
本教程解释了如何使用WEKA Explorer数据可视化、K-means 聚类分析和关联规则挖掘:
在上一教程中,我们了解了决策树的 WEKA 数据集、分类器和 J48 算法。
正如我们之前看到的,WEKA 是一种开源数据挖掘工具,许多研究人员和学生使用它来执行许多机器学习任务。用户还可以构建他们的机器学习方法并在 WEKA 目录中提供的样本数据集上进行实验。
WEKA可视化分析可以使用示例数据集或用户制作的 .arff、.csv 格式的数据集来执行。
关联规则挖掘是使用 Apriori 算法进行的。它是 WEKA 提供的唯一用于执行频繁模式挖掘的算法。
WEKA聚类分析:WEKA 中有许多算法来执行聚类分析,例如 FartherestFirst、FilteredCluster 和 HierachicalCluster 等。其中,我们将使用 SimpleKmeans,这是最简单的聚类方法。
你会学到什么:
- 使用 WEKA Explorer 挖掘关联规则
- 关联规则挖掘
- 支持和信心
- 使用 WEKA Explorer 实现
- 使用 WEKA Explorer 的 K-means 算法
- 什么是聚类分析
- 什么是 K 均值聚类
- K-Mean 聚类算法如何工作
- 使用 WEKA 的 K-means 聚类实现
- 使用 WEKA 实现数据可视化
- 数据可视化
- 使用 WEKA Explorer 进行数据可视化
- 结论
使用 WEKA Explorer 挖掘关联规则
让我们看看如何使用 WEKA Explorer 实现关联规则挖掘。
关联规则挖掘
它由 Srikant 和 Aggarwal 于 1994 年开发和设计。它帮助我们在数据中找到模式。它是一个数据挖掘过程,用于查找一起出现的特征或相关的特征。
关联规则的应用包括Market Basket Analysis,用于分析单个篮子中购买的商品;交叉营销,与其他增加我们业务产品价值的企业合作,如汽车经销商和石油公司。
在大数据集中找到频繁项集后,挖掘关联规则。这些数据集是使用 Apriori 和 FP Growth 等挖掘算法找到的。频繁项集挖掘使用支持和置信度量来挖掘数据。
