
Python Scikit-Learn实现特征选择:了解如何使用 Python 中的 Scikit-Learn 库通过 SelectKBest、随机森林算法和递归特征消除 (RFE) 执行特征选择。
数据科学管道中涉及许多步骤,从原始数据到为给定任务构建优化的机器学习模型。然而,数据处理是最需要努力和时间的步骤,并且对以后模型的性能有直接的影响和影响。
Python如何实现特征选择?在本文中,我们将重点介绍如何在我们的数据集上应用一些特征选择,这代表了数据预处理阶段的核心方面。但在深入编码和实现用于这些任务的不同技术之前,让我们首先定义特征选择的含义。
特征选择是从数据集中选择对模型性能贡献最大的特征子集的过程,并且不对其应用任何类型的转换。
Python Scikit-Learn特征选择教程:我们将使用的数据集是来自 Kaggle的心脏病预测数据集,你可以使用 Kaggle Kernel VM 直接处理该数据集,也可以将其下载到本地机器。
以下是安装本教程所需库的命令:
$ pip3 install numpy pandas matplotlib sklearn预处理
Python Scikit-Learn实现特征选择:我们将首先使用 Pandas 将我们的数据集加载到数据帧格式中。它由13 个特征加上标签组成,共有270行。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.feature_selection import SelectKBest,chi2,RFE
from sklearn.ensemble import RandomForestClassifier
df = pd.read_csv("data/Heart_Disease_Prediction.csv")
print(df.shape)
df.head(5)Python如何实现特征选择?上面的代码导入必要的库并从data文件夹中读取数据集 CSV 文件,接下来,你还需要创建data文件夹,你可以更改数据集文件在你的机器中的位置的路径。
下面是输出:
(270, 14)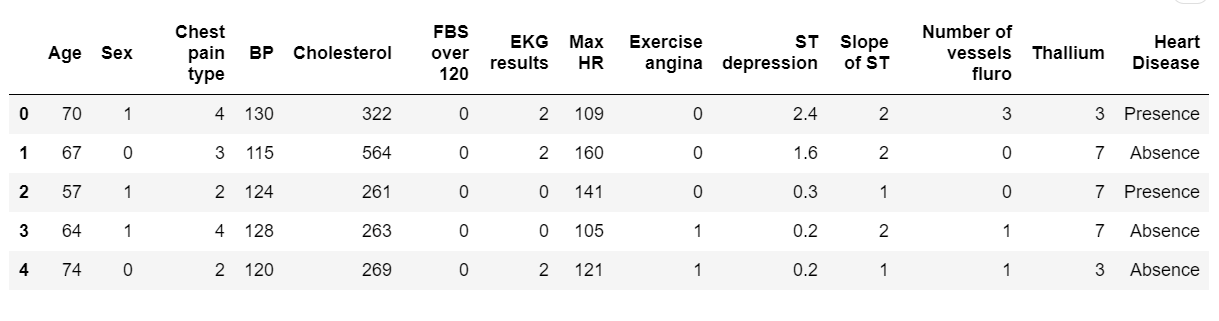
从这里我们可以清楚地观察到没有空值,因此我们可以直接开始处理我们的数据帧,而无需执行一些空值清理。
我们将标签列存储到一个单独的变量中,并将其inplace=True从数据框中完全删除(因此,使用)。当我们将数据集划分为训练和测试以及何时将它们拟合到我们的模型时,这一步很重要。
label = df["Heart Disease"]
df.drop("Heart Disease", axis=1, inplace=True)始终检查我们的数据集的不平衡程度很重要,因为少数类和多数类之间的较大不平衡比率会对模型产生负面影响,从某种意义上说,它只会天真地预测多数类。然而,对于我们的情况,不平衡比率只是1.25它并不大。
