
Python如何构建垃圾邮件分类器?这里学习在 Python 中使用 Keras 和 TensorFlow 使用 GloVe 嵌入向量和 RNN/LSTM 单元对电子邮件(垃圾邮件或非垃圾邮件)进行分类。
Keras和TensorFlow构建垃圾邮件分类器:电子邮件垃圾邮件或垃圾邮件是通过电子邮件发送的未经请求、不可避免且重复的消息。自 1990 年代初以来,垃圾邮件一直在增长,到 2014 年,据估计它占发送的电子邮件消息的 90% 左右。
由于我们都有垃圾邮件填满收件箱的问题,在本教程中,通过结合Python垃圾邮件分类器示例,我们将在Keras中构建一个模型,可以区分垃圾邮件和合法电子邮件。
表中的内容:
- 安装和导入依赖
- 加载数据集
- 准备数据集
- 构建模型
- 训练模型
- 评估模型
一、安装导入依赖
我们首先需要安装一些依赖:
pip3 install sklearn tqdm numpy tensorflow现在打开一个交互式 shell 或 Jupyter notebook 并导入:
import time
import pickle
import tensorflow as tf
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
# only use GPU memory that we need, not allocate all the GPU memory
tf.config.experimental.set_memory_growth(gpus[0], enable=True)
import tqdm
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Embedding, LSTM, Dropout, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.metrics import Recall, Precision让我们定义一些超参数:
SEQUENCE_LENGTH = 100 # the length of all sequences (number of words per sample)
EMBEDDING_SIZE = 100 # Using 100-Dimensional GloVe embedding vectors
TEST_SIZE = 0.25 # ratio of testing set
BATCH_SIZE = 64
EPOCHS = 10 # number of epochs
label2int = {"ham": 0, "spam": 1}
int2label = {0: "ham", 1: "spam"}如果你不确定这些参数的含义,请不要担心,我们稍后会在构建模型时讨论它们。
2. 加载数据集
Python如何构建垃圾邮件分类器?我们要使用的数据集是SMS Spam Collection Dataset,下载、提取并将其放在名为“data”的文件夹中,让我们定义加载它的函数:
def load_data():
"""
Loads SMS Spam Collection dataset
"""
texts, labels = [], []
with open("data/SMSSpamCollection") as f:
for line in f:
split = line.split()
labels.append(split[0].strip())
texts.append(' '.join(split[1:]).strip())
return texts, labels数据集在一个文件中,每一行对应一个数据样本,第一个词是标签,其余是实际的电子邮件内容,这就是为什么我们将标签抓取为split[0],将内容抓取为split[1: ]。
调用函数:
# load the data
X, y = load_data()3. 准备数据集
Keras和TensorFlow构建垃圾邮件分类器:现在,我们需要一种通过将每个文本转换为整数序列来向量化文本语料库的方法,你现在可能想知道为什么我们需要将文本转换为整数序列。好吧,记住我们要将文本输入到神经网络中,神经网络只能理解数字。更准确地说,是一个固定长度的整数序列。
但在我们做这一切之前,我们需要通过删除标点符号、小写所有字符等来清理这个语料库。 对我们来说幸运的是,Keras 有一个Tokenizer来自tensorflow.keras.preprocessing.text模块的内置类,它在几行代码中完成所有这些:
# Text tokenization
# vectorizing text, turning each text into sequence of integers
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X)
# lets dump it to a file, so we can use it in testing
pickle.dump(tokenizer, open("results/tokenizer.pickle", "wb"))
# convert to sequence of integers
X = tokenizer.texts_to_sequences(X)让我们尝试打印第一个样本:
In [4]: print(X[0])