支持和信心
支持度衡量在一次交易(例如面包和黄油)中同时购买两件商品的概率。 信心是衡量两个项目一个接一个购买但不是一起购买的概率的度量,例如笔记本电脑和计算机防病毒软件。
假设最小阈值支持和最小阈值置信度值来修剪事务并找出最常出现的项集。
使用 WEKA Explorer 实现
WEKA 包含用于学习WEKA关联规则挖掘的Apriori 算法的实现。Apriori 仅适用于二进制属性、分类数据(名义数据),因此,如果数据集包含任何数值,则首先将它们转换为名义数据。
Apriori 找出具有最小支持度和置信度阈值的所有规则。
请按照以下步骤操作:
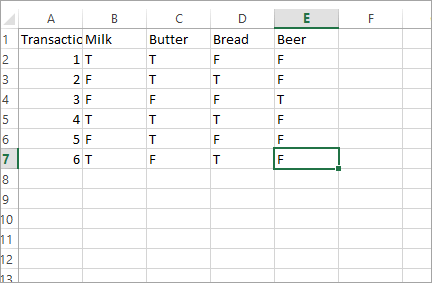
#1)准备一个excel文件数据集,命名为“ apriori.csv ”。
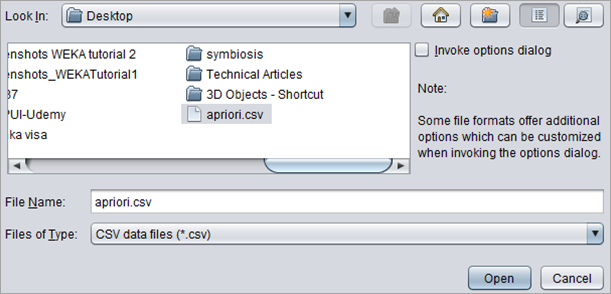
#2)打开 WEKA Explorer 并在 Preprocess 选项卡下选择“apriori.csv”文件。
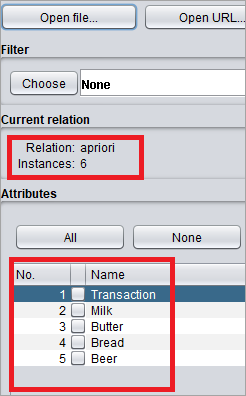
#3)该文件现在被加载到 WEKA Explorer 中。
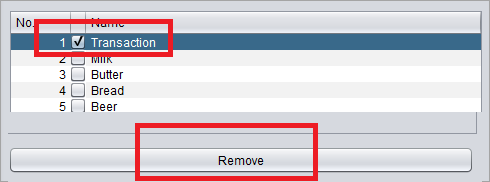
#4)通过选中复选框并单击删除来删除交易字段,如下图所示。现在将文件保存为“aprioritest.arff”。
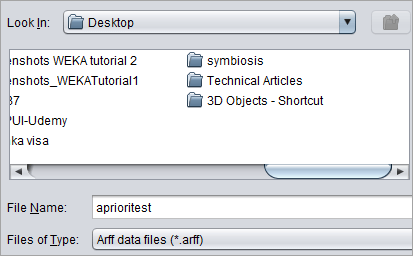
#5)转到关联选项卡。可以从这里挖掘先验规则。
#6)单击选择以设置支持度和置信度参数。 可以在这里设置的各种参数有:
- “ lowerBoundMinSupport ”和“ upperBoundMinSupport ”,这是我们的算法将工作的支持水平区间。
- Delta是支撑的增量。在这种情况下,0.05 是从 0.1 到 1 的支持增量。
- metricType可以是“Confidence”、“Lift”、“Leverage”和“Conviction”。这告诉我们如何对关联规则进行排序。通常,选择 Confidence。
- numRules告诉要挖掘的关联规则的数量。默认情况下,它设置为 10。
- 重要性级别描述了置信水平的重要性。
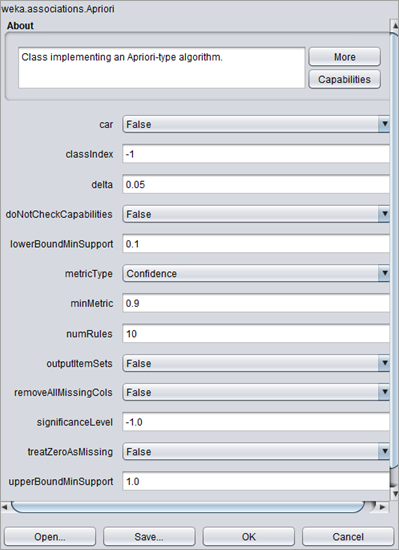
#7)选择按钮旁边的文本框,显示“ Apriori-N-10-T-0-C-0.9-D 0.05-U1.0-M0.1-S-1.0-c-1 ”,它描绘了在设置选项卡中为算法设置的汇总规则。
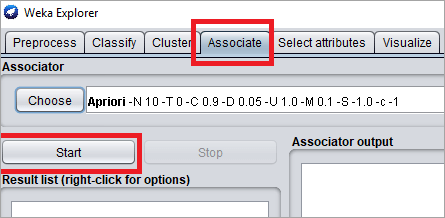
#8)点击开始按钮。关联规则在右侧面板中生成。该面板由 2 个部分组成。首先是算法,选择运行的数据集。第二部分显示先验信息。
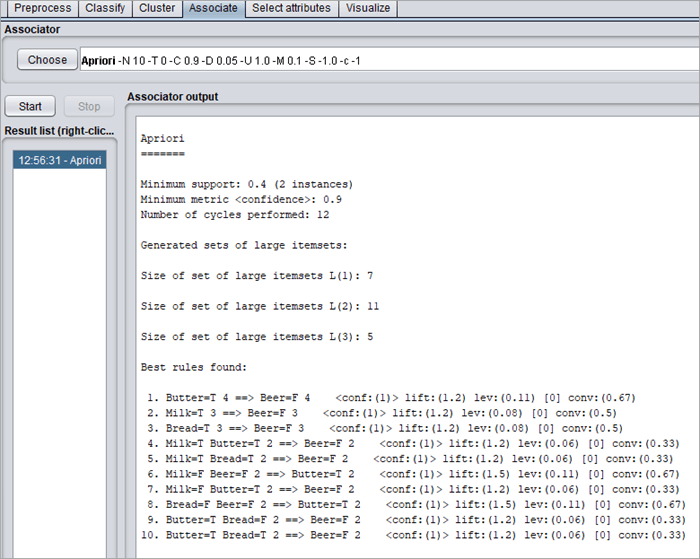
让我们了解右侧面板中的运行信息:
- Scheme 使用了我们 Apriori。
- 实例和属性:它有 6 个实例和 4 个属性。
- 最小支持度和最小置信度分别为 0.4 和 0.9。在 6 个实例中,找到了 2 个具有最小支持的实例,
- WEKA关联规则挖掘执行的周期数为 12。
- 生成的大项集为 3:L(1)、L(2)、L(3),但由于它们的大小分别为 7、11 和 5,因此未对其进行排序。
- 找到的规则进行排名。这些规则的解释如下:
- Butter T 4 => Beer F 4:表示在 6 个中,有 4 个实例表明对于黄油是真的,啤酒是假的。这给出了很强的关联。置信水平为 0.1。
输出
可以使用 WEKA Explorer 和 Apriori 算法挖掘关联规则。该算法可以应用于 WEKA 目录中可用的所有类型的数据集以及用户制作的其他数据集。支持度和置信度等参数可以使用算法的设置窗口进行设置。
使用 WEKA Explorer 的 K-Means 算法
让我们看看如何使用 WEKA Explorer 实现 K-means 算法进行聚类。
WEKA聚类分析:什么是聚类分析
聚类算法是无监督学习算法,用于创建具有相似特征的数据组。它将具有相似性的对象聚合到组和子组中,从而导致数据集的分区。聚类分析是将数据集分成子集的过程。这些子集称为簇,簇集称为聚类。
聚类分析用于许多应用程序,例如图像识别、模式识别、Web 搜索和安全性,以及商业智能(例如对具有相似喜好的客户进行分组)。
什么是 K 均值聚类
K 表示聚类是最简单的聚类算法。在 K-Clustering 算法中,数据集被划分为 K-clusters。目标函数用于找到分区的质量,以便相似的对象在一个集群中,而不同的对象在其他组中。
在这种方法中,找到一个簇的质心来表示一个簇。质心作为簇的中心,计算为簇内点的平均值。现在通过测量点和中心之间的欧几里德距离来发现聚类的质量。这个距离应该是最大的。
K-Mean 聚类算法如何工作
第 1 步:选择 K 的值,其中 K 是集群的数量。
步骤#2:迭代每个点并分配离它最近的中心的簇。当每个元素被迭代时,然后计算所有集群的质心。
第 3 步:迭代数据集中的每个元素并计算点与每个簇的质心之间的欧几里德距离。如果集群中存在与它不最近的任何点,则将该点重新分配给最近的集群,并在对数据集中的所有点执行此操作后,再次计算每个集群的质心。
步骤#4:执行步骤#3,直到在两次连续迭代之间没有发生新的分配。
WEKA Explorer数据可视化 - 使用 WEKA 的 K-means 聚类实现
使用Weka实现的步骤如下:
#1)打开 WEKA Explorer 并单击 Preprocess 选项卡中的 Open File。选择数据集“vote.arff”。
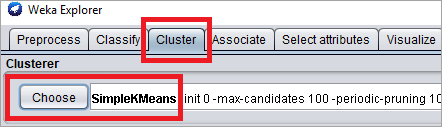
#2)转到“集群”选项卡,然后单击“选择”按钮。选择WEKA聚类分析方法为“SimpleKMeans”。
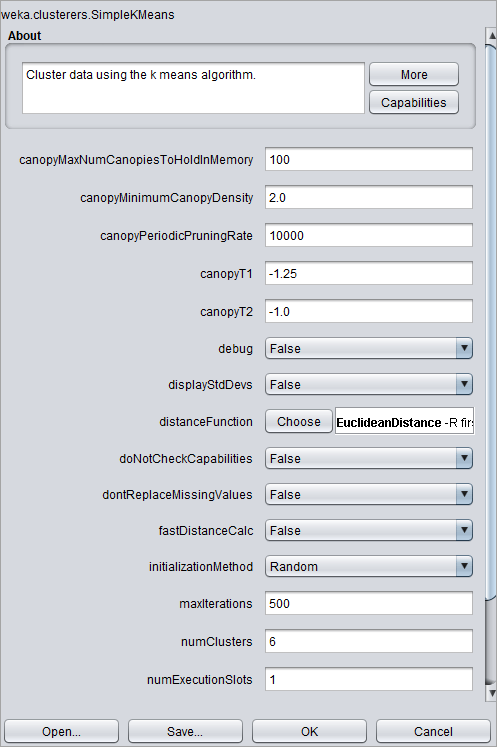
#3) 选择设置,然后设置以下字段:
- 作为欧几里得的距离函数
- 簇数为6。簇数越多,误差平方和越小。
- 种子为 10. of
单击“确定”并启动算法。
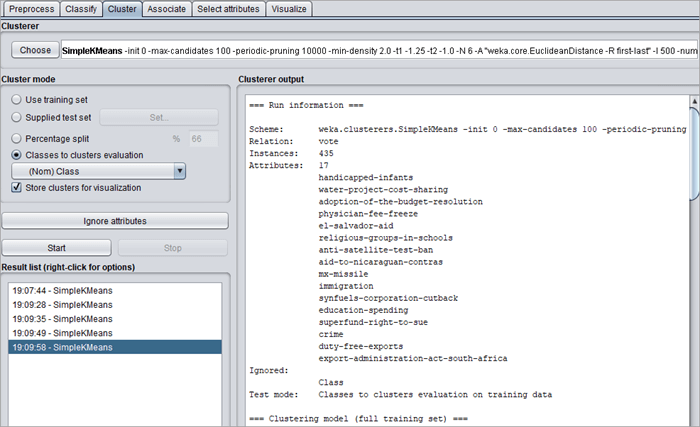