print(label.value_counts())
label.value_counts().plot(kind="bar")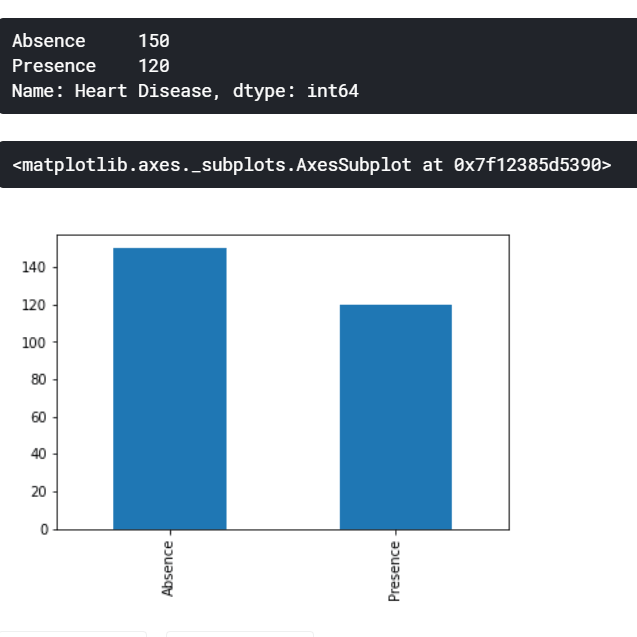
我们的数据集具有遵循分类性质的特征。然而,在打印这些列的数据类型时,我们观察到它们被视为整数,这可能使我们的模型将它们视为连续值,尽管它们本质上是离散的。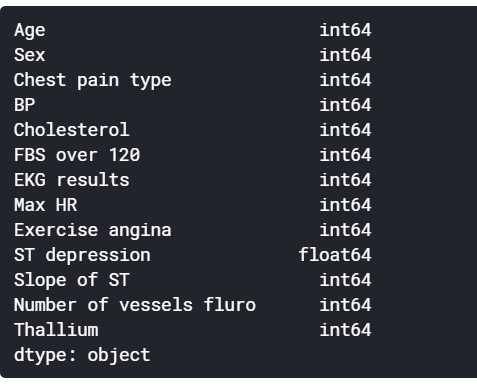
出于这个原因,我们将使用astype()pandas 方法明确地将它们的数据类型更改为分类。
categorical_features = ["Sex", "Chest pain type", "FBS over 120", "EKG results", "Exercise angina", "Slope of ST", "Number of vessels fluro", "Thallium"]
df[categorical_features] = df[categorical_features].astype("category")
Python如何实现特征选择?我们现在将使用 来缩放我们的连续特征MinMaxScaler,它是一种归一化类型,其中值的范围在0到1之间,方程定义为X_Norm = (X - X_Min) / (X_Max - X_Min).
continuous_features = set(df.columns) - set(categorical_features)
scaler = MinMaxScaler()
df_norm = df.copy()
df_norm[list(continuous_features)] = scaler.fit_transform(df[list(continuous_features)])使用卡方进行特征选择
Python Scikit-Learn实现特征选择:一卡方检验是用于统计测试两个事件的独立性。给定两个变量的数据,我们可以得到观察到的计数O和预期的计数E。卡方测量预期计数E和观察计数O如何相互偏离。
在特征选择中,由于 chi 2测试两个变量之间的独立程度,我们将在每个特征和标签之间使用它,我们将只保留k具有最高 chi 2值的特征数量,因为我们只想保留最依赖我们标签的特征。我们将同时重视SelectKBest 和chi2fromsklearn.feature_selection模块。SelectKBest需要两个超参数,它们是:
k:我们要选择的特征数量。score_func:选择过程所基于的功能。
X_new = SelectKBest(k=5, score_func=chi2).fit_transform(df_norm, label)使用递归特征消除 (RFE) 进行特征选择
来自 sklearn 文档:递归特征消除(RFE)的目标是通过递归地考虑越来越小的特征集来选择特征。我们也将使用sklearn.feature_selection模块来导入RFE类。RFE需要两个超参数:
n_features_to_select:我们要选择的特征数量。estimator:在每次迭代中将使用哪种类型的机器学习模型进行预测,同时递归搜索适当的特征集。
rfe = RFE(estimator=RandomForestClassifier(), n_features_to_select=5)
X_new = rfe.fit_transform(df_norm, label)
X_new使用随机森林的特征选择
Python Scikit-Learn特征选择教程:基于树的机器学习算法DecisionTreeClassifier或它们的集成学习等价物RandomForestClassifier使用一组树,其中包含由分裂产生的节点。这些拆分的主要目的是通过使用诸如熵和基尼指数之类的杂质度量来尽可能地减少杂质。这些基于树的模型可以通过计算该特征将导致的杂质减少量来计算该特征的重要性。
clf = RandomForestClassifier()
clf.fit(df_norm, label)
# create a figure to plot a bar, where x axis is features, and Y indicating the importance of each feature
plt.figure(figsize=(12,12))
plt.bar(df_norm.columns, clf.feature_importances_)
plt.xticks(rotation=45)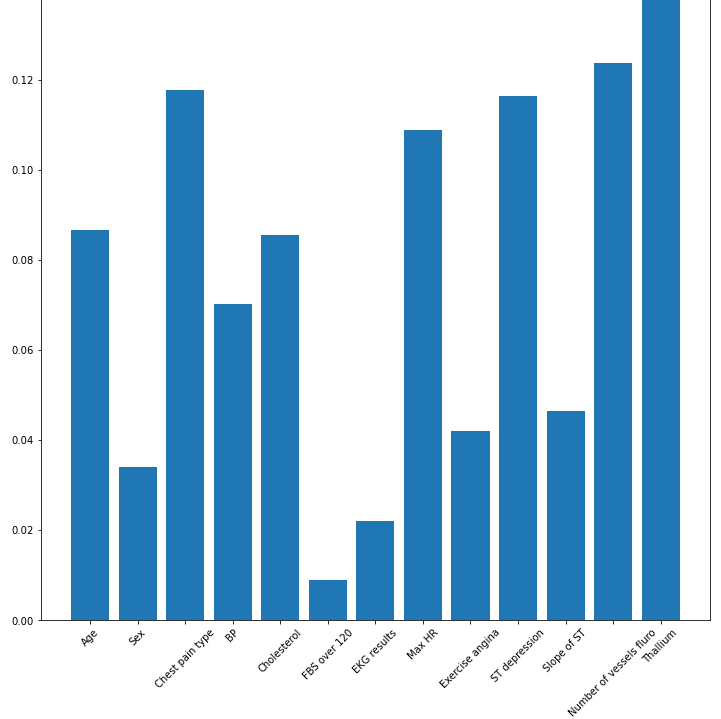
上面的直方图显示了每个特征的重要性。在我们的例子中,铊和血管数量是最重要的特征,但它们中的大多数都很重要,既然如此,将这些特征提供给我们的机器学习模型是非常值得的。
现在你已经选择了最佳特征,你可以轻松使用任何 sklearn 分类器模型和提要X_new数组,看看它是否会影响完整特征模型的准确性。
Python Scikit-Learn实现特征选择总结
使用此类技术进行特征选择会因问题而异,也因特征而异,具体取决于它们的类型是分类的还是连续的。
Python如何实现特征选择?此外,对于要选择的特征数量,这可以通过遵循迭代方法来回答,直到k(in SelectKBest) 收敛并且机器学习性能没有增加太多。
在本Python Scikit-Learn特征选择教程中,我们学习了如何:
- 使用chi 2选择对标签依赖度高的特征。
- 使用 RFE 递归地找到给定估计量的最佳特征集。
- 使用随机森林等基于树的机器学习方法来显示有助于在拆分节点时尽可能减少杂质的特征。