[49, 472, 4436, 843, 756, 659, 64, 8, 1328, 87, 123, 352, 1329, 148, 2996, 1330, 67, 58, 4437, 144]Python垃圾邮件分类器示例:复制一堆数字,每个整数对应词汇表中的一个词,这正是神经网络所需要的。然而,样本没有相同的长度,我们需要一种方法来拥有一个固定长度的序列。
因此,我们使用模块中的pad_sequences()函数tensorflow.keras.preprocessing.sequence在每个序列的开头用零填充序列:
# convert to numpy arrays
X = np.array(X)
y = np.array(y)
# pad sequences at the beginning of each sequence with 0's
# for example if SEQUENCE_LENGTH=4:
# [[5, 3, 2], [5, 1, 2, 3], [3, 4]]
# will be transformed to:
# [[0, 5, 3, 2], [5, 1, 2, 3], [0, 0, 3, 4]]
X = pad_sequences(X, maxlen=SEQUENCE_LENGTH)你可能还记得,我们设置SEQUENCE_LENGTH为 100,这样,所有序列的长度都是 100。让我们打印每个句子如何转换为:
In [6]: print(X[0])
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 49 471 4435 842
755 658 64 8 1327 88 123 351 1328 148 2996 1329 67 58
4436 144]现在我们的标签也是文本,但我们将在这里采用不同的方法,因为标签只是"spam"和"ham",我们需要对它们进行单热编码:
# One Hot encoding labels
# [spam, ham, spam, ham, ham] will be converted to:
# [1, 0, 1, 0, 1] and then to:
# [[0, 1], [1, 0], [0, 1], [1, 0], [0, 1]]
y = [ label2int[label] for label in y ]
y = to_categorical(y)复制我们keras.utils.to_categorial()在这里使用,正如它的名字所暗示的那样,让我们尝试打印标签的第一个样本:
In [7]: print(y[0])
[1.0, 0.0]这意味着第一个样品是火腿。
接下来,让我们对训练和测试数据进行混洗和拆分:
# split and shuffle
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=7)
# print our data shapes
print("X_train.shape:", X_train.shape)
print("X_test.shape:", X_test.shape)
print("y_train.shape:", y_train.shape)
print("y_test.shape:", y_test.shape)细胞输出:
X_train.shape: (4180, 100)
X_test.shape: (1394, 100)
y_train.shape: (4180, 2)
y_test.shape: (1394, 2)如你所见,我们总共有 4180 个训练样本和 1494 个验证样本。
4. 建立模型
Python如何构建垃圾邮件分类器?现在我们已经准备好构建我们的模型了,一般架构如下图所示:
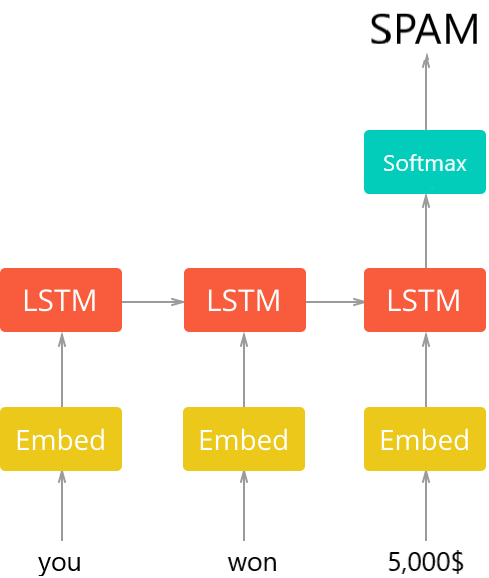 第一层是一个预训练的嵌入层,它将每个词映射到一个 N 维实数向量(EMBEDDING_SIZE对应于这个向量的大小,在本例中为 100)。具有相似含义的两个词往往具有非常接近的向量。
第一层是一个预训练的嵌入层,它将每个词映射到一个 N 维实数向量(EMBEDDING_SIZE对应于这个向量的大小,在本例中为 100)。具有相似含义的两个词往往具有非常接近的向量。
Keras和TensorFlow构建垃圾邮件分类器 - 第二层是带有LSTM单元的循环神经网络。最后,输出层是 2 个神经元,每个神经元对应于具有softmax激活函数的“垃圾邮件”或“火腿”。
让我们首先编写一个函数来加载预训练的嵌入向量:
def get_embedding_vectors(tokenizer, dim=100):
embedding_index = {}
with open(f"data/glove.6B.{dim}d.txt", encoding='utf8') as f:
for line in tqdm.tqdm(f, "Reading GloVe"):
values = line.split()
word = values[0]
vectors = np.asarray(values[1:], dtype='float32')
embedding_index[word] = vectors
word_index = tokenizer.word_index
