId': 'UgzzD6ngnIFkLX_lnsx4AaABAg',
'isLiked': False,
'likeCount': 0,
'photo': 'https://yt3.ggpht.com/a/AATXAJxXbUQXU551ZKsiQ2t_DF-4yLmvG-YrDnmArCuNZw=s48-c-k-c0xffffffff-no-rj-mo',
'text': 'This is a fake comment',
'time': '4 seconds ago',
'votes': '0'}
==================================================
{'author': 'NIGHT Devil',
'authorIsChannelOwner': False,
'channel': 'UCA4FBhVyVNMO5LcRfJKwrEA',
'commentId': 'UgxbTzFsW9wrD8qvuxJ4AaABAg',
'isLiked': False,
'likeCount': 0,
'photo': 'https://yt3.ggpht.com/a/AATXAJxXbUQXU551ZKsiQ2t_DF-4yLmvG-YrDnmArCuNZw=s48-c-k-c0xffffffff-no-rj-mo',
'text': 'CLICK <hidden> for a video',
'time': '6 seconds ago',
'votes': '0'}如何在Python中提取YouTube评论?最后,让我们使用argparsemodule 将其转换为任何人都可以使用的命令行工具:
if __name__ == "__main__":
import argparse
import os
parser = argparse.ArgumentParser(description="Simple YouTube Comment extractor")
parser.add_argument("url", help="The YouTube video full URL")
parser.add_argument("-l", "--limit", type=int, help="Number of maximum comments to extract, helpful for longer videos")
parser.add_argument("-o", "--output", help="Output JSON file, e.g data.json")
# parse passed arguments
args = parser.parse_args()
limit = args.limit
output = args.output
url = args.url
from pprint import pprint
for count, comment in enumerate(get_comments(url)):
if limit and count >= limit:
# break out of the loop when we exceed limit specified
break
if output:
# write comment as JSON to a file
with open(output, "a") as f:
# begin writing, adding an opening brackets
if count == 0:
f.write("[")
f.write(json.dumps(comment, ensure_ascii=False) + ",")
else:
pprint(comment)
print("="*50)
print("total comments extracted:", count)
if output:
# remove the last comma ','
with open(output, "rb+") as f:
f.seek(-1, os.SEEK_END)
f.truncate()
# add "]" to close the list in the end of the file
with open(output, "a") as f:
print("]", file=f)Python如何提取YouTube评论?这是一个命令行工具,它接受 YouTube 视频 URL 作为必需参数,-l或者--limit限制要提取的评论数量和/-o或--output指定将在其中写入评论的输出文件JSON,这是一个示例运行:
$ python youtube_comment_extractor.py https://www.youtube.com/watch?v=jNQXAC9IVRw --limit 50 --output comments50.json这将从该视频中提取50 条评论并将它们写入comments50.json文件。
注意: 如果本教程的代码不适合你,请改用YouTube API 教程查看 。
总结
通过完成本Python提取YouTube评论示例教程,你能够制作一个简单的 YouTube 评论提取器脚本。不过需要注意的是,本教程的一部分代码来自这个存储库。
如果你想下载更多的评论,我请你做手动或使用进度条tqdm库,这样做运气好!
在此处查看完整代码。

