
自然语言处理(NLP) 是一个专注于使计算机程序可以使用自然人类语言的领域。NLTK或Natural Language Toolkit是可用于 NLP 的 Python 包。
NLTK如何实现自然语言处理?你可以分析的许多数据都是非结构化数据,并且包含人类可读的文本。在以编程方式分析该数据之前,你首先需要对其进行预处理。在本NLTK自然语言处理教程中,你将首先了解可以使用 NLTK 执行的文本预处理任务的种类,以便你准备好在未来的项目中应用它们。你还将看到如何进行一些基本的文本分析和创建可视化。
如果你熟悉使用 Python的基础知识,并希望了解一些 NLP,那么你来对地方了。
在本Python NLTK 自然语言处理教程结束时,你将知道如何:
- 查找要分析的文本
- NLTK实现自然语言处理示例
- 预处理你的文本以进行分析
- 分析你的文字
- 根据你的分析创建可视化
让我们开始 Python!
免费下载: 从 Python Basics: A Practical Introduction to Python 3 中获取示例章节,了解如何使用 Python 3.8 的最新完整课程从 Python 初级到中级。
Python 的 NLTK 入门
你需要做的第一件事是确保安装了 Python。在本教程中,你将使用 Python 3.9。如果你还没有安装 Python,请查看Python 3 安装和设置指南以开始使用。
一旦你解决了这个问题,下一步就是安装 NLTK与pip. 最佳做法是将其安装在虚拟环境中。要了解有关虚拟环境的更多信息,请查看Python 虚拟环境:入门。
对于本教程,你将安装 3.5 版:
$ python -m pip install nltk==3.5
为了为命名实体识别创建可视化,你还需要安装NumPy和Matplotlib:
$ python -m pip install numpy matplotlib
如果你想了解更多有关pip工作原理的信息,可以查看什么是 Pip?新 Pythonistas 指南。你还可以查看安装 NLTK 数据的官方页面。
代币化
通过标记化,你可以方便地按单词或按句子拆分文本。这将允许你处理较小的文本片段,即使在文本其余部分的上下文之外,这些文本片段仍然相对连贯且有意义。这是将非结构化数据转化为更易于分析的结构化数据的第一步。
当你分析文本时,你将按单词进行标记并按句子进行标记。以下是两种类型的标记化带来的好处:
- 按单词标记:单词就像自然语言的原子。它们是本身仍然有意义的最小意义单位。通过单词标记你的文本可以让你识别特别频繁出现的单词。例如,如果你正在分析一组招聘广告,那么你可能会发现“Python”这个词经常出现。这可能表明对 Python 知识的需求很高,但你需要更深入地了解更多信息。
- 按句子标记:当你按句子标记时,你可以分析这些词之间的关系并查看更多上下文。因为招聘经理不喜欢 Python,所以围绕“Python”这个词是否有很多负面词?爬虫学领域是否有比软件开发领域更多的术语,表明你可能正在处理一种与你预期完全不同的Python?
以下是如何导入NLTK 的相关部分,以便你可以按单词和句子进行标记:>>>
>>> from nltk.tokenize import sent_tokenize, word_tokenize
现在你已经导入了你需要的内容,你可以创建一个字符串来标记化。以下是Dune的引用,你可以使用:>>>
>>> example_string = """
... Muad'Dib learned rapidly because his first training was in how to learn.
... And the first lesson of all was the basic trust that he could learn.
... It's shocking to find how many people do not believe they can learn,
... and how many more believe learning to be difficult."""
你可以使用sent_tokenize()拆分example_string成句子:>>>
>>> sent_tokenize(example_string)
["Muad'Dib learned rapidly because his first training was in how to learn.",
'And the first lesson of all was the basic trust that he could learn.',
"It's shocking to find how many people do not believe they can learn, and how many more believe learning to be difficult."]
example_string按句子标记为你提供三个作为句子的字符串的列表:
"Muad'Dib learned rapidly because his first training was in how to learn."'And the first lesson of all was the basic trust that he could learn.'"It's shocking to find how many people do not believe they can learn, and how many more believe learning to be difficult."
现在尝试example_string按单词标记:>>>
>>> word_tokenize(example_string)
["Muad'Dib",
'learned',
'rapidly',
'because',
'his',
'first',
'training',
'was',
'in',
'how',
'to',
'learn',
'.',
'And',
'the',
'first',
'lesson',
'of',
'all',
'was',
'the',
'basic',
'trust',
'that',
'he',
'could',
'learn',
'.',
'It',
"'s",
'shocking',
'to',
'find',
'how',
'many',
'people',
'do',
'not',
'believe',
'they',
'can',
'learn',
',',
'and',
'how',
'many',
'more',
'believe',
'learning',
'to',
'be',
'difficult',
'.']
你得到了 NLTK 认为是单词的字符串列表,例如:
"Muad'Dib"'training''how'
但以下字符串也被认为是单词:
"'s"',''.'