#4)单击左侧面板中的开始。算法在白屏上显示结果。我们来分析一下运行信息:
- 方案、关系、实例和属性描述了数据集的属性和使用的聚类方法。在这种情况下,vote.arff 数据集有 435 个实例和 13 个属性。
- 对于 Kmeans 集群,迭代次数为 5。
- 平方误差的总和为 1098.0。这个误差会随着簇数的增加而减少。
- 带有质心的 5 个最终聚类以表格的形式表示。在我们的例子中,簇的质心是 168.0、47.0、37.0、122.0.33.0 和 28.0。
- 集群实例表示落在集群中的总实例的数量和百分比。
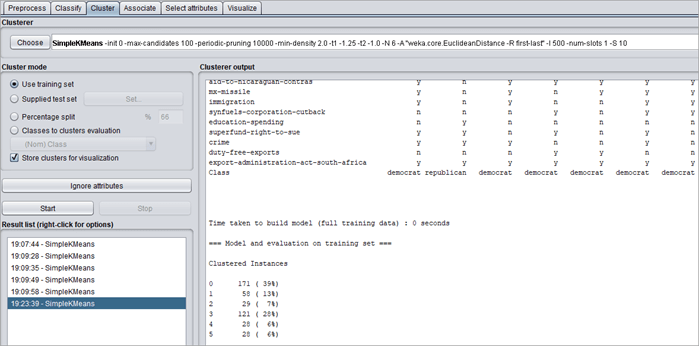
#5)选择“Classes to Clusters Evaluations”并单击“开始”。
该算法将类标签分配给集群。集群 0 代表共和党,集群 3 代表民主党。Incorrectly clustered instance 为 39.77%,可以通过忽略不重要的属性来减少。

#6)忽略不重要的属性。单击“忽略属性”按钮并选择要删除的属性。
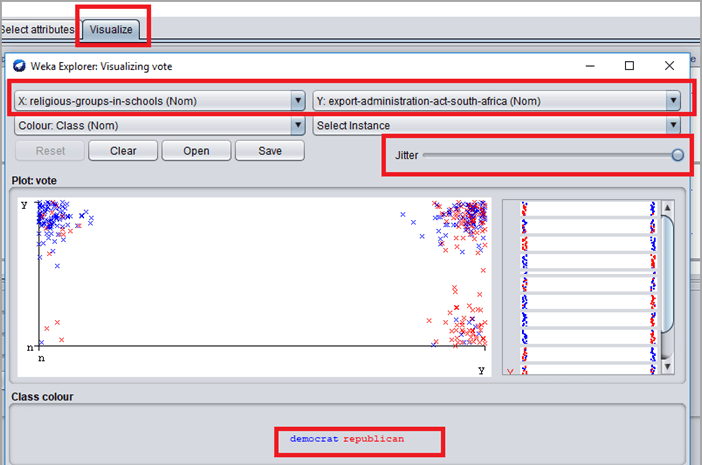
#7)使用“Visualize”选项卡可视化聚类算法结果。转到选项卡并单击任何框。将抖动移到最大值。
- X 轴和 Y 轴代表属性。
- 蓝色代表阶级标签民主党,红色代表阶级标签共和党。
- 抖动用于查看集群。
- 单击窗口右侧的框以更改 x 坐标属性并查看与其他属性相关的聚类。
输出
K均值聚类是一种简单的WEKA聚类分析方法。可以使用设置选项卡设置集群的数量。每个簇的质心计算为簇内所有点的平均值。随着簇数的增加,误差平方和减小。集群内的对象表现出相似的特征和属性。集群代表类标签。
使用 WEKA 实现数据可视化
WEKA可视化分析 - 数据可视化
通过图形和绘图来表示数据以清楚地理解数据的方法是数据可视化。
有多种表示数据的方法。其中一些如下:
#1) 面向像素的可视化:这里像素的颜色代表维度值。像素的颜色代表相应的值。
#2) 几何表示:多维数据集以 2D、3D 和 4D 散点图表示。