embedding_matrix = np.zeros((len(word_index)+1, dim))
for word, i in word_index.items():
embedding_vector = embedding_index.get(word)
if embedding_vector is not None:
# words not found will be 0s
embedding_matrix[i] = embedding_vector
return embedding_matrix注意:为了正确运行此功能,你需要下载GloVe,解压并放入“data”文件夹,这里我们将使用 100 维向量。
让我们定义构建模型的函数:
def get_model(tokenizer, lstm_units):
"""
Constructs the model,
Embedding vectors => LSTM => 2 output Fully-Connected neurons with softmax activation
"""
# get the GloVe embedding vectors
embedding_matrix = get_embedding_vectors(tokenizer)
model = Sequential()
model.add(Embedding(len(tokenizer.word_index)+1,
EMBEDDING_SIZE,
weights=[embedding_matrix],
trainable=False,
input_length=SEQUENCE_LENGTH))
model.add(LSTM(lstm_units, recurrent_dropout=0.2))
model.add(Dropout(0.3))
model.add(Dense(2, activation="softmax"))
# compile as rmsprop optimizer
# aswell as with recall metric
model.compile(optimizer="rmsprop", loss="categorical_crossentropy",
metrics=["accuracy", keras_metrics.precision(), keras_metrics.recall()])
model.summary()
return model上述函数构建了整个模型,我们将预训练的嵌入向量加载到Embedding层中,并设置trainable=False,这将在训练过程中冻结嵌入权重。
添加 RNN 层后,我们添加了 30% 的 dropout 机会,这将在每次迭代中冻结前一层中 30% 的神经元,这将有助于我们减少过拟合。
请注意,准确性不足以确定模型是否做得很好,这是因为此数据集不平衡,只有少数样本是垃圾邮件。因此,我们将使用精度和召回指标。让我们调用函数:
# constructs the model with 128 LSTM units
model = get_model(tokenizer=tokenizer, lstm_units=128)5. 训练模型
Python垃圾邮件分类器示例:我们快到了,我们需要用刚刚加载的数据训练这个模型:
# initialize our ModelCheckpoint and TensorBoard callbacks
# model checkpoint for saving best weights
model_checkpoint = ModelCheckpoint("results/spam_classifier_{val_loss:.2f}.h5", save_best_only=True,
verbose=1)
# for better visualization
tensorboard = TensorBoard(f"logs/spam_classifier_{time.time()}")
# train the model
model.fit(X_train, y_train, validation_data=(X_test, y_test),
batch_size=BATCH_SIZE, epochs=EPOCHS,
callbacks=[tensorboard, model_checkpoint],
verbose=1)训练已经开始:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 100, 100) 901300
_________________________________________________________________
lstm_1 (LSTM) (None, 128) 117248
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 1,018,806
Trainable params: 117,506
Non-trainable params: 901,300
_________________________________________________________________
Train on 4180 samples, validate on 1394 samples
Epoch 1/10
