Web 抓取是从 Internet 收集信息的过程。甚至复制和粘贴你最喜欢的歌曲的歌词也是一种网络抓取形式!但是,“网页抓取”一词通常指的是涉及自动化的过程。一些网站不喜欢自动抓取工具收集他们的数据,而另一些网站则不介意。
如果你出于教育目的而恭敬地抓取页面,那么你不太可能遇到任何问题。尽管如此,在开始大型项目之前,自己做一些研究并确保没有违反任何服务条款是个好主意。
不稳定的脚本是一个现实的场景,因为许多网站都在积极开发中。一旦站点的结构发生变化,你的抓取工具可能无法正确导航站点地图或找到相关信息。好消息是,对网站的许多更改都是小的和增量的,因此你可能只需进行最少的调整就可以更新你的抓取工具。
但是,请记住,由于 Internet 是动态的,你将构建的抓取工具可能需要不断维护。你可以设置持续集成以定期运行抓取测试,以确保你的主脚本不会在你不知情的情况下中断。
网页抓取的替代方案:API
一些网站提供商提供应用程序编程接口 (API),允许你以预定义的方式访问他们的数据。使用 API,你可以避免解析 HTML。相反,你可以使用JSON和 XML等格式直接访问数据。HTML 主要是一种以视觉方式向用户呈现内容的方式。
当你使用 API 时,该过程通常比通过网络抓取收集数据更稳定。那是因为开发人员创建的 API 是供程序而不是人眼使用的。
网站的前端呈现可能经常发生变化,但网站设计的这种变化不会影响其 API 结构。API 的结构通常更持久,这意味着它是更可靠的站点数据来源。
但是,API也可能会发生变化。多样性和持久性的挑战适用于 API,就像它们适用于网站一样。此外,如果提供的文档缺乏质量,则自己检查 API 的结构要困难得多。
使用 API 收集信息所需的方法和工具超出了本教程的范围。要了解更多信息,请查看Python 中的 API 集成。
抓取虚假的 Python 工作站点
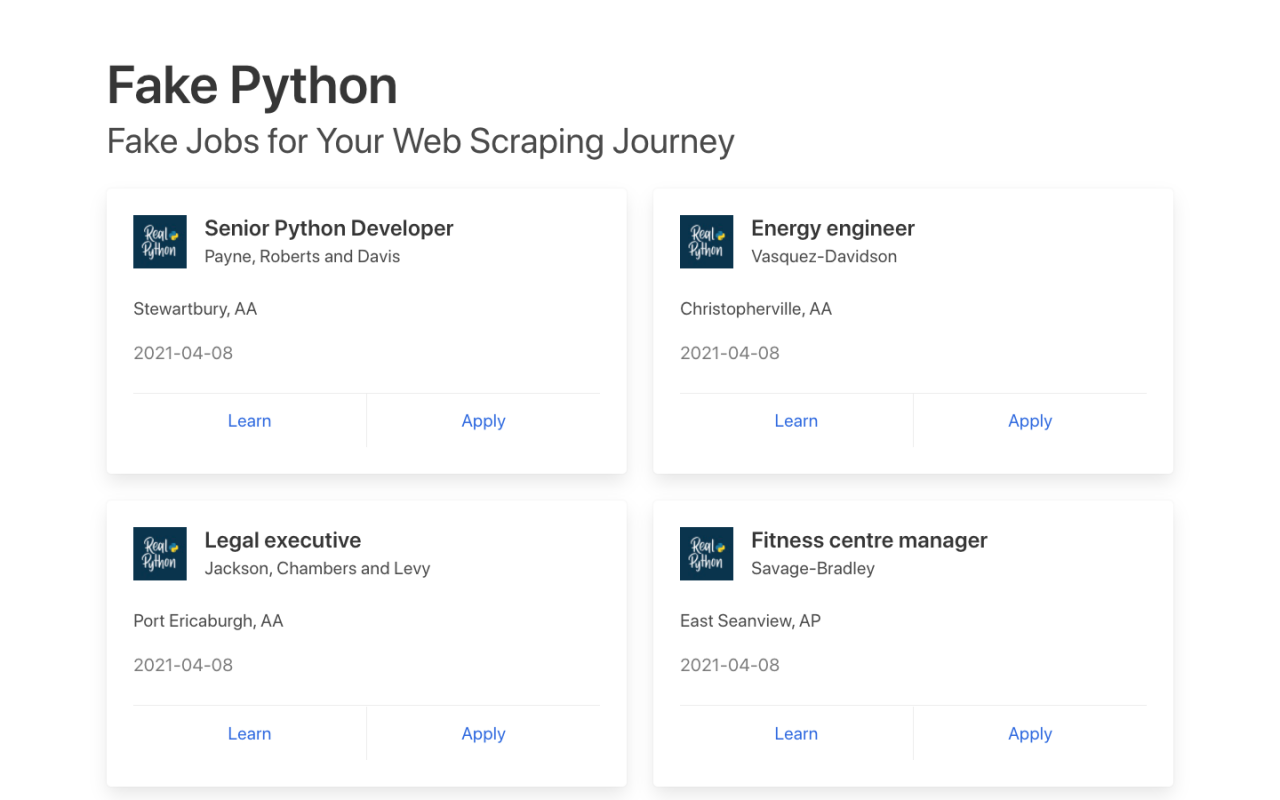
在本教程中,你将构建一个 Web 抓取工具,从Fake Python Jobs站点获取 Python 软件开发人员的职位列表。这是一个带有虚假招聘信息的示例网站,你可以随意抓取这些信息以训练你的技能。你的网络抓取工具将解析网站上的 HTML 以挑选相关信息并针对特定词过滤该内容。
注意:本教程的先前版本侧重于抓取Monster工作板,此后已更改并且不再提供静态 HTML 内容。本教程的更新版本侧重于自托管静态站点,该站点保证保持不变,并为你提供一个可靠的操场来练习网络抓取所需的技能。
你可以抓取 Internet 上可以查看的任何站点,但这样做的难度取决于站点。本教程向你介绍了网页抓取,以帮助你了解整个过程。然后,你可以对要抓取的每个网站应用相同的过程。
在整个教程中,你还会遇到一些练习块。你可以单击以展开它们并通过完成那里描述的任务来挑战自己。
接下来,你将需要了解更多有关如何构建数据以进行显示的信息。你需要了解页面结构,才能从接下来的步骤之一中收集的 HTML 响应中选择你想要的内容。
