
Imblearn和Smote如何实现不平衡学习?除了在 Python 中使用 Imblearn 库之外,学习如何通过使用不同类型和变体的 smote 对数据集进行欠采样或过采样来克服与不平衡相关的问题。
Python不平衡学习教程:在机器学习中,更具体地说,在分类(监督学习)中,与玩具数据相比,工业/原始数据集的处理方式更为复杂。
在这些限制中,存在高不平衡率,通常情况下,常见类别(多数)比我们实际要研究的类别(少数)发生得更频繁。
Python Imblearn和Smote变体库不平衡学习:在本教程中,我们将深入了解不平衡学习问题背后的更多细节,它如何影响我们的模型,理解欠采样/过采样的含义并使用 Python 库smote-variants 实现。
在整个教程中,我们将使用来自 Kaggle的欺诈性信用卡数据集,你可以在此处下载。
安装
$ pip install numpy pandas imblearn smote-variants还学习:在 Python 中使用 Scikit-Learn 进行特征选择
什么是不平衡学习?
不平衡学习在大多数情况下存在于行业中。如上所述,需要进一步研究和分析的目标类(针对二元或多类问题)通常会在大量存在的常见类面前缺乏数据。
这种不平衡对训练时模型的性能有直接的负面影响,它会偏向多数类,这可能导致陷入准确性悖论。
为了更好地说明准确率悖论,假设一个数据集包含 98 个来自第 0 类的样本和来自第 1 类的 2 个样本,如果我们的模型天真地将所有样本预测为 0,我们仍然会有 98% 的准确度,这相对较好,即使我们的模型只是默认将所有类别预测为 0。这样的准确度值具有误导性,可能会给出错误的结论。
出于这个原因,我们现在将讨论不平衡数据集时使用的指标:
- 精度:当误报的成本很高时,精度会有所帮助,因此精度越高,误报率越小。
- 召回:召回在假阴性的成本很高时有帮助,因此召回越大,假阴性率越小。
- F1-Score:它是precision和recall的调和平均值,换句话说,它考虑了两者,所以f1分数越高,假阴性和假阳性率越低。
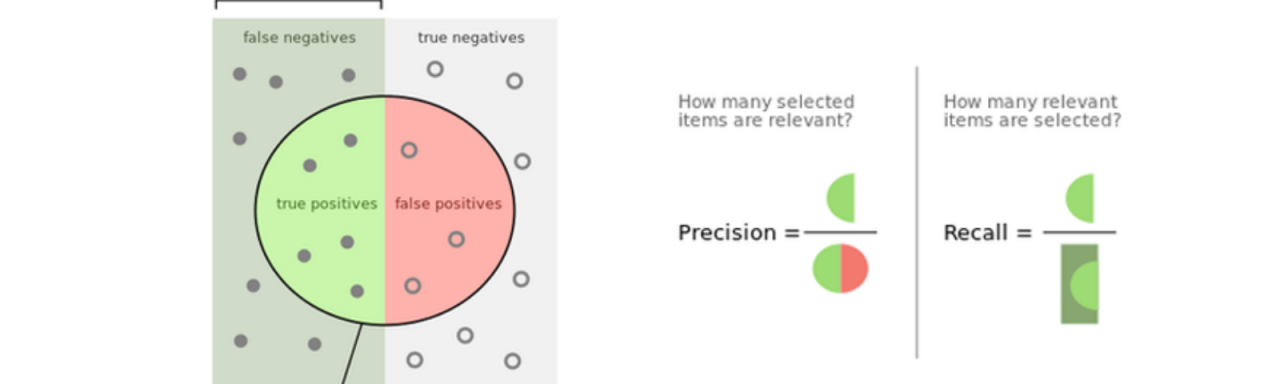
Python不平衡学习教程:不平衡学习中存在的另一个特征称为 不平衡比率。在二元不平衡分类的情况下,它是通过将少数类的大小除以多数类的大小来计算的。我们使用IR来了解不平衡问题的严重程度。
欠采样/过采样的类型为了减少不平衡率,我们可以采用两种不同的方法,我们可以减少多数类(欠采样)或向少数类添加样本(过采样)。
在本教程中,我们将介绍两种基于重采样的方法:
- 随机抽样:这里我们不遵循任何启发式,我们随机删除或复制样本。