66/66 [==============================] - 86s 1s/step - loss: 0.2315 - accuracy: 0.8980 - precision: 0.8980 - recall: 0.8980 - val_loss: 0.1192 - val_accuracy: 0.9555 - val_precision: 0.9555 - val_recall: 0.9555
Epoch 00001: val_loss improved from inf to 0.11920, saving model to results\spam_classifier_0.12.h5
Epoch 2/10
66/66 [==============================] - 87s 1s/step - loss: 0.0824 - accuracy: 0.9726 - precision: 0.9726 - recall: 0.9726 - val_loss: 0.0769 - val_accuracy: 0.9749 - val_precision: 0.9749 - val_recall: 0.9749
Epoch 00002: val_loss improved from 0.11920 to 0.07687, saving model to results\spam_classifier_0.08.h5培训结束:
Epoch 10/10
66/66 [==============================] - 89s 1s/step - loss: 0.0216 - accuracy: 0.9932 - precision: 0.9932 - recall: 0.9932 - val_loss: 0.0546 - val_accuracy: 0.9842 - val_precision: 0.9842 - val_recall: 0.9842
Epoch 00010: val_loss improved from 0.06224 to 0.05463, saving model to results\spam_classifier_0.05.h56. 评估模型
Python如何构建垃圾邮件分类器?让我们评估我们的模型:
# get the loss and metrics
result = model.evaluate(X_test, y_test)
# extract those
loss = result[0]
accuracy = result[1]
precision = result[2]
recall = result[3]
print(f"[+] Accuracy: {accuracy*100:.2f}%")
print(f"[+] Precision: {precision*100:.2f}%")
print(f"[+] Recall: {recall*100:.2f}%")输出:
1394/1394 [==============================] - 1s 569us/step
[+] Accuracy: 98.21%
[+] Precision: 99.16%
[+] Recall: 98.75%以下是每个指标的含义:
- 准确度:正确预测的百分比。
- 召回:正确预测的垃圾邮件的百分比。
- 精确度:归类为垃圾邮件的电子邮件实际上是垃圾邮件的百分比。
很好!让我们测试一下:
def get_predictions(text):
sequence = tokenizer.texts_to_sequences([text])
# pad the sequence
sequence = pad_sequences(sequence, maxlen=SEQUENCE_LENGTH)
# get the prediction
prediction = model.predict(sequence)[0]
# one-hot encoded vector, revert using np.argmax
return int2label[np.argmax(prediction)]让我们伪造垃圾邮件:
text = "You won a prize of 1,000$, click here to claim!"
get_predictions(text)输出:
spam好的,让我们尝试合法:
text = "Hi man, I was wondering if we can meet tomorrow."
print(get_predictions(text))输出:
ham惊人的!这种方法是目前最先进的,尝试调整训练和模型参数,看看是否可以改进。
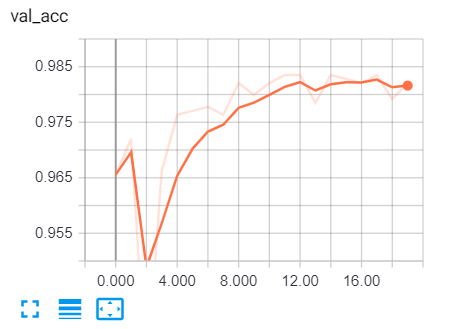
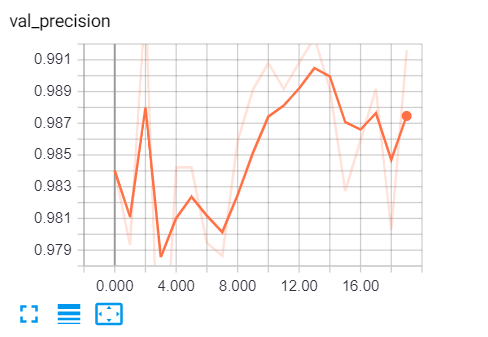
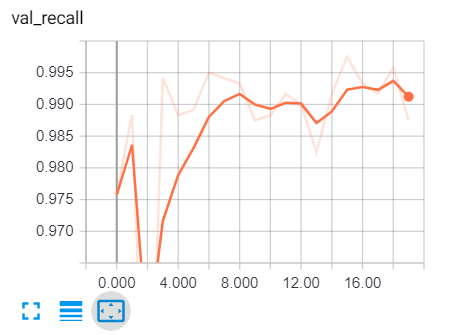
要在训练期间查看各种指标,我们需要通过键入 cmd 或终端来转到 tensorboard:
tensorboard --logdir="logs"Keras和TensorFlow构建垃圾邮件分类器:转到浏览器并输入“localhost:6006”并转到各种指标,这是我的结果:
以下是一些进一步的阅读:

