
在 Python 中使用 Tensorflow 和 Keras 为不同的文本分类问题(例如情感分析或 20 个新闻组分类)构建深度学习模型(使用嵌入和循环层)。
Python使用Tensorflow 2和Keras实现文本分类 - 文本分类是监督机器学习中重要且常见的任务之一。它是关于为文档、文章、书籍、评论、推文或任何涉及文本的内容分配一个类别(一个类)。它是自然语言处理的核心任务。
许多应用程序似乎使用文本分类作为主要任务,示例包括垃圾邮件过滤、情感分析、语音标记、语言检测等等。
Python如何实现文本分类?在本教程中,我们将使用 Python 中的 Tensorflow 使用 RNN 构建文本分类器模型,我们将使用IMDB 评论数据集,其中包含5 万条真实世界的电影评论及其情绪(正面或负面)。在本教程的最后,我将向你展示如何集成你自己的数据集,以便你可以在其上训练模型。
尽管我们使用的是情感分析数据集,但本教程旨在对任何任务执行文本分类,如果你希望立即执行情感分析,请查看本教程。
如果你希望使用最先进的转换器模型,例如 BERT,请查看本教程,我们为自定义数据集微调 BERT。
Python文本分类示例 - 首先,你需要安装以下库:
pip3 install tqdm numpy tensorflow==2.0.0 sklearn现在打开一个新的 Python 笔记本或文件并继续,让我们导入我们需要的模块:
from tqdm import tqdm
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Dense, Dropout, LSTM, Embedding, Bidirectional
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import TensorBoard
from sklearn.model_selection import train_test_split
import numpy as np
from glob import glob
import random
import os数据准备
现在我们我们的数据加载到的Python之前,你需要下载数据集在这里,你会看到两个文件存在,reviews.txt其中包含每行一个电影评论,并labels.txt持有其相应的标签。
以下函数加载和预处理数据集:
def load_imdb_data(num_words, sequence_length, test_size=0.25, oov_token=None):
# read reviews
reviews = []
with open("data/reviews.txt") as f:
for review in f:
review = review.strip()
reviews.append(review)
labels = []
with open("data/labels.txt") as f:
for label in f:
label = label.strip()
labels.append(label)
# tokenize the dataset corpus, delete uncommon words such as names, etc.
tokenizer = Tokenizer(num_words=num_words, oov_token=oov_token)
tokenizer.fit_on_texts(reviews)
X = tokenizer.texts_to_sequences(reviews)
X, y = np.array(X), np.array(labels)
# pad sequences with 0's
X = pad_sequences(X, maxlen=sequence_length)
# convert labels to one-hot encoded
y = to_categorical(y)
# split data to training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=1)
data = {}
data["X_train"] = X_train
data["X_test"]= X_test
data["y_train"] = y_train
data["y_test"] = y_test
data["tokenizer"] = tokenizer
data["int2label"] = {0: "negative", 1: "positive"}
data["label2int"] = {"negative": 0, "positive": 1}
return dataPython如何实现文本分类?这里有很多内容,这个函数执行以下操作:
- 它从前面提到的文件加载数据集。
- 之后,它使用 Keras 的实用程序Tokenizer类,它帮助我们自动删除所有标点符号,标记语料库,删除名称等稀有单词,将文本句子转换为数字序列(每个单词对应一个数字)。
- 我们已经知道神经网络需要固定长度的输入,并且由于评论没有相同长度的单词,我们需要一种方法来使序列的长度固定为固定大小。pad_sequences()函数派上用场,我们告诉它我们只想在每个评论(参数)中说300 个单词
maxlen,它将删除超过该数字的单词,并将用0填充下面的评论300 . - 我们使用Keras' to_categorical()函数来独热编码标签,这是一个二元分类,所以它会转换标签0到[1,0]矢量,和1至[0,1] 。但总的来说,它将分类标签转换为固定长度的向量。
- 之后,我们使用 sklearn 的train_test_split()函数将我们的数据集拆分为训练集和测试集,并使用数据字典添加我们在训练过程中需要的所有东西,即数据集、标记器和标签编码字典。