开发人员工具可以帮助你了解网站的结构。所有现代浏览器都安装了开发人员工具。在本节中,你将了解如何使用 Chrome 中的开发人员工具。该过程将与其他现代浏览器非常相似。
Beautiful Soup网络爬虫示例:在 macOS 上的 Chrome 中,你可以通过选择View → Developer → Developer Tools通过菜单打开开发者工具。在 Windows 和 Linux 上,你可以通过单击右上角的菜单按钮 ( ⋮) 并选择更多工具→开发人员工具来访问它们。你还可以通过右键单击页面并选择“检查”选项或使用键盘快捷键来访问你的开发人员工具:
苹果:Cmd+ Alt+I
Windows/Linux:Ctrl+Shift+I
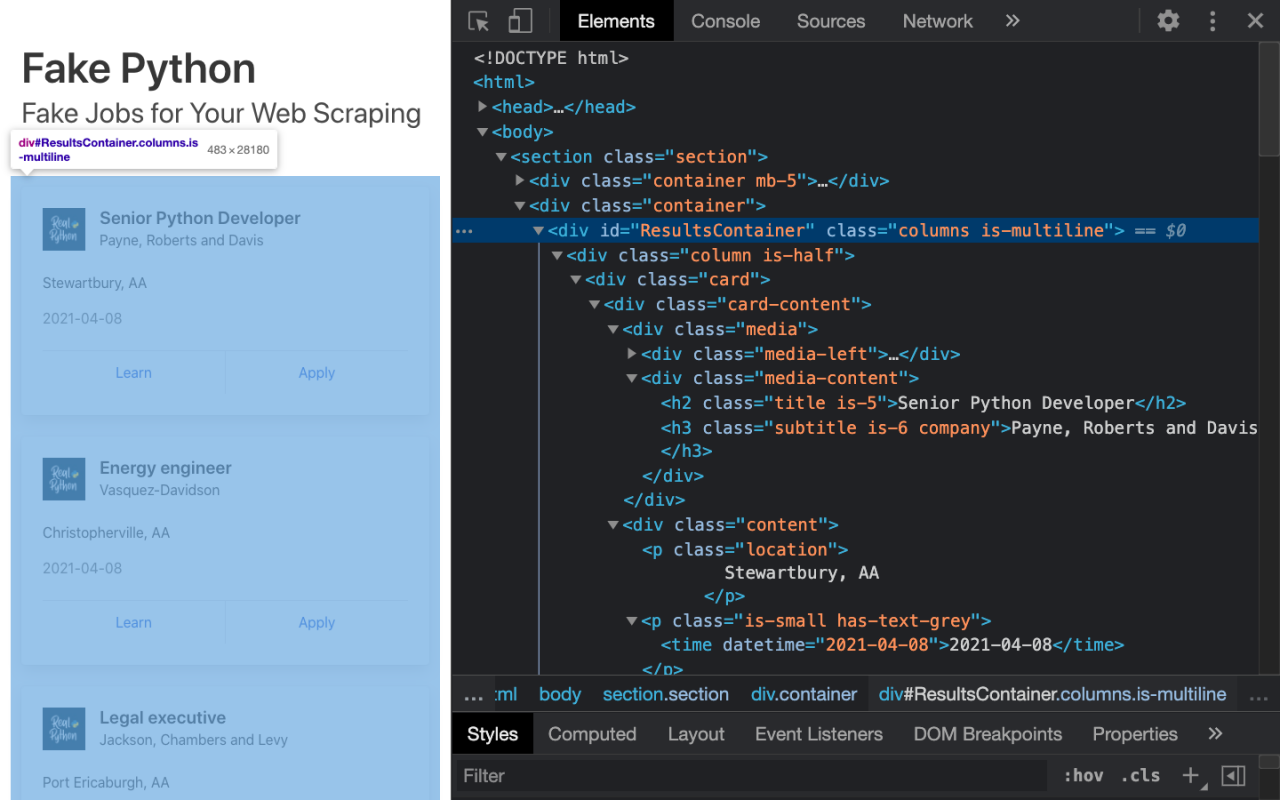
开发人员工具允许你以交互方式探索站点的文档对象模型 (DOM)以更好地了解你的来源。要深入了解页面的 DOM,请在开发人员工具中选择Elements选项卡。你将看到一个包含可点击 HTML 元素的结构。你可以直接在浏览器中展开、折叠甚至编辑元素:
右侧的 HTML 表示你可以在左侧看到的页面结构。
你可以将浏览器中显示的文本视为该页面的 HTML 结构。如果你有兴趣,那么你可以在CSS-TRICKS上阅读有关 DOM 和 HTML 之间差异的更多信息。
当你右键单击页面上的元素时,你可以选择“检查”以缩放到它们在 DOM 中的位置。你还可以将鼠标悬停在右侧的 HTML 文本上,然后查看页面上的相应元素亮起。
单击以展开特定任务的练习块以练习使用你的开发人员工具:
练习:探索 HTML显示隐藏
四处玩耍和探索!你对正在使用的页面了解得越多,抓取它就越容易。但是,不要被所有的 HTML 文本弄得不知所措。你将利用编程的力量逐步穿越这个迷宫并精心挑选与你相关的信息。
将你的头包裹在很长的 HTML 代码块中可能具有挑战性。为了更容易阅读,你可以使用HTML 格式化程序来自动清理它。良好的可读性有助于你更好地理解任何代码块的结构。虽然它可能有助于也可能不会帮助改进 HTML 格式,但它总是值得一试。
注意:请记住,每个网站的外观都不同。这就是为什么在继续之前有必要检查和了解你当前正在使用的站点的结构的原因。
你将遇到的 HTML 有时会令人困惑。幸运的是,此工作板的 HTML 对你感兴趣的元素具有描述性类名称:
class="title is-5" 包含职位发布的标题。
class="subtitle is-6 company" 包含提供该职位的公司名称。
class="location" 包含你将工作的位置。
如果你在一大堆 HTML 中迷失了方向,请记住,你始终可以返回浏览器并使用开发人员工具以交互方式进一步探索 HTML 结构。
到目前为止,你已经成功地利用了 Pythonrequests库的强大功能和用户友好设计。仅用几行代码,你就成功地从 Web 中抓取了静态 HTML 内容并使其可用于进一步处理。
但是,在抓取网站时可能会遇到更具挑战性的情况。在你学习如何从刚刚抓取的 HTML 中挑选相关信息之前,你将快速了解其中两个更具挑战性的情况。