#3) 基于图标的可视化:数据使用切尔诺夫的脸和简笔画来表示。切尔诺夫的面孔利用人脑识别面部特征和它们之间的差异的能力。棒图使用 5 个棒图来表示多维数据。

#4) 分层数据可视化: 数据集使用树状图表示。它将分层数据表示为一组嵌套三角形。

使用WEKA Explorer数据可视化
使用 WEKA 的数据可视化是在 IRIS.arff 数据集上完成的。
WEKA可视化分析涉及的步骤如下:
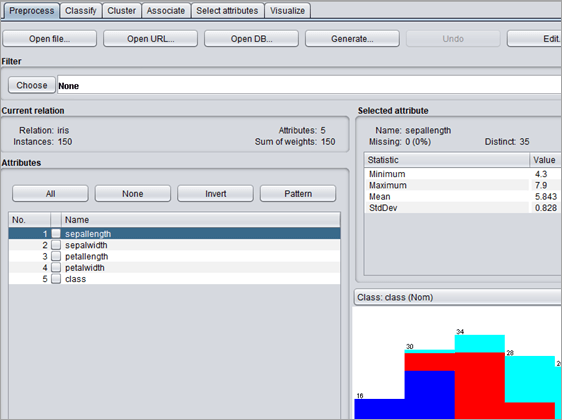
#1)转到预处理选项卡并打开 IRIS.arff 数据集。
#2)数据集有 4 个属性和 1 个类标签。该数据集中的属性是:
- Sepallength :类型 -numeric
- 分隔宽度:类型-数字
- Petalength:类型数字
- 花瓣宽度:类型数字
- 类别:类型-名义
#3)要可视化数据集,请转到 Visualize 选项卡。该选项卡显示属性图矩阵。绘制实例时,数据集属性标记在 x 轴和 y 轴上。可以放大具有x轴属性和y轴属性的框。
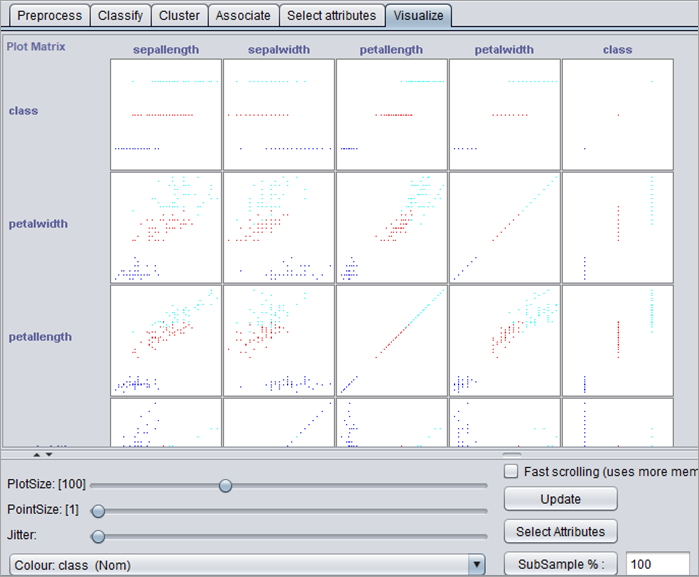
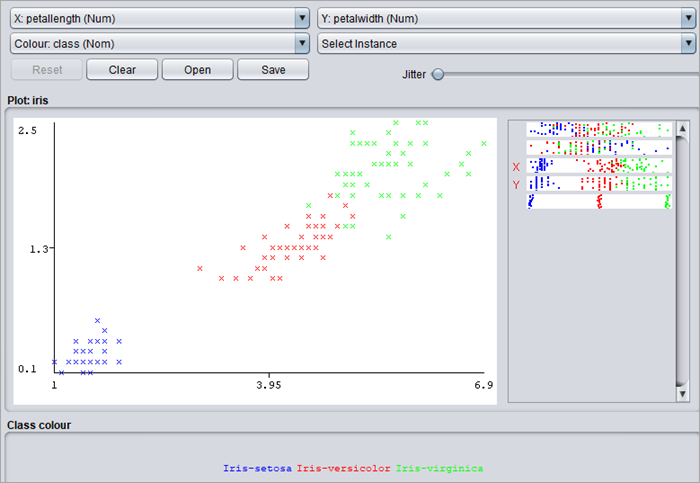
#4)点击图框放大。例如, x:花瓣长度和 y:花瓣宽度。类标签以不同的颜色表示。
- 类别标签- Iris-setosa:蓝色
- 类标签- Iris-versicolor: red
- 类标-Iris-virginica-green
这些颜色可以改变。要更改颜色,请单击底部的类标签,将出现一个颜色窗口。
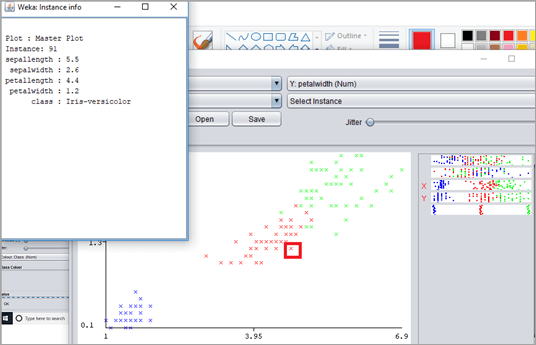
#5)单击图中“x”表示的实例。它将提供实例详细信息。例如:
- 实例编号: 91
- 分离长度: 5.5
- 分隔宽度: 2.6
- 拍长: 4.4
- 花瓣宽度: 1.2
- 类别:变色鸢尾
图中的某些点看起来比其他点更暗。这些点代表 2 个或更多具有相同类标签和相同属性值的实例,这些实例绘制在图上,例如花瓣宽度和花瓣长度。