看看如何"It's"在撇号处拆分给你'It'和"'s",但"Muad'Dib"仍然是完整的?发生这种情况是因为 NLTK 知道'It'和"'s"(“is”的缩写)是两个不同的词,所以它分别计算了它们。但"Muad'Dib"不是像 一样被接受的缩略词"It's",所以它没有被当作两个单独的词来读,而是保持不变。
NLTK实现自然语言处理示例:过滤停用词
停用词是你想要忽略的词,因此在处理文本时将它们从文本中过滤掉。非常常见的词,例如'in','is'和'an'经常用作停用词,因为它们本身并没有为文本添加很多含义。
NLTK如何实现自然语言处理?下面介绍如何导入 NLTK 的相关部分以过滤停用词:>>>
>>> nltk.download("stopwords")
>>> from nltk.corpus import stopwords
>>> from nltk.tokenize import word_tokenize
以下是你可以过滤的Worf 引述:>>>
>>> worf_quote = "Sir, I protest. I am not a merry man!"
现在worf_quote按单词标记并将结果列表存储在words_in_quote:>>>
>>> words_in_quote = word_tokenize(worf_quote)
>>> words_in_quote
['Sir', ',', 'protest', '.', 'merry', 'man', '!']
你有一个 中的词列表worf_quote,因此下一步是创建一组停用词以进行过滤words_in_quote。对于此示例,你需要关注 中的停用词"english":>>>
>>> stop_words = set(stopwords.words("english"))
接下来,创建一个空列表来保存通过过滤器的单词:>>>
>>> filtered_list = []
你创建了一个空列表 ,filtered_list以保存words_in_quote其中不是停用词的所有单词。现在你可以使用stop_words过滤器words_in_quote:>>>
>>> for word in words_in_quote:
... if word.casefold() not in stop_words:
... filtered_list.append(word)
你words_in_quote使用for循环进行迭代并将所有不是停用词的词添加到filtered_list. 你使用了.casefold()onword这样你就可以忽略其中的字母word是大写还是小写。这是值得做的,因为stopwords.words('english')仅包含停用词的小写版本。
或者,你可以使用列表理解来列出文本中所有不是停用词的单词:>>>
>>> filtered_list = [
... word for word in words_in_quote if word.casefold() not in stop_words
... ]
当你使用列表推导式时,你不会创建一个空列表,然后将项目添加到它的末尾。相反,你可以同时定义列表及其内容。使用列表推导式通常被视为更加Pythonic。
看看以 结尾的单词filtered_list:>>>
>>> filtered_list
['Sir', ',', 'protest', '.', 'merry', 'man', '!']
你过滤掉了几个像'am'和这样的词'a',但你也过滤掉了'not',这确实影响了句子的整体含义。(Worf 不会对此感到高兴。)
像'I'和这样的词'not'可能看起来太重要而无法过滤掉,这取决于你想要进行的分析类型,它们可以是。原因如下:
'I'是代词,是上下文词而不是内容词:- 内容词为你提供有关文本中涵盖的主题的信息或作者对这些主题的看法。
- 上下文词为你提供有关写作风格的信息。你可以观察作者如何使用上下文词来量化他们的写作风格的模式。一旦你量化了他们的写作风格,你就可以分析由未知作者撰写的文本,以了解它与特定写作风格的接近程度,以便你可以尝试确定作者是谁。
'not'从技术上讲是副词,但仍包含在NLTK 的英语停用词列表中。如果你想编辑停用词列表以排除'not'或进行其他更改,则可以下载它。
所以,'I'and'not'可以是句子的重要部分,但这取决于你想从这句话中学到什么。
NLTK自然语言处理教程:词干
词干提取是一项文本处理任务,你可以在其中将单词缩减为词根,这是词的核心部分。例如,单词“helping”和“helper”共享词根“help”。词干分析允许你将单词的基本含义归零,而不是将其使用方式的所有细节归零。NLTK 有多个词干分析器,但你将使用Porter 词干分析器。
以下是如何导入 NLTK 的相关部分以开始词干:>>>
>>> from nltk.stem import PorterStemmer
>>> from nltk.tokenize import word_tokenize
现在你已完成导入,你可以使用以下命令创建词干分析器PorterStemmer():>>>
>>> stemmer = PorterStemmer()
下一步是为你创建一个字符串作为词干。这是你可以使用的一个:>>>
>>> string_for_stemming = """
... The crew of the USS Discovery discovered many discoveries.
... Discovering is what explorers do."""
在你可以提取该字符串中的单词之前,你需要将其中的所有单词分开:>>>
>>> words = word_tokenize(string_for_stemming)
现在你有了字符串中所有标记词的列表,请查看其中的内容words:>>>
>>> words
['The',
'crew',
'of',
'the',
'USS',
'Discovery',
'discovered',
'many',
'discoveries',
'.',
'Discovering',
'is',
'what',
'explorers',
'do',
'.']
words通过stemmer.stem()在列表理解中使用,创建单词 in 的词干版本列表:>>>
>>> stemmed_words = [stemmer.stem(word) for word in words]
看看里面有什么stemmed_words:>>>
>>> stemmed_words
['the',
'crew',
'of',
'the',
'uss',
'discoveri',
'discov',
'mani',
'discoveri',
'.',
'discov',
'is',
'what',
'explor',
'do',
'.']
以下是所有以'discov'or开头的单词的情况'Discov':
| 原词 | 词干版本 |
|---|---|
'Discovery' | 'discoveri' |
'discovered' | 'discov' |
'discoveries' | 'discoveri' |
'Discovering' | 'discov' |
这些结果看起来有点不一致。'Discovery'给你的'discoveri'时候为什么要给'Discovering'你'discov'?