- 定向采样:与随机采样不同,这里我们遵循给定的启发式/算法来选择在欠采样的情况下需要删除的样本,或者在进行过采样时为少数样本人为地创建和生成数据点。
Imblearn和Smote如何实现不平衡学习?对于随机抽样,我们将使用imblearn Python 库。但首先,我们会将 CSV 转换为数据框格式并将标签存储到变量中y。
import numpy as np
import pandas as pd
df=pd.read_csv("creditcard.csv")
y=df["Class"]
X=df.drop(["Time","Class"],axis=1)
print(y.value_counts())输出:
0 284315
1 492
Name: Class, dtype: int64复制我们现在RandomUnderSampler()将从imblearn创建一个对象,并使用该方法fit_resample()对数据集应用欠采样。
from imblearn.under_sampling import RandomUnderSampler
under=RandomUnderSampler()
X_und,y_und=under.fit_resample(X,y)
print(len(X_und[X_und==1])==len(X_und[X_und==0]))输出:
True如你所见,在应用欠采样后,非欺诈信用卡的数量等于欺诈信用卡的数量。
对于随机过采样,我们使用相同的过程,唯一的区别是使用RandomOverSampler()代替RandomUnderSampler()。
from imblearn.over_sampling import RandomOverSampler
over=RandomOverSampler()
X_und,y_und=over.fit_resample(X,y)
print(len(X_und[X_und==1])==len(X_und[X_und==0]))
输出:
True复制定向欠采样
Python Imblearn和Smote变体库不平衡学习:现在我们将深入研究第二种平衡算法,即定向方法。
对于欠,我们将介绍这些算法:编辑距离最近的邻居, 实例硬度阈值, 并 TomekLinks。
- Edited Nearest Neighbors:在这种欠采样技术中,我们删除了多数样本,其中大多数样本来自少数类。
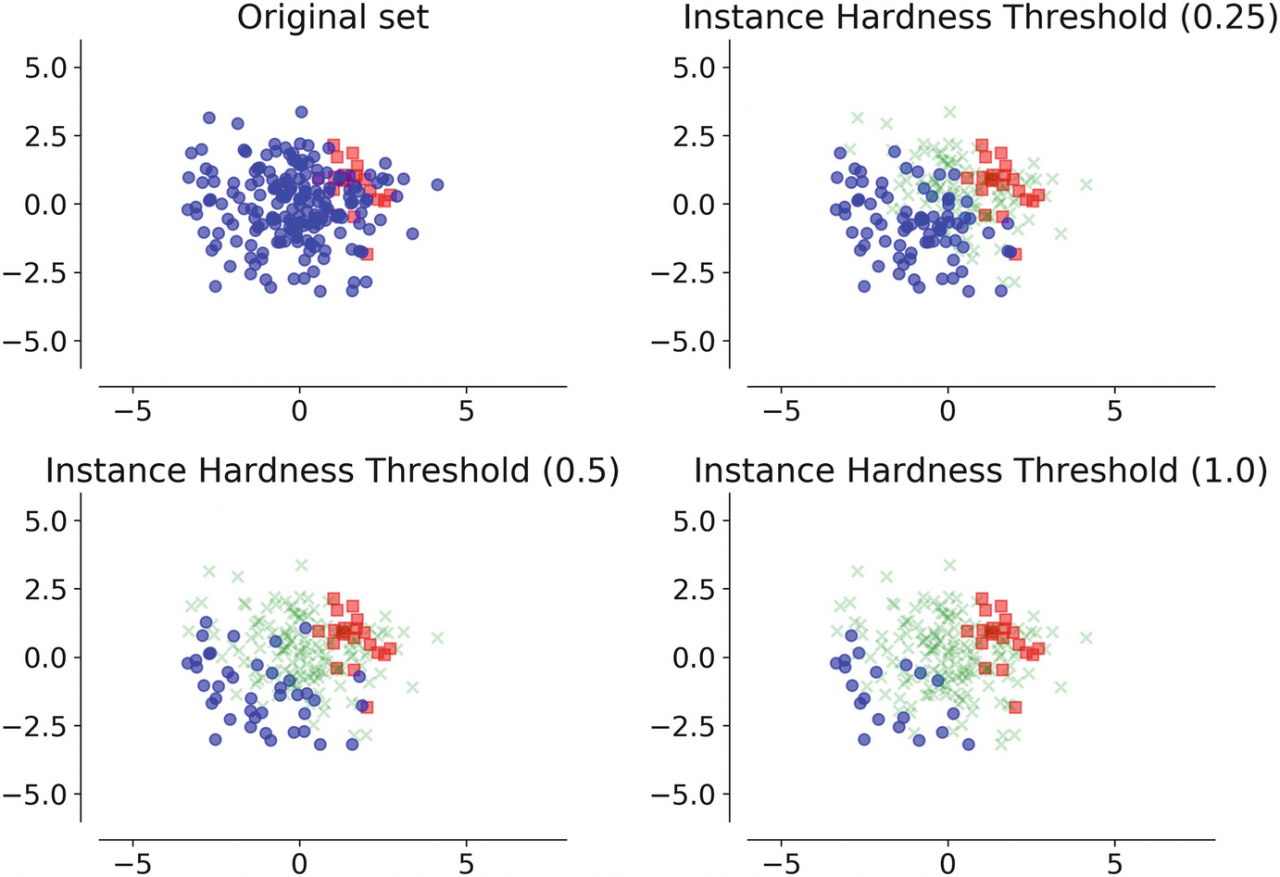
- 实例硬度阈值:这里我们从难以分类的多数类中消除数据点。我们基本上使用 n 个分类器并平均错误分类实例的可能性,它等于1 - Pi,其中Pi是给定分类器的样本i的估计概率预测。
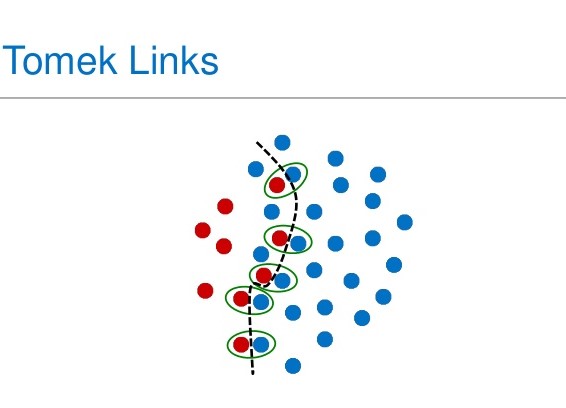
