
使用 Tensorflow 2 和 Python 中的 Keras 库构建和训练一个模型,该模型对使用 Tensorflow 数据集加载的 CIFAR-10 数据集图像进行分类,该数据集由飞机、狗、猫和其他 7 个对象组成。
Tensorflow 2和Keras制作图像分类器:图像分类是指计算机视觉中可以根据图像的视觉内容对图像进行分类的过程。例如,可以设计图像分类算法来判断图像是否包含猫或狗。虽然检测对象对人类来说是微不足道的,但稳健的图像分类仍然是计算机视觉应用中的一个挑战。
Python如何制作图像分类器?在本教程中,你将学习如何CIFAR-10使用 Python 中的 Tensorflow成功地对数据集(由飞机、狗、猫和其他 7 个对象组成)中的图像进行分类。
Python图像分类器示例 - 请注意,图像分类和对象检测之间存在差异,图像分类是将图像分类为某个类别,例如在此示例中,输入是图像,输出是单个类别标签(10 个类别)。目标检测是关于检测、分类和定位现实世界图像中的目标,主要算法之一是YOLO 目标检测。
我们将预处理图像和标签,然后在所有训练样本上训练卷积神经网络。图像需要标准化,标签需要单热编码。
首先,让我们安装这个项目的要求:
pip3 install numpy matplotlib tensorflow==2.0.0 tensorflow_datasets例如,打开一个空的 python 文件并将其命名为 train.py并继续。导入张量流:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import TensorBoard
import tensorflow as tf
import tensorflow_datasets as tfds
import os正如你所料,我们将使用tf.data API来加载CIFAR-10数据集。
超参数
我尝试了各种参数,发现这是最佳参数:
# hyper-parameters
batch_size = 64
# 10 categories of images (CIFAR-10)
num_classes = 10
# number of training epochs
epochs = 30Python图像分类器示例:num_classes只是指要分类的类别数,在这种情况下,CIFAR-10只有 10 个类别的图像。
了解和加载 CIFAR-10 数据集
- 数据集由 10 类图像组成,其标签从 0 到 9:
- 0:飞机。
- 1:汽车。
- 2:鸟。
- 3:猫。
- 4:鹿。
- 5:狗。
- 6:青蛙。
- 7:马。
- 8:船。
- 9:卡车。
- 训练数据50000个样本,测试数据10000个样本。
- 每个样本是一个32x32x3像素的图像(宽度和高度为32和3深度,即 RGB 值)。
让我们加载这个:
def load_data():
"""
This function loads CIFAR-10 dataset, and preprocess it
"""
def preprocess_image(image, label):
# convert [0, 255] range integers to [0, 1] range floats
image = tf.image.convert_image_dtype(image, tf.float32)
return image, label
# loading the CIFAR-10 dataset, splitted between train and test sets
ds_train, info = tfds.load("cifar10", with_info=True, split="train", as_supervised=True)
ds_test = tfds.load("cifar10", split="test", as_supervised=True)
# repeat dataset forever, shuffle, preprocess, split by batch
ds_train = ds_train.repeat().shuffle(1024).map(preprocess_image).batch(batch_size)
ds_test = ds_test.repeat().shuffle(1024).map(preprocess_image).batch(batch_size)
return ds_train, ds_test, infoPython如何制作图像分类器?Tensorflow 2和Keras制作图像分类器:此函数使用Tensorflow Datasets模块加载数据集,我们设置with_info为True以获取有关此数据集的一些信息,你可以将其打印出来并查看不同的字段及其值,我们将使用该信息来获取数据集的数量训练集和测试集的样本。
之后,我们:
- 使用repeat()方法永远重复数据集,这将使我们能够重复生成数据样本(我们将在训练阶段指定停止条件)。
- 洗牌吧。
- 将图像归一化为 0 和 1 之间,这将有助于神经网络更快地训练,我们使用了map()方法,该方法接受一个以图像和标签为参数的回调函数,我们简单地使用了内置的 Tensorflow 的convert_image_dtype ()方法来做到这一点。
- 最后,我们使用batch()函数按64 个样本对数据集进行批处理,因此每次生成新数据点时,它将返回64 个图像及其64 个标签。
构建模型
将使用以下模型:
def create_model(input_shape):
# building the model
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same", input_shape=input_shape))
model.add(Activation("relu"))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# flattening the convolutions
model.add(Flatten())
# fully-connected layer
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation="softmax"))
# print the summary of the model architecture
model.summary()
# training the model using adam optimizer
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model复制这是 2 个 ConvNet 的 3 层,具有最大池化和 ReLU 激活函数,然后与1024 个单元完全连接。与最先进的 ResNet50或Xception相比,这是一个相对较小的模型。如果你觉得使用深度学习专家制作的模型,则需要使用迁移学习。
Python图像分类器示例:训练模型
现在,让我们训练模型:
if __name__ == "__main__":
# load the data
ds_train, ds_test, info = load_data()
# constructs the model
model = create_model(input_shape=info.features["image"].shape)