词干不足和词干过度是词干可能出错的两种方式:
该波特词干算法从1979年的日期,所以它是上了年纪的侧一点。该雪球词干,也称为Porter2,是对原有的改进,也可以通过NLTK,所以你可以使用一个在自己的项目。还值得注意的是,Porter 词干分析器的目的不是生成完整的单词,而是查找单词的变体形式。
幸运的是,你还有其他一些方法可以将单词简化为它们的核心含义,例如词形还原,你将在本教程后面看到。但首先,我们需要涵盖词性。
Python NLTK 自然语言处理:标记词性
词性是一个语法术语,处理单词在句子中一起使用时所扮演的角色。标记词性或词性标记是根据词性标记文本中的单词的任务。
在英语中,有八个词类:
| 部分演讲 | 角色 | 例子 |
|---|---|---|
| 名词 | 是人、地点或事物 | 山, 百吉饼, 波兰 |
| 代词 | 代替名词 | 你,她,我们 |
| 形容词 | 提供有关名词的信息 | 高效、多风、多彩 |
| 动词 | 是一种行为还是一种存在状态 | 学习,就是,去 |
| 副词 | 提供有关动词、形容词或其他副词的信息 | 有效地,总是,非常 |
| 介词 | 提供有关名词或代词如何连接到另一个词的信息 | 从,大约,在 |
| 连词 | 连接另外两个单词或短语 | 所以,因为,和 |
| 欹 | 是感叹号 | 啊啊啊啊啊啊 |
一些来源还包括词性列表中的类别冠词(如“a”或“the”),但其他来源将它们视为形容词。NLTK 使用单词确定器来指代文章。
以下是如何导入 NLTK 的相关部分以标记词性:>>>
>>> from nltk.tokenize import word_tokenize
现在创建一些要标记的文本。你可以使用卡尔·萨根 (Carl Sagan) 的话:>>>
>>> sagan_quote = """
... If you wish to make an apple pie from scratch,
... you must first invent the universe."""
使用word_tokenize的话在该字符串分隔,并将它们存储在一个列表:>>>
>>> words_in_sagan_quote = word_tokenize(sagan_quote)
现在调用nltk.pos_tag()你的新单词列表:>>>
>>> import nltk
>>> nltk.pos_tag(words_in_sagan_quote)
[('If', 'IN'),
('you', 'PRP'),
('wish', 'VBP'),
('to', 'TO'),
('make', 'VB'),
('an', 'DT'),
('apple', 'NN'),
('pie', 'NN'),
('from', 'IN'),
('scratch', 'NN'),
(',', ','),
('you', 'PRP'),
('must', 'MD'),
('first', 'VB'),
('invent', 'VB'),
('the', 'DT'),
('universe', 'NN'),
('.', '.')]
引用中的所有单词现在都在一个单独的元组中,并带有一个表示其词性的标签。但是标签是什么意思?以下是获取标签列表及其含义的方法:>>>
>>> nltk.help.upenn_tagset()
该列表很长,但你可以随意展开下面的框进行查看。
POS 标签及其含义显示隐藏
以下是你可以用来开始使用 NLTK 的 POS 标签的摘要:
| 开头的标签 | 处理 |
|---|---|
JJ | 形容词 |
NN | 名词 |
RB | 副词 |
PRP | 代词 |
VB | 动词 |
现在你知道 POS 标签的含义,你可以看到你的标签相当成功:
'pie'被标记NN是因为它是一个单数名词。'you'被标记PRP是因为它是人称代词。'invent'被标记VB是因为它是动词的基本形式。
但是 NLTK 将如何处理在一个基本上是胡言乱语的文本中标记词性呢?Jabberwocky是一首胡说八道的诗,从技术上讲并没有多大意义,但它的写作方式仍然可以向说英语的人传达某种意义。
NLTK实现自然语言处理示例:制作一个字符串来保存这首诗的摘录:>>>
>>> jabberwocky_excerpt = """
... 'Twas brillig, and the slithy toves did gyre and gimble in the wabe:
... all mimsy were the borogoves, and the mome raths outgrabe."""
使用word_tokenize的词语的摘录分开,并将它们存储在一个列表:>>>
>>> words_in_excerpt = word_tokenize(jabberwocky_excerpt)
调用nltk.pos_tag()你的新单词列表:>>>
>>> nltk.pos_tag(words_in_excerpt)
[("'T", 'NN'),
('was', 'VBD'),
('brillig', 'VBN'),
(',', ','),
('and', 'CC'),
('the', 'DT'),
('slithy', 'JJ'),
('toves', 'NNS'),
('did', 'VBD'),
('gyre', 'NN'),
('and', 'CC'),
('gimble', 'JJ'),
('in', 'IN'),
('the', 'DT'),
('wabe', 'NN'),
(':', ':'),
('all', 'DT'),
('mimsy', 'NNS'),
('were', 'VBD'),
('the', 'DT'),
('borogoves', 'NNS'),
(',', ','),
('and', 'CC'),
('the', 'DT'),
('mome', 'JJ'),
('raths', 'NNS'),
('outgrabe', 'RB'),
('.', '.')]
接受的英语单词 like'and'和'the'分别被正确标记为连词和限定词。这个胡言乱语的词'slithy'被标记为形容词,这也是讲英语的人可能会根据诗的上下文做出的假设。一路走好,NLTK!
NLTK如何实现自然语言处理?词形还原
现在你已经掌握了词性,你可以回到词形还原。像词干提取一样,词形还原将单词简化为它们的核心含义,但它会给你一个完整的英语单词,它本身就有意义,而不仅仅是像'discoveri'.
注:一个引理是代表字的整组一个词,那组词被称为语义。
例如,如果你要在字典中查找单词“blending”,那么你需要查看“blend”的条目,但你会发现该条目中列出了“blending”。
在这个例子中,“blend”是词条,“blending”是词素的一部分。因此,当你对一个词进行词形还原时,你就是在将它简化为它的词缀。
以下是如何导入 NLTK 的相关部分以开始词形还原:>>>
>>> from nltk.stem import WordNetLemmatizer
创建一个 lemmatizer 以使用:>>>
>>> lemmatizer = WordNetLemmatizer()
让我们从词形还原一个复数名词开始:>>>
>>> lemmatizer.lemmatize("scarves")
'scarf'
"scarves"给了你'scarf',所以这已经比你用 Porter 词干分析器得到的要复杂一点,即'scarv'. 接下来,创建一个包含多个单词的字符串以进行词形还原:>>>
>>> string_for_lemmatizing = "The friends of DeSoto love scarves."
现在按单词标记该字符串:>>>
>>> words = word_tokenize(string_for_lemmatizing)
这是你的单词列表:>>>
>>> words
['The',
'friends',
'of',
'DeSoto',
'love'
'scarves',
'.']
创建一个包含words词形还原后的所有单词的列表:>>>
>>> lemmatized_words = [lemmatizer.lemmatize(word) for word in words]
这是你得到的清单:>>>
>>> lemmatized_words
['The',
'friend',
'of',
'DeSoto',
'love',
'scarf',
'.'
看起来是对的。复数'friends'和'scarves'变成单数'friend'和'scarf'。
但是,如果你将一个看起来与其引理非常不同的词引理化会发生什么?尝试词形还原"worst":>>>
>>> lemmatizer.lemmatize("worst")
'worst'
你得到了结果,'worst'因为lemmatizer.lemmatize()假设那"worst"是一个名词。你可以明确表示你想"worst"成为一个形容词:>>>
>>> lemmatizer.lemmatize("worst", pos="a")
'bad'
for 的默认参数pos是'n'名词,但你"worst"通过添加参数确保将其视为形容词pos="a"。结果,你得到了'bad',它看起来与你的原始词非常不同,并且与你使用词干时得到的完全不同。这是因为"worst"是形容词的最高级形式'bad',词形还原减少了最高级以及与它们的引理的比较级。
既然你知道如何使用 NLTK 来标记词性,你可以在词形还原之前尝试标记词,以避免混淆同形异义词或拼写相同但含义不同且可能是词性不同的词。
分块
分词可让你识别单词和句子,而组块可让你识别短语。
注意:甲短语是一个单词或一组单词的作品作为单个单元来执行语法功能。名词短语围绕名词构建。
这里有些例子:
- “一颗行星”
- “一个倾斜的星球”
- “一个快速倾斜的星球”
NLTK自然语言处理教程:分块使用 POS 标签对单词进行分组并将块标签应用于这些组。块不重叠,因此一个词的一个实例一次只能在一个块中。
以下是如何导入 NLTK 的相关部分以进行分块:>>>
>>> from nltk.tokenize import word_tokenize
在进行分块之前,你需要确保文本中的词性已被标记,因此创建一个用于词性标记的字符串。你可以使用指环王中的这句话:>>>
>>> lotr_quote = "It's a dangerous business, Frodo, going out your door."
现在按单词标记该字符串:>>>
>>> words_in_lotr_quote = word_tokenize(lotr_quote)
>>> words_in_lotr_quote
['It',
"'s",
'a',
'dangerous',
'business',
',',
'Frodo',
',',
'going',
'out',
'your',
'door',
'.']
现在你已经获得了 中所有单词的列表lotr_quote。
下一步是按词性标记这些词:>>>
>>> nltk.download("averaged_perceptron_tagger")
>>> lotr_pos_tags = nltk.pos_tag(words_in_lotr_quote)
>>> lotr_pos_tags
[('It', 'PRP'),
("'s", 'VBZ'),
('a', 'DT'),
('dangerous', 'JJ'),
('business', 'NN'),
(',', ','),
('Frodo', 'NNP'),
(',', ','),
('going', 'VBG'),
('out', 'RP'),
('your', 'PRP$'),
('door', 'NN'),
('.', '.')]
你已经获得了引用中所有单词的元组列表,以及它们的 POS 标签。为了分块,你首先需要定义一个分块语法。
注:一个块的语法是规则上的句子应该如何进行分块的组合。它经常使用正则表达式或正则表达式。
对于本教程,你无需了解正则表达式的工作原理,但如果你想处理文本,它们将来肯定会派上用场。
使用一个正则表达式规则创建块语法:>>>
>>> grammar = "NP: {<DT>?<JJ>*<NN>}"
NP代表名词短语。你可以在使用 Python进行自然语言处理—使用自然语言工具包分析文本的第 7 章中了解有关名词短语组块的更多信息。
根据你创建的规则,你的块:
- 从可选的 (
?) 限定符 ('DT') 开始 - 可以有任意数量的 (
*) 形容词 (JJ) - 以名词结尾 (
<NN>)
使用以下语法创建块解析器:>>>
>>> chunk_parser = nltk.RegexpParser(grammar)
现在试试你的报价:>>>
>>> tree = chunk_parser.parse(lotr_pos_tags)
你可以通过以下方式查看此树的可视化表示:>>>
>>> tree.draw()
这是视觉表示的样子:

你有两个名词短语:
'a dangerous business'有限定词、形容词和名词。'door'只有一个名词。
现在你了解了分块,是时候看看分块了。
Python NLTK 自然语言处理:Chinking
Chinking 与chunking 一起使用,但chunking 用于包含模式,chinking用于排除模式。
让我们重用你在分块部分中使用的引用。你已经有一个包含引用中每个单词及其词性标记的元组列表:>>>
>>> lotr_pos_tags
[('It', 'PRP'),
("'s", 'VBZ'),
('a', 'DT'),
('dangerous', 'JJ'),
('business', 'NN'),
(',', ','),
('Frodo', 'NNP'),
(',', ','),
('going', 'VBG'),
('out', 'RP'),
('your', 'PRP$'),
('door', 'NN'),
('.', '.')]
下一步是创建语法来确定要在块中包含和排除的内容。这一次,你将使用多个行,因为你将拥有多个规则。因为你使用的语法不止一行,所以你将使用三重引号 ( """):>>>
>>> grammar = """
... Chunk: {<.*>+}
... }<JJ>{"""
你的语法的第一条规则是{<.*>+}。此规则有面向内的花括号 ( {}),因为它用于确定要包含在块中的模式。在这种情况下,你希望包含所有内容:<.*>+.
你的语法的第二条规则是}<JJ>{。此规则有朝外的花括号 ( }{),因为它用于确定要在块中排除哪些模式。在这种情况下,你要排除形容词:<JJ>。
使用以下语法创建块解析器:>>>
>>> chunk_parser = nltk.RegexpParser(grammar)
现在用你指定的缝隙将你的句子分块:>>>
>>> tree = chunk_parser.parse(lotr_pos_tags)
结果是这棵树:>>>
>>> tree
Tree('S', [Tree('Chunk', [('It', 'PRP'), ("'s", 'VBZ'), ('a', 'DT')]), ('dangerous', 'JJ'), Tree('Chunk', [('business', 'NN'), (',', ','), ('Frodo', 'NNP'), (',', ','), ('going', 'VBG'), ('out', 'RP'), ('your', 'PRP$'), ('door', 'NN'), ('.', '.')])])
在这种情况下,('dangerous', 'JJ')被排除在块之外,因为它是一个形容词 ( JJ)。但是如果你再次获得图形表示会更容易看到:>>>
>>> tree.draw()
你将获得以下可视化表示tree:

在这里,你已经'dangerous'从块中排除了形容词,并留下了包含其他所有内容的两个块。第一个块包含出现在被排除的形容词之前的所有文本。第二个块包含被排除的形容词之后的所有内容。
现在你知道如何从块中排除模式,是时候研究命名实体识别 (NER) 了。
使用命名实体识别 (NER)
命名实体是指代特定位置、人员、组织等的名词短语。通过命名实体识别,你可以在文本中找到命名实体并确定它们是哪种命名实体。
以下是NLTK 书中的命名实体类型列表:
| 网元类型 | 例子 |
|---|---|
| 组织 | 乔治亚太平洋公司,世卫组织 |
| 人 | 埃迪·邦特,奥巴马总统 |
| 地点 | 墨累河,珠穆朗玛峰 |
| 日期 | 2008-06-29 六月 |
| 时间 | 凌晨 2 点 50 分,下午 1:30 |
| 钱 | 1.75亿加元,10.40英镑 |
| 百分 | 20%,18.75% |
| 设施 | 华盛顿纪念碑,巨石阵 |
| 普通教育 | 东南亚,中洛锡安 |
你可以使用nltk.ne_chunk()来识别命名实体。让我们lotr_pos_tags再次使用来测试一下:>>>
>>> nltk.download("maxent_ne_chunker")
>>> nltk.download("words")
>>> tree = nltk.ne_chunk(lotr_pos_tags)
现在来看看视觉表现:>>>
>>> tree.draw()
这是你得到的:

NLTK实现自然语言处理示例:看到如何Frodo被标记为PERSON?binary=True如果你只想知道命名实体是什么而不是它们是什么类型的命名实体,你也可以选择使用该参数:>>>
>>> tree = nltk.ne_chunk(lotr_pos_tags, binary=True)
>>> tree.draw()
现在你看到的Frodo是一个NE:

这就是你可以识别命名实体的方法!但是你可以更进一步,直接从文本中提取命名实体。创建一个字符串,从中提取命名实体。你可以使用《世界大战》中的这句话:>>>
>>> quote = """
... Men like Schiaparelli watched the red planet—it is odd, by-the-bye, that
... for countless centuries Mars has been the star of war—but failed to
... interpret the fluctuating appearances of the markings they mapped so well.
... All that time the Martians must have been getting ready.
...
... During the opposition of 1894 a great light was seen on the illuminated
... part of the disk, first at the Lick Observatory, then by Perrotin of Nice,
... and then by other observers. English readers heard of it first in the
... issue of Nature dated August 2."""