添加突出显示的两行代码后,你将创建一个 Beautiful Soup 对象page.content,该对象将,即你之前抓取的 HTML 内容,作为其输入。
注意:你将希望通过page.content而不是page.text避免字符编码问题。该.content属性保存原始字节,可以比你之前使用该.text属性打印的文本表示更好地解码。
第二个参数"html.parser"确保你对 HTML 内容使用适当的解析器。
按 ID 查找元素
在 HTML 网页中,每个元素都可以id分配一个属性。顾名思义,该id属性使元素在页面上唯一可识别。你可以通过按 ID 选择特定元素来开始解析你的页面。
切换回开发人员工具并确定包含所有职位发布的 HTML 对象。通过将鼠标悬停在页面的部分上并使用右键单击Inspect来探索。
注意:定期切换回浏览器并使用开发人员工具交互式浏览页面会有所帮助。这有助于你了解如何找到你正在寻找的确切元素。
你要查找的元素是具有值为<div>的id属性"ResultsContainer"。它还有一些其他属性,但以下是你要查找的内容的要点:
<div id="ResultsContainer">
<!-- all the job listings -->
</div>
Beautiful Soup 允许你通过 ID 查找特定的 HTML 元素:
results = soup.find(id="ResultsContainer")
为了更容易查看,你可以在打印时美化任何 Beautiful Soup 对象。如果你调用上面刚刚分配.prettify()的results变量,那么你将看到包含在以下内容中的所有 HTML <div>:
print(results.prettify())
当你使用元素的 ID 时,你可以从 HTML 的其余部分中挑选一个元素。现在,你只能使用页面 HTML 的这一特定部分。汤好像变稀了!然而,它仍然非常密集。
按 HTML 类名查找元素
你已经看到每个职位发布都包含在一个<div>带有 class的元素中card-content。现在,你可以使用新对象调用results并仅选择其中的职位发布。毕竟,这些是你感兴趣的 HTML 部分!你可以在一行代码中执行此操作:
for job_element in job_elements:
title_element = job_element.find("h2", class_="title")
company_element = job_element.find("h3", class_="company")
location_element = job_element.find("p", class_="location")
print(title_element.text.strip())
print(company_element.text.strip())
print(location_element.text.strip())
print()
结果最终看起来好多了:
Senior Python Developer
Payne, Roberts and Davis
Stewartbury, AA