- TomekLinks:这里我们删除了具有带有少数数据点的 tomeklink 的多数样本。当遵循此公式时,会出现 tomek 链接;给定两个样本x和y,对于任何其他样本z我们有:dist(x,y) < dist(x,z) 和 dist(x,y) < dist(y,z)。换句话说,如果少数和多数数据点彼此是最近的邻居,它们就会形成一个 tomek 链接。
from imblearn.under_sampling import EditedNearestNeighbours,InstanceHardnessThreshold,TomekLinks
under_samp_models=[EditedNearestNeighbours(),InstanceHardnessThreshold,TomekLinks()]
for under_samp_model in under_samp_models:
X_und,y_und=under_samp_model.fit_resample(X,y)使用 Smote 进行定向过采样
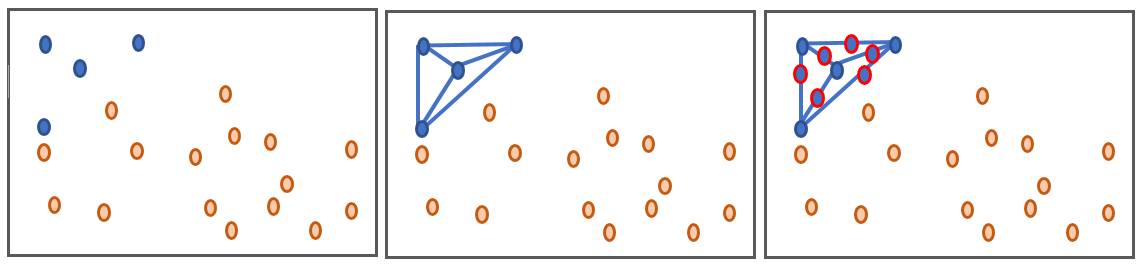
SMOTE( “ š ynthetic中号inority ö versampling TE chnique”)是一个过采样技术,其工作原理是如下面的图中绘制少数数据点之间的线,并产生在整个这些行的数据。
Imblearn和Smote如何实现不平衡学习?我们将使用smote-variants Python 库,它是一个包含 85 种 smote 变体的包,所有这些都在这篇科学文章中提到过。
该实现与imblearn的实现非常相似,但有一些细微的变化,例如使用该方法sample()而不是fit_resample()生成数据。在本教程中,我们将使用 Kmeans_Smote,Safe_Level_Smote以及Smote_Cosine对实施例的缘故。
import smote_variants as sv
svs=[sv.kmeans_SMOTE(),sv.Safe_Level_SMOTE(),sv.SMOTE_Cosine()]
for over_sampler in svs:
X_over_samp, y_over_samp= over_sampler.sample(X, y)Python Imblearn和Smote变体库不平衡学习结论
在这个Python不平衡学习教程中,我们学到了:
- 如何定义不平衡学习问题,什么是不平衡比率。
- 了解如何使用适当的指标来避免陷入准确性悖论。
- 了解随机抽样和定向抽样之间的区别。
- 分别使用 Python 库imblearn和smote -variants进行欠采样和过采样。