现在创建一个函数来提取命名实体:>>>
>>> def extract_ne(quote):
... words = word_tokenize(quote, language=language)
... tags = nltk.pos_tag(words)
... tree = nltk.ne_chunk(tags, binary=True)
... return set(
... " ".join(i[0] for i in t)
... for t in tree
... if hasattr(t, "label") and t.label() == "NE"
... )
使用此功能,你可以无重复地收集所有命名实体。为此,你可以按单词进行标记,将词性标签应用于这些单词,然后根据这些标签提取命名实体。因为你包含了binary=True,你将获得的命名实体将不会被更具体地标记。你只会知道它们是命名实体。
看看你提取的信息:>>>
>>> extract_ne(quote)
{'Lick Observatory', 'Mars', 'Nature', 'Perrotin', 'Schiaparelli'}
你错过了尼斯市,可能是因为 NLTK 将它解释为一个普通的英语形容词,但你仍然得到以下内容:
- 机构:
'Lick Observatory' - 一颗行星:
'Mars' - 一个出版物:
'Nature' - 人:
'Perrotin'、'Schiaparelli'
这是一些相当不错的品种!
获取要分析的文本
既然你已经使用小示例文本完成了一些文本处理任务,你就可以立即分析一堆文本了。一组文本称为语料库。NLTK 提供了多个语料库,涵盖从古腾堡计划主持的小说到美国总统就职演说的所有内容。
为了分析 NLTK 中的文本,你首先需要导入它们。这需要nltk.download("book"),这是一个相当大的下载:>>>
>>> nltk.download("book")
>>> from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
你现在可以访问一些线性文本(例如Sense and Sensibility和Monty Python and the Holy Grail)以及几组文本(例如聊天语料库和个人语料库)。人性是迷人的,所以让我们通过仔细查看交友语料库来看看我们能发现什么!
这个语料库是一个交友广告的集合,这是网上约会的早期版本。如果你想见一个人,那么你可以在报纸上放个广告,然后等待其他读者回复你。
如果你想学习如何让其他文本进行分析,那么你可以查看使用 Python进行自然语言处理的第 3 章– 使用自然语言工具包分析文本。
NLTK如何实现自然语言处理?使用索引
当你使用索引时,你可以看到每次使用一个词时,以及它的直接上下文。这可以让你了解一个词在句子级别的使用方式以及与它一起使用的词。
来看看这些寻找爱情的好人怎么说吧!个人语料库被称为text8,因此我们将.concordance()使用参数调用它"man":>>>
>>> text8.concordance("man")
Displaying 14 of 14 matches:
to hearing from you all . ABLE young man seeks , sexy older women . Phone for
ble relationship . GENUINE ATTRACTIVE MAN 40 y . o ., no ties , secure , 5 ft .
ship , and quality times . VIETNAMESE MAN Single , never married , financially
ip . WELL DRESSED emotionally healthy man 37 like to meet full figured woman fo
nth subs LIKE TO BE MISTRESS of YOUR MAN like to be treated well . Bold DTE no
eeks lady in similar position MARRIED MAN 50 , attrac . fit , seeks lady 40 - 5
eks nice girl 25 - 30 serious rship . Man 46 attractive fit , assertive , and k
40 - 50 sought by Aussie mid 40s b / man f / ship r / ship LOVE to meet widowe
discreet times . Sth E Subs . MARRIED MAN 42yo 6ft , fit , seeks Lady for discr
woman , seeks professional , employed man , with interests in theatre , dining
tall and of large build seeks a good man . I am a nonsmoker , social drinker ,
lead to relationship . SEEKING HONEST MAN I am 41 y . o ., 5 ft . 4 , med . bui
quiet times . Seeks 35 - 45 , honest man with good SOH & similar interests , f
genuine , caring , honest and normal man for fship , poss rship . S / S , S /
有趣的是,这十四场比赛中的最后三场与寻找一个诚实的人有关,具体来说:
SEEKING HONEST MANSeeks 35 - 45 , honest man with good SOH & similar interestsgenuine , caring , honest and normal man for fship , poss rship
让我们看看这个词是否有类似的模式"woman":>>>