# some nice callbacks
logdir = os.path.join("logs", "cifar10-model-v1")
tensorboard = TensorBoard(log_dir=logdir)
# make sure results folder exist
if not os.path.isdir("results"):
os.mkdir("results")
# train
model.fit(ds_train, epochs=epochs, validation_data=ds_test, verbose=1,
steps_per_epoch=info.splits["train"].num_examples // batch_size,
validation_steps=info.splits["test"].num_examples // batch_size,
callbacks=[tensorboard])
# save the model to disk
model.save("results/cifar10-model-v1.h5")加载数据并创建模型后,我使用了Tensorboard,它将跟踪每个时期的准确性和损失,并为我们提供很好的可视化效果。
Tensorflow 2和Keras制作图像分类器:我们将使用“results”文件夹来保存我们的模型,如果你不确定如何在 Python 中处理文件和目录,请查看本教程。由于ds_trainandds_test会重复分批生成数据样本,我们需要指定每个epoch的步数,也就是样本数除以batch size,对于forvalidation_steps也是一样。
运行此命令,完成训练需要几分钟时间,具体取决于你的 CPU/GPU。
你会得到类似的结果:
Epoch 1/30
781/781 [==============================] - 20s 26ms/step - loss: 1.6503 - accuracy: 0.3905 - val_loss: 1.2835 - val_accuracy: 0.5238
Epoch 2/30
781/781 [==============================] - 16s 21ms/step - loss: 1.1847 - accuracy: 0.5750 - val_loss: 0.9773 - val_accuracy: 0.6542一直到最后一个纪元:
Epoch 29/30
781/781 [==============================] - 16s 21ms/step - loss: 0.4094 - accuracy: 0.8570 - val_loss: 0.5954 - val_accuracy: 0.8089
Epoch 30/30
781/781 [==============================] - 16s 21ms/step - loss: 0.4130 - accuracy: 0.8563 - val_loss: 0.6128 - val_accuracy: 0.8060现在要打开 tensorboard,你需要做的就是在终端或当前目录的命令提示符中键入此命令:
tensorboard --logdir="logs"复制打开浏览器选项卡并输入localhost:6006,你将被重定向到 tensorboard,这是我的结果:
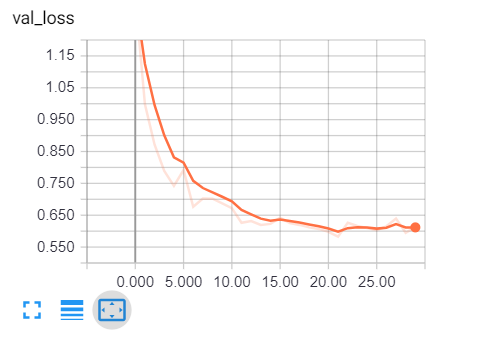
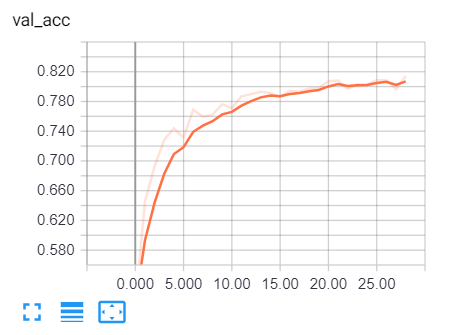
显然,我们走在正确的轨道上,验证损失正在减少,准确率一直增加到81% 左右。那太棒了!
测试模型
训练完成后,它会将最终模型和权重保存在结果文件夹中,这样我们就可以只训练一次并随时进行预测。打开一个名为test.py的新 python 文件并继续。
导入必要的实用程序:
from train import load_data, batch_size
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
import numpy as np让我们制作一个 Python 字典,将每个整数值映射到数据集中对应的标签:
# CIFAR-10 classes
categories = {
0: "airplane",
1: "automobile",
2: "bird",
3: "cat",
4: "deer",
5: "dog",
6: "frog",
7: "horse",
8: "ship",
9: "truck"
}加载测试数据和模型:
# load the testing set
ds_train, ds_test, info = load_data()
# load the model with final model weights
model = load_model("results/cifar10-model-v1.h5")评估:
# evaluation
loss, accuracy = model.evaluate(X_test, y_test)
print("Test accuracy:", accuracy*100, "%")Python如何制作图像分类器?复制让我们随机拍摄一张图片并进行预测:
# get prediction for this image
data_sample = next(iter(ds_test))
sample_image = data_sample[0].numpy()[0]
sample_label = categories[data_sample[1].numpy()[0]]
prediction = np.argmax(model.predict(sample_image.reshape(-1, *sample_image.shape))[0])
print("Predicted label:", categories[prediction])
print("True label:", sample_label)Python图像分类器示例:我们曾经next(iter(ds_test))获取下一个测试批次,然后提取该批次中的第一个图像和标签并对模型进行预测,结果如下:
156/156 [==============================] - 3s 20ms/step - loss: 0.6119 - accuracy: 0.8063
Test accuracy: 80.62900900840759 %
Predicted label: frog
True label: frog模型说它是一只青蛙,让我们检查一下:
# show the image
plt.axis('off')
plt.imshow(sample_image)
plt.show()结果:小青蛙!模型是对的!
Tensorflow 2和Keras制作图像分类器结论
好吧,我们正在与本教程完成的,81%是不坏的这个小CNN,我强烈建议你调整模型或检查ResNet50 , Xception,或国家的最先进的其他车型,以得到更高的性能!
如果你不确定如何使用这些模型,我有一个关于此的教程:如何使用迁移学习在Python中使用Keras进行图像分类。
你可能想知道这些图像如此简单,32x32网格不是现实世界的样子,图像也不是那么简单,它们通常包含许多对象、复杂的图案等等。因此,通常的做法是在传递到任何分类技术之前使用图像分割方法,例如轮廓检测或K-Means 聚类分割。