Energy engineer
Vasquez-Davidson
Christopherville, AA
Legal executive
Jackson, Chambers and Levy
Port Ericaburgh, AA
python_jobs = results.find_all(
"h2", string=lambda text: "python" in text.lower()
)
python_job_elements = [
h2_element.parent.parent.parent for h2_element in python_jobs
]
你添加了一个列表推导式,它对你通过 lambda 表达式过滤获得的每个<h2>标题元素进行操作python_jobs。你正在选择每个<h2>标题元素的父元素的父元素的父元素。这已经是三代了!
当你查看单个职位发布的 HTML 时,你发现这个具有类名的特定父元素card-content包含你需要的所有信息。
现在,你可以修改for循环中的代码以迭代父元素:
for job_element in python_job_elements:
# -- snip --
当你再次运行脚本时,你会看到你的代码再次可以访问所有相关信息。那是因为你现在循环的是<div class="card-content">元素,而不仅仅是<h2>标题元素。
使用.parent每个 Beautiful Soup 对象附带的属性,你可以直观地浏览 DOM 结构并处理所需的元素。你还可以以类似的方式访问子元素和同级元素。阅读导航树以获取更多信息。
从 HTML 元素中提取属性
此时,你的 Python 脚本已经抓取了该站点并过滤了其 HTML 以查找相关职位发布。做得好!但是,仍然缺少申请工作的链接。
在检查页面时,你会在每张卡片的底部发现两个链接。如果你以与处理其他元素相同的方式处理链接元素,你将不会获得你感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果你运行此代码片段,那么你将获得链接文本Learn而Apply不是关联的 URL。
这是因为该.text属性只留下 HTML 元素的可见内容。它去除了所有 HTML 标签,包括包含 URL 的 HTML 属性,只留下链接文本。要改为获取 URL,你需要提取 HTML 属性之一的值而不是丢弃它。
链接元素的 URL 与href属性相关联。你要查找的特定 URL是单个职位发布的 HTML 底部href第二个<a>标签的属性值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
在此代码段中,你首先从每个过滤后的职位发布中获取所有链接。然后你提取href包含 URL的属性,使用["href"]并将其打印到你的控制台。
在下面的练习块中,你可以找到挑战的说明以优化你收到的链接结果:
练习:优化你的结果显示隐藏
单击解决方案块以阅读本练习的可能解决方案:
解决方案:优化你的结果显示隐藏
你也可以使用相同的方括号表示法来提取其他 HTML 属性。