>>> text8.concordance("woman")
Displaying 11 of 11 matches:
at home . Seeking an honest , caring woman , slim or med . build , who enjoys t
thy man 37 like to meet full figured woman for relationship . 48 slim , shy , S
rry . MALE 58 years old . Is there a Woman who would like to spend 1 weekend a
other interests . Seeking Christian Woman for fship , view to rship . SWM 45 D
ALE 60 - burly beared seeks intimate woman for outings n / s s / d F / ston / P
ington . SCORPIO 47 seeks passionate woman for discreet intimate encounters SEX
le dad . 42 , East sub . 5 " 9 seeks woman 30 + for f / ship relationship TALL
personal trainer looking for married woman age open for fun MARRIED Dark guy 37
rinker , seeking slim - medium build woman who is happy in life , age open . AC
. O . TERTIARY Educated professional woman , seeks professional , employed man
real romantic , age 50 - 65 y . o . WOMAN OF SUBSTANCE 56 , 59 kg ., 50 , fit
诚实问题只出现在第一场比赛中:
Seeking an honest , caring woman , slim or med . build
深入研究语料库并不能提供完整的图片,但看一眼并查看是否有任何突出之处仍然很有趣。
Python NLTK 自然语言处理:制作色散图
你可以使用分散图来查看特定单词出现的次数以及出现的位置。到目前为止,我们一直在寻找"man"and "woman",但看看这些词与其同义词相比的使用量会很有趣:>>>
>>> text8.dispersion_plot(
... ["woman", "lady", "girl", "gal", "man", "gentleman", "boy", "guy"]
... )
这是你得到的分散图:
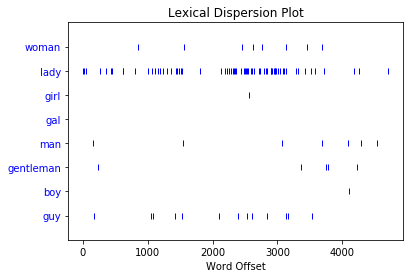
每条垂直的蓝线代表一个词的一个实例。每条水平的蓝线代表整个语料库。该图显示:
"lady"被使用得比"woman"or多得多"girl"。没有实例"gal"。"man"and"guy"被使用的次数相似,并且比"gentleman"or更常见"boy"。
当你想查看单词在文本或语料库中的显示位置时,可以使用离散图。如果你正在分析单个文本,这可以帮助你查看哪些单词显示在彼此附近。如果你正在分析按时间顺序组织的文本语料库,它可以帮助你了解哪些词在一段时间内或多或少地被使用。
继续以浪漫为主题,通过为Sense 和 Sensibility制作一个分散图,看看你能发现什么,即text2。简奥斯汀的小说讲了很多人的家,所以用几个家的名字做一个分散的情节:>>>
>>> text2.dispersion_plot(["Allenham", "Whitwell", "Cleveland", "Combe"])
这是你得到的情节:
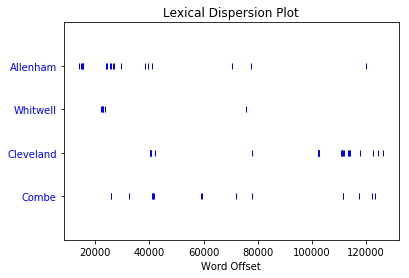
显然,艾伦汉姆在小说的前三分之一中被提到了很多,然后就不再出现了。另一方面,克利夫兰在前三分之二中几乎没有出现,但在后三分之一中出现了相当多的表现。这种分布反映了玛丽安和威洛比之间关系的变化:
- Allenham是 Willoughby 的恩人的家,当 Marianne 第一次对他感兴趣时,他经常出现。
- 克利夫兰是玛丽安去伦敦看威洛比后住的家,但事情出了问题。
色散图只是你可以为文本数据制作的一种可视化类型。你将了解的下一个是频率分布。
进行频率分布
通过频率分布,你可以检查文本中出现频率最高的单词。你需要开始使用import:>>>
>>> from nltk import FreqDist
FreqDist是 的子类collections.Counter。以下是创建整个交友广告语料库频率分布的方法:>>>
>>> frequency_distribution = FreqDist(text8)
>>> print(frequency_distribution)
<FreqDist with 1108 samples and 4867 outcomes>
由于1108样本和4867结果包含大量信息,因此请先缩小范围。以下是查看20语料库中最常用词的方法:>>>
>>> frequency_distribution.most_common(20)
[(',', 539),
('.', 353),
('/', 110),
('for', 99),
('and', 74),
('to', 74),
('lady', 68),
('-', 66),
('seeks', 60),
('a', 52),
('with', 44),
('S', 36),
('ship', 33),
('&', 30),
('relationship', 29),
('fun', 28),
('in', 27),
('slim', 27),
('build', 27),
('o', 26)]
你的频率分布中有很多停用词,但你可以像之前一样删除它们。创建一个包含所有text8不是停用词的词的列表:>>>