下图表示一个点有 2 个实例信息。

#6) X 轴和 Y 轴属性可以从可视化图中的右侧面板更改。用户可以查看不同的图。
#7)抖动用于为绘图添加随机性。有时这些点会重叠。对于抖动,较暗的点代表多个实例。
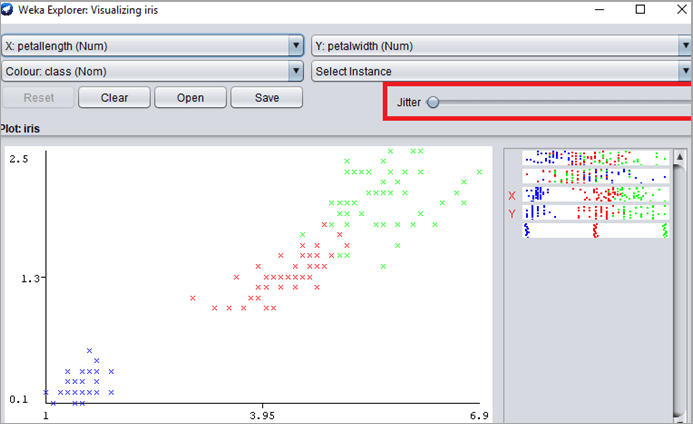
#8)为了更清晰地查看数据集并删除异常值,用户可以从下拉列表中选择一个实例。单击“选择实例”下拉列表。选择“矩形”。有了这个,用户将能够通过绘制矩形来选择图中的点。
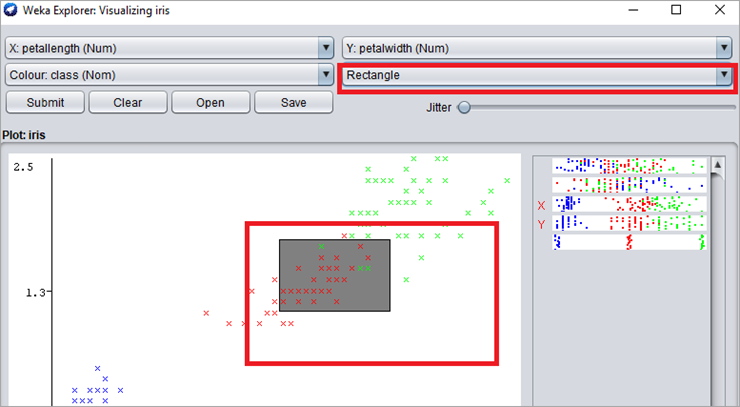
#9)点击“提交”。只会显示选定的数据集点,而其他点将从图表中排除。
下图显示了所选矩形中的点。该图表示只有 3 个类标签的点。用户可以点击“Save”保存数据集或点击“Reset”选择另一个实例。数据集将保存在单独的 .ARFF 文件中。
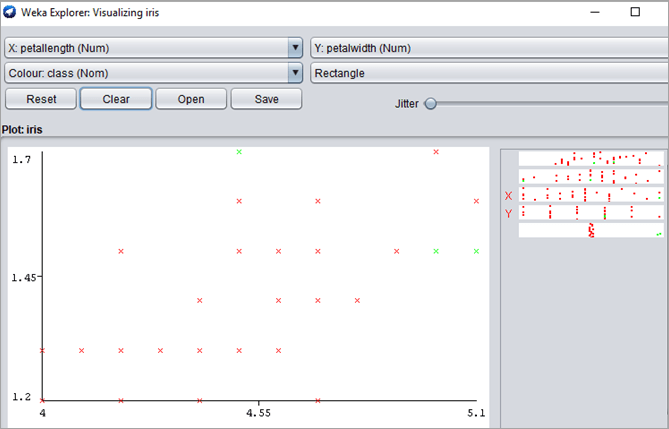
输出:
借助箱线图可以简化使用 WEKA 的数据可视化。用户可以查看任何级别的粒度。属性绘制在 X 轴和 y 轴上,而实例绘制在 X 轴和 Y 轴上。一些点表示多个实例,这些实例由深色点表示。
WEKA Explorer数据可视化总结
WEKA 是一种高效的数据挖掘工具,可以执行许多数据挖掘任务以及在数据集上试验新方法。WEKA 由新西兰怀卡托大学计算机科学系开发。
从超市购物到我们家中的安全摄像头,当今世界充斥着各种数据。数据挖掘使用这些原始数据,将其转换为信息以进行预测。WEKA 在 Apriori 算法的帮助下有助于WEKA关联规则挖掘。Apriori 是一种频繁模式挖掘算法,用于计算事务中项集的出现次数。
WEKA聚类分析是一种找出代表相似特征的数据聚类的技术。WEKA 提供了许多算法来执行聚类分析,其中高度使用 simplekmeans。
WEKA可视化分析:WEKA 中的数据可视化可以在 WEKA 目录中的所有数据集上执行。可以查看原始数据集以及其他算法(例如分类、聚类和关联)的其他结果数据集,可以使用 WEKA 进行可视化。