构建模型
Python使用Tensorflow 2和Keras实现文本分类:现在我们知道如何加载数据集,让我们构建我们的模型。
我们将使用嵌入层作为模型的第一层。嵌入被证明在将分类变量(在这种情况下是单词)映射到连续数字向量方面很有用,它被广泛用于自然语言处理任务。
更准确地说,我们将使用预训练的GloVe词向量,这些词向量是预训练的向量,可将每个词映射到特定大小的向量。这个尺寸参数通常被称为嵌入尺寸,虽然使用手套50,100,200,或300嵌入尺寸的载体。在本教程中,我们将尝试所有这些,看看哪个效果最好。此外,具有相同含义的两个词往往具有非常接近的向量。
第二层将是循环层,你可以选择任何你想要的循环单元,包括LSTM、GRU,甚至只是SimpleRNN,我们将再次看到哪个优于其他单元。
最后一层应该是一个有N 个神经元的密集层,N应该是你的数据集的相同数量的类别。在正面/负面情绪分析的情况下,它应该是2。
该模型的总体架构如下图所示(摘自垃圾邮件分类器教程):
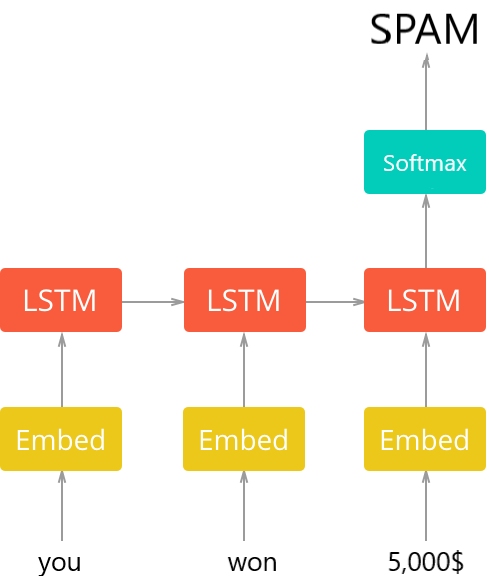
Python文本分类示例:现在你需要下载预训练的GloVe(在此处下载),完成后,将它们全部提取到数据文件夹中(你会发现不同嵌入大小的不同向量),以下函数加载这些向量:
def get_embedding_vectors(word_index, embedding_size=100):
embedding_matrix = np.zeros((len(word_index) + 1, embedding_size))
with open(f"data/glove.6B.{embedding_size}d.txt", encoding="utf8") as f:
for line in tqdm(f, "Reading GloVe"):
values = line.split()
# get the word as the first word in the line
word = values[0]
if word in word_index:
idx = word_index[word]
# get the vectors as the remaining values in the line
embedding_matrix[idx] = np.array(values[1:], dtype="float32")
return embedding_matrix现在我们需要一个从头开始创建模型的函数,给定超参数:
def create_model(word_index, units=128, n_layers=1, cell=LSTM, bidirectional=False,
embedding_size=100, sequence_length=100, dropout=0.3,
loss="categorical_crossentropy", optimizer="adam",
output_length=2):
"""Constructs a RNN model given its parameters"""
embedding_matrix = get_embedding_vectors(word_index, embedding_size)
model = Sequential()
# add the embedding layer
model.add(Embedding(len(word_index) + 1,
embedding_size,
weights=[embedding_matrix],
trainable=False,
input_length=sequence_length))
for i in range(n_layers):
if i == n_layers - 1:
# last layer
if bidirectional:
model.add(Bidirectional(cell(units, return_sequences=False)))
else:
model.add(cell(units, return_sequences=False))
else:
# first layer or hidden layers
if bidirectional:
model.add(Bidirectional(cell(units, return_sequences=True)))
else:
model.add(cell(units, return_sequences=True))
model.add(Dropout(dropout))
model.add(Dense(output_length, activation="softmax"))
# compile the model
model.compile(optimizer=optimizer, loss=loss, metrics=["accuracy"])
return modelPython如何实现文本分类?我知道,这个函数中有很多参数。好吧,为了测试各种参数,这个功能会灵活地对所有提供的参数。让我们解释一下:
word_index:这是一个将每个单词映射到其对应索引号的字典,这是由前面提到的Tokenizer对象生成的。units:这是每个循环层中神经元的数量,默认为128,但可以使用任何你想要的数字,请注意,单位越多,要调整的权重越多,因此在训练中会越慢过程。n_layers:这是我们想要使用的循环层数,1是一个很好的开始。cell: 你要使用的recurrent cell,LSTM是不错的选择。bidirectional:这是一个布尔变量,指示我们是否使用双向循环层。embedding_size:我们前面提到的嵌入向量的大小,我们将尝试各种大小。sequence_length:输入神经网络的每个文本样本上的标记词数,我们也将使用此参数进行试验。dropout:它是在层上训练给定节点的概率,它对于减少过拟合很有用。40%非常适合这个,但尝试调整它,看看它是否表现更好。loss:这是用于训练的损失函数,默认情况下,我们使用分类交叉熵函数。optimizer: 要使用的优化器函数,我们在这里使用ADAM。output_length:这是最后一层使用的神经元数量,因为我们只使用正面和负面情绪分类,它必须是 2。
当你仔细观察时,你会注意到我使用了带参数的Embedding类weights,它指定了我们刚刚下载的预训练权重,我们还设置trainable为False,因此这些向量在此期间根本不会改变训练过程。
如果你的数据集使用的语言与英语不同,请确保为你使用的语言找到嵌入向量,如果没有,则根本不应设置 weights 参数,并且需要设置trainable为True,以便进行训练从头开始矢量的参数,查看此页面以获取你语言的词向量。
训练模型
Python使用Tensorflow 2和Keras实现文本分类 - 现在开始训练,我们需要定义所有前面提到的超参数和更多:
# max number of words in each sentence
SEQUENCE_LENGTH = 300
# N-Dimensional GloVe embedding vectors
EMBEDDING_SIZE = 300
# number of words to use, discarding the rest
N_WORDS = 10000
# out of vocabulary token
OOV_TOKEN = None
# 30% testing set, 70% training set
TEST_SIZE = 0.3
# number of CELL layers
N_LAYERS = 1
# the RNN cell to use, LSTM in this case
RNN_CELL = LSTM
# whether it's a bidirectional RNN
IS_BIDIRECTIONAL = False
# number of units (RNN_CELL ,nodes) in each layer
UNITS = 128
# dropout rate
DROPOUT = 0.4
### Training parameters
LOSS = "categorical_crossentropy"
OPTIMIZER = "adam"
BATCH_SIZE = 64
EPOCHS = 6
def get_model_name(dataset_name):
# construct the unique model name
model_name = f"{dataset_name}-{RNN_CELL.__name__}-seq-{SEQUENCE_LENGTH}-em-{EMBEDDING_SIZE}-w-{N_WORDS}-layers-{N_LAYERS}-units-{UNITS}-opt-{OPTIMIZER}-BS-{BATCH_SIZE}-d-{DROPOUT}"
if IS_BIDIRECTIONAL:
# add 'bid' str if bidirectional
model_name = "bid-" + model_name
if OOV_TOKEN:
# add 'oov' str if OOV token is specified
model_name += "-oov"
return model_name到目前为止,我已经设置了最佳参数,我发现get_model_name()函数正在根据参数生成唯一的模型名称,这在比较TensorBoard上的各种参数时非常有用。
让我们把所有东西放在一起,开始训练我们的模型:
# create these folders if they does not exist
if not os.path.isdir("results"):
os.mkdir("results")
if not os.path.isdir("logs"):
os.mkdir("logs")
if not os.path.isdir("data"):
os.mkdir("data")
# dataset name, IMDB movie reviews dataset
dataset_name = "imdb"
# get the unique model name based on hyper parameters on parameters.py
model_name = get_model_name(dataset_name)
# load the data
data = load_imdb_data(N_WORDS, SEQUENCE_LENGTH, TEST_SIZE, oov_token=OOV_TOKEN)
# construct the model
model = create_model(data["tokenizer"].word_index, units=UNITS, n_layers=N_LAYERS,
cell=RNN_CELL, bidirectional=IS_BIDIRECTIONAL, embedding_size=EMBEDDING_SIZE,
sequence_length=SEQUENCE_LENGTH, dropout=DROPOUT,
loss=LOSS, optimizer=OPTIMIZER, output_length=data["y_train"][0].shape[0])
model.summary()
# using tensorboard on 'logs' folder
tensorboard = TensorBoard(log_dir=os.path.join("logs", model_name))
# start training
history = model.fit(data["X_train"], data["y_train"],
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_data=(data["X_test"], data["y_test"]),
callbacks=[tensorboard],
verbose=1)
# save the resulting model into 'results' folder
model.save(os.path.join("results", model_name) + ".h5")这将需要几分钟的时间来训练,这是训练完成后我的执行输出:
Reading GloVe: 400000it [00:17, 23047.55it/s]
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 300, 300) 37267200
_________________________________________________________________
lstm (LSTM) (None, 128) 219648
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense (Dense) (None, 2) 258
=================================================================
Total params: 37,487,106
Trainable params: 219,906
Non-trainable params: 37,267,200
_________________________________________________________________
Train on 35000 samples, validate on 15000 samples
Epoch 1/6
35000/35000 [==============================] - 186s 5ms/sample - loss: 0.4359 - accuracy: 0.7919 - val_loss: 0.2912 - val_accuracy: 0.8788
Epoch 2/6
35000/35000 [==============================] - 179s 5ms/sample - loss: 0.2857 - accuracy: 0.8820 - val_loss: 0.2608 - val_accuracy: 0.8919
Epoch 3/6
35000/35000 [==============================] - 175s 5ms/sample - loss: 0.2501 - accuracy: 0.8985 - val_loss: 0.2472 - val_accuracy: 0.8977
Epoch 4/6
35000/35000 [==============================] - 174s 5ms/sample - loss: 0.2184 - accuracy: 0.9129 - val_loss: 0.2525 - val_accuracy: 0.8997
Epoch 5/6
35000/35000 [==============================] - 185s 5ms/sample - loss: 0.1918 - accuracy: 0.9246 - val_loss: 0.2576 - val_accuracy: 0.9035
Epoch 6/6
35000/35000 [==============================] - 188s 5ms/sample - loss: 0.1598 - accuracy: 0.9391 - val_loss: 0.2494 - val_accuracy: 0.9004复制太棒了,经过6 个epoch 的训练,它达到了大约90% 的准确率。
测试模型
使用模型非常简单,下面的函数使用model.predict()方法来生成输出:
def get_predictions(text):
sequence = data["tokenizer"].texts_to_sequences([text])
# pad the sequences
sequence = pad_sequences(sequence, maxlen=SEQUENCE_LENGTH)
# get the prediction
prediction = model.predict(sequence)[0]
return prediction, data["int2label"][np.argmax(prediction)]如你所见,为了正确生成预测,我们需要使用之前使用的标记器将文本转换为序列,然后填充序列使其成为固定长度的序列,然后我们使用模型生成输出。 predict()方法,让我们试试这个模型:
text = "The movie is awesome!"
output_vector, prediction = get_predictions(text)
print("Output vector:", output_vector)
print("Prediction:", prediction)输出:
Output vector: [0.3001343 0.69986564]
Prediction: positive让我们使用另一个文本:
text = "The movie is bad."
output_vector, prediction = get_predictions(text)
print("Output vector:", output_vector)
print("Prediction:", prediction)复制输出:
Output vector: [0.92491007 0.07508987]
Prediction: negative可以肯定的是,这是一种负面情绪,置信度约为92%。让我们更具挑战性:
text = "Not very good, but pretty good try."
output_vector, prediction = get_predictions(text)
print("Output vector:", output_vector)
print("Prediction:", prediction)输出:
Output vector: [0.38528103 0.61471903]
Prediction: positive这是相当61%肯定这是一个很好的情绪,你可以看到,它给有趣的结果,花一些时间欺骗的典范!
超参数调优
Python文本分类示例:在我想出90% 的准确率之前,我已经尝试了各种超参数,以下是一些有趣的参数:
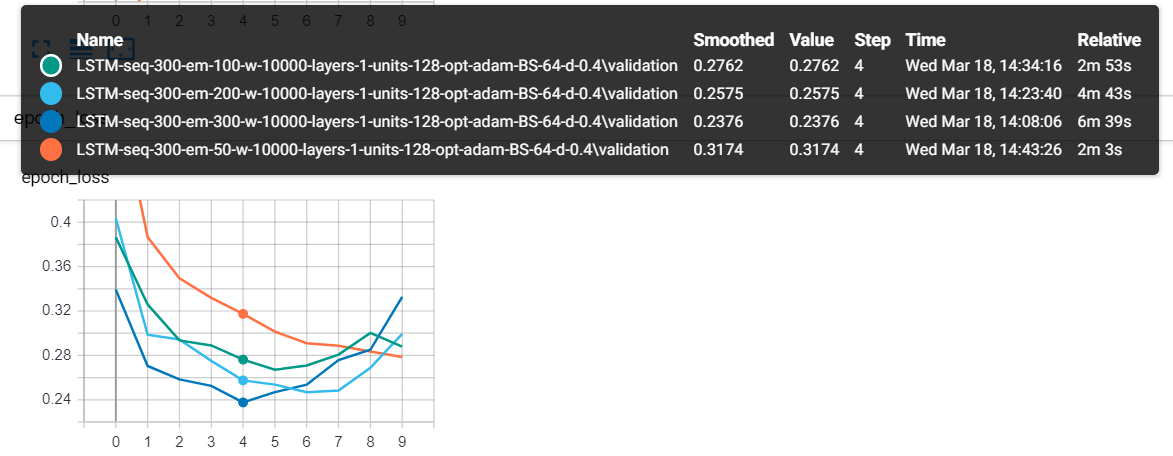
这是 4 个模型,每个模型都有不同的嵌入大小,如你所见,具有 300 长度向量的模型(每个单词有 300 长度向量)达到了最低的验证损失值。
当我使用序列长度作为可变参数时,这是另一个:
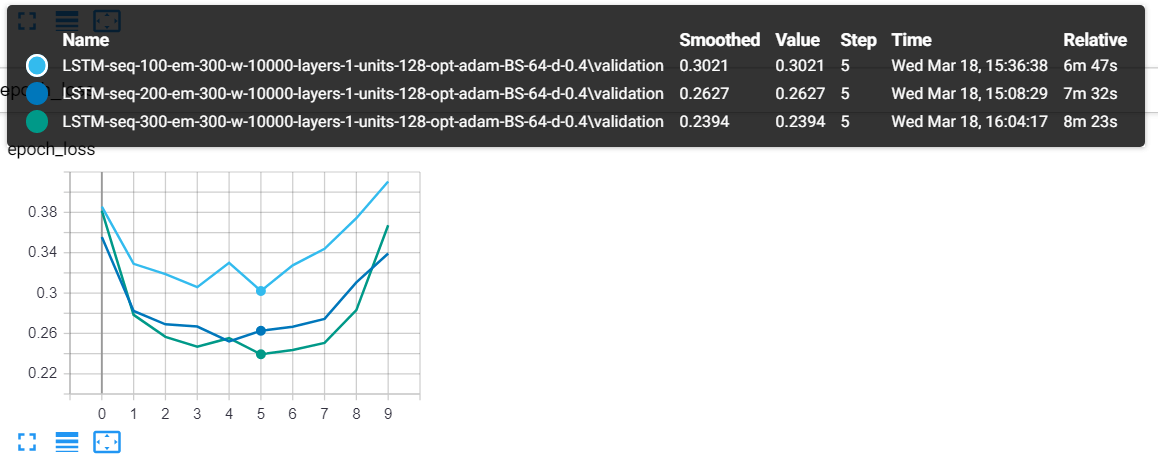
序列长度为300的模型(绿色的)往往表现更好。
使用 tensorboard,你可以看到在到达 epochs 4-5-6 后,验证损失将尝试再次增加,这显然是过度拟合。这就是我将 epochs 设置为6的原因。尝试调整其他参数,例如辍学率,看看是否可以进一步降低。
集成自定义数据集
Python如何实现文本分类?由于这是一个文本分类教程,如果你可以使用自己的数据集而无需更改本教程的大部分代码,这将非常有用。事实上,你需要改变的只是加载数据函数,之前我们使用了load_imdb_data()函数,它返回一个数据字典,它具有:
X_train:一个 NumPy 数组,其形状(训练样本数、序列长度)包含每个数据样本的所有序列。X_test: 同上,但用于测试样品。y_train:这些是训练集的标签,它是一个形状的 NumPy 数组(测试样本数,总类别数),在情感分析的情况下,这应该类似于 ( 15000 , 2 )y_test: 同上,但用于测试样品。tokenizer:这是来自tensorflow.keras.preprocessing.text模块的 Tokenizer 实例,用于标记语料库的对象。label2int:将标签转换为其对应编码整数的 Python 字典,在情感分析示例中,我们使用 1 表示正面,0 表示负面。int2label: 反之亦然。
Python使用Tensorflow 2和Keras实现文本分类 - 这是一个加载20 个新闻组数据集(包含20 个主题的大约18000 个新闻组帖子)的示例函数,它使用 sklearn 的内置函数fetch_20newsgroups():
from sklearn.datasets import fetch_20newsgroups
def load_20_newsgroup_data(num_words, sequence_length, test_size=0.25, oov_token=None):
# load the 20 news groups dataset
# shuffling the data & removing each document's header, signature blocks and quotation blocks
dataset = fetch_20newsgroups(subset="all", shuffle=True, remove=("headers", "footers", "quotes"))
documents = dataset.data
labels = dataset.target
tokenizer = Tokenizer(num_words=num_words, oov_token=oov_token)
tokenizer.fit_on_texts(documents)
X = tokenizer.texts_to_sequences(documents)
X, y = np.array(X), np.array(labels)
# pad sequences with 0's
X = pad_sequences(X, maxlen=sequence_length)
# convert labels to one-hot encoded
y = to_categorical(y)
# split data to training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=1)
data = {}
data["X_train"] = X_train
data["X_test"]= X_test
data["y_train"] = y_train
data["y_test"] = y_test
data["tokenizer"] = tokenizer
data["int2label"] = { i: label for i, label in enumerate(dataset.target_names) }
data["label2int"] = { label: i for i, label in enumerate(dataset.target_names) }
return data好的,祝你在实现自己的文本分类器时好运,如果你在集成分类器时遇到任何问题,请在下方发表你的评论,我会尽快与你取得联系。
正如我之前提到的,尝试使用提供的所有超参数进行试验,我尝试编写尽可能灵活的代码,以便你可以只更改参数而无需执行任何其他操作。如果你的参数超过我的参数,请在下面的评论中与我们分享!