>>> meaningful_words = [
... word for word in text8 if word.casefold() not in stop_words
... ]
既然你已经拥有语料库中所有非停用词的列表,请进行频率分布:>>>
>>> frequency_distribution = FreqDist(meaningful_words)
看看20最常见的词:>>>
>>> frequency_distribution.most_common(20)
[(',', 539),
('.', 353),
('/', 110),
('lady', 68),
('-', 66),
('seeks', 60),
('ship', 33),
('&', 30),
('relationship', 29),
('fun', 28),
('slim', 27),
('build', 27),
('smoker', 23),
('50', 23),
('non', 22),
('movies', 22),
('good', 21),
('honest', 20),
('dining', 19),
('rship', 18)]
你可以将此列表转换为图表:>>>
>>> frequency_distribution.plot(20, cumulative=True)
这是你得到的图表:
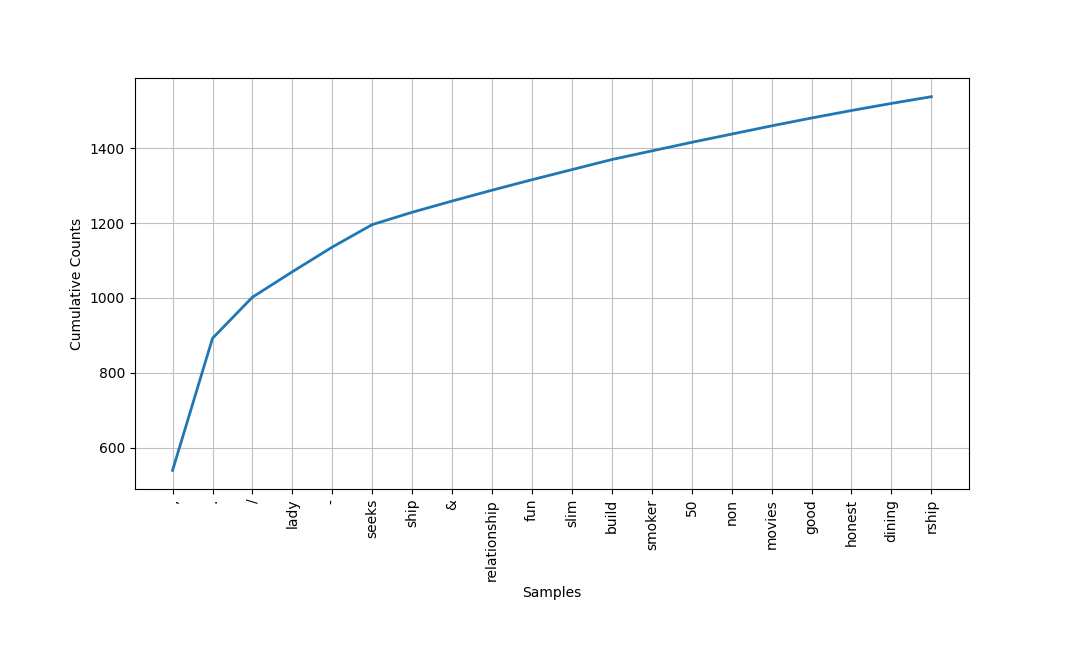
一些最常见的词是:
'lady''seeks''ship''relationship''fun''slim''build''smoker''50''non''movies''good''honest'
从你已经了解的关于写这些交友广告的人的情况来看,他们似乎确实对诚实感兴趣并且经常使用这个词'lady'。此外,'slim'和'build'都显示了相同的次数。当你学习索引时,你看到slim和build使用彼此接近,所以也许这两个词在这个语料库中经常一起使用。这给我们带来了搭配!
寻找搭配
甲搭配是字序列该数值显示常。如果你对英语中的常见搭配感兴趣,那么你可以查看一下The BBI Dictionary of English Word Combinations。这是一个方便的参考,你可以使用它来帮助你确保你的写作是地道的。以下是一些使用“树”一词的搭配示例:
- 语法树
- 家谱
- 决策树
要查看语料库中经常出现的单词对,你需要调用.collocations()它:>>>
>>> text8.collocations()
would like; medium build; social drinker; quiet nights; non smoker;
long term; age open; Would like; easy going; financially secure; fun
times; similar interests; Age open; weekends away; poss rship; well
presented; never married; single mum; permanent relationship; slim
build
slim build确实出现了,medium build和其他几个单词组合一样。虽然没有长时间在海滩上散步!
但是,如果你在对语料库中的单词进行词形还原后寻找搭配会发生什么?你是否会发现一些你第一次错过的单词组合,因为它们的版本略有不同?
NLTK实现自然语言处理示例:如果你按照前面的说明进行操作,那么你已经有了lemmatizer,但是你不能只调用collocations()任何数据类型,因此你需要做一些准备工作。首先创建 中所有单词的词形还原版本列表text8:>>>
>>> lemmatized_words = [lemmatizer.lemmatize(word) for word in text8]
但是为了让你能够完成迄今为止所见的语言处理任务,你需要使用以下列表制作NLTK 文本:>>>
>>> new_text = nltk.Text(lemmatized_words)
以下是如何查看你的 中的搭配new_text:>>>
>>> new_text.collocations()
medium build; social drinker; non smoker; long term; would like; age
open; easy going; financially secure; Would like; quiet night; Age
open; well presented; never married; single mum; permanent
relationship; slim build; year old; similar interest; fun time; Photo
pls
与你之前的搭配清单相比,这个新搭配少了一些:
weekends awayposs rship
quiet nights仍然出现在词形还原版本中的想法,quiet night. 你最近对搭配的搜索也带来了一些新闻:
year old建议用户经常提到年龄。photo pls建议用户经常请求一张或多张照片。
这就是你如何找到常见的单词组合以了解人们在谈论什么以及他们如何谈论它!
Python NLTK 自然语言处理总结
恭喜你迈出了NLP 的第一步!一个全新的非结构化数据世界现已开放供你探索。现在你已经了解了文本分析任务的基础知识,你可以出去寻找一些文本进行分析,看看你可以了解关于文本本身以及编写它们的人和它们所涉及的主题的内容。
NLTK如何实现自然语言处理?现在你知道如何:
- 查找要分析的文本
- 预处理你的文本以进行分析
- 分析你的文字
- 根据你的分析创建可视化
NLTK自然语言处理教程 - 对于下一步,你可以使用 NLTK 来分析文本以查看其中表达的情绪是积极的还是消极的。要了解有关情感分析的更多信息,请查看情感分析:使用 Python 的 NLTK 库的第一步。如果你想更深入地了解NLTK 的具体细节,那么你可以按照自己的方式使用 Python进行自然语言处理—使用自然语言工具包分析文本。
现在走出去,找到一些文本来分析!

