本教程介绍了决策树的 WEKA 数据集、分类器和 J48 算法。还提供有关 Weka 样本 ARFF 数据集的信息:
在上一教程中,我们了解了 Weka 机器学习工具、其功能以及如何下载、安装和使用 Weka机器学习软件。
WEKA 是一个机器学习算法库,用于解决真实数据的数据挖掘问题。WEKA 还提供了一个环境来开发许多机器学习算法。它有一套工具可以执行各种数据挖掘任务,如数据分类、数据聚类、回归、属性选择、频繁项集挖掘等。
所有这些任务都可以在 WEKA 存储库中可用的 sample.ARFF 文件上执行,或者用户可以准备他们的数据文件。示例 .arff 文件是具有研究人员收集的内置历史数据的数据集。
在本教程中,我们将看到 WEKA 中的一些示例数据集,进行WEKA数据集详解、
WEKA分类器介绍以及
WEKA J48算法介绍,还将使用 weather.arff 数据集进行决策树算法数据挖掘。
你会学到什么:
- 探索 WEKA 数据集
- 样本 WEKA 数据集
- 隐形眼镜.arff
- 虹膜文件
- 糖尿病.arff
- 电离层.arff
- 回归数据集
- 什么是实值和名义属性
- Weka 决策树分类算法
- 结论
WEKA机器学习:探索 WEKA 数据集
WEKA 机器学习工具提供了一些示例数据集的目录。这些数据集可以直接加载到 WEKA 中,供用户立即开始开发模型。
可以从“C:\Program Files\Weka-3-8\data”链接浏览 WEKA 数据集。数据集采用 .arff 格式。
WEKA数据集详解:样本 WEKA 数据集
下表列出了 WEKA 中存在的一些示例数据集:
| 编号 |
样本数据集 |
| 1. |
航空公司.arff |
| 2. |
乳腺癌.arff |
| 3. |
隐形眼镜.arff |
| 4. |
处理器文件 |
| 5. |
cpu.with-vendor.arff |
| 6. |
信用-g.arff |
| 7. |
糖尿病.arff |
| 8. |
玻璃.arff |
| 9. |
甲减 |
| 10. |
离子球.arff |
| 11. |
虹膜2D.arff |
| 12. |
虹膜文件 |
| 13. |
劳动.arff |
| 14. |
ReutersCorn-train.arff |
| 15. |
ReutersCorn-test.arff |
| 16. |
路透社Grain-train.arff |
| 17. |
ReutersGrain-test.arff |
| 18. |
段挑战.arff |
| 19. |
段测试.arff |
| 20. |
大豆.arff |
| 21. |
超市.arff |
| 22. |
不平衡.arff |
| 23. |
投票.arff |
| 24. |
天气.数字.arff |
| 25. |
天气.nominal.arff |
让我们来看看其中的一些:
隐形眼镜.arff
contact-lens.arff 数据集是用于配戴隐形眼镜的数据库。它是由捐赠者 Benoit Julien 在 1990 年捐赠的。
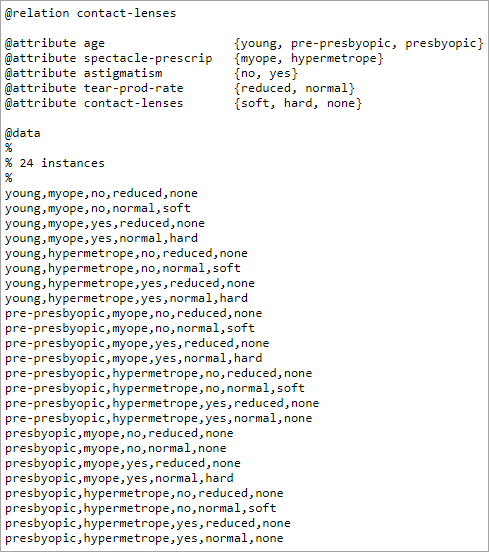 数据库:
数据库:这个数据库是完整的。此数据库中使用的示例完整且无噪音。该数据库有 24 个实例和 4 个属性。
属性:所有四个属性都是名义上的。没有缺失的属性值。
四个属性如下:
#1) 患者年龄:属性年龄可以取值:
#2) 眼镜处方:这个属性可以取值:
#3) 散光:这个属性可以取值
#4) 撕裂产生率:数值可以是
Class:这里定义了三个类标签。这些是:
- 患者应配戴硬性隐形眼镜。
- 患者应配戴软性隐形眼镜。
- 患者不应配戴隐形眼镜。
类分布:分类为类标签的实例如下:
|
班级标签 |
实例数 |
| 1. |
硬性隐形眼镜 |
4 |
| 2. |
软性隐形眼镜 |
5 |
| 3. |
没有隐形眼镜 |
15 |
虹膜文件
iris.arff 数据集由 Michael Marshall 于 1988 年创建。它是鸢尾植物数据库。
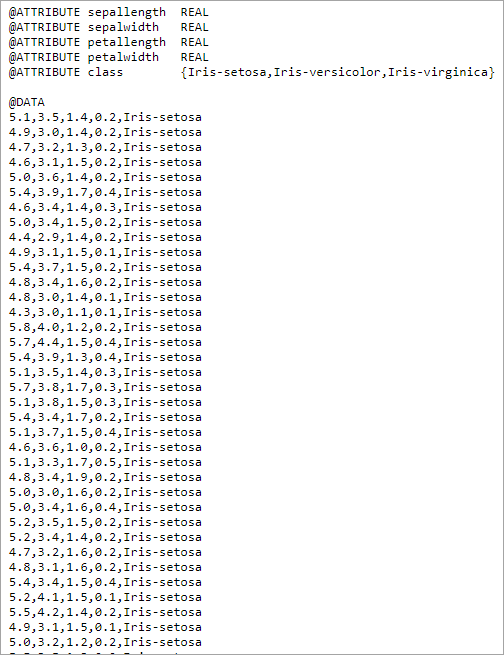 数据库:
数据库:该数据库用于模式识别。该数据集包含 3 个类,每类 50 个实例。每个类代表一种鸢尾植物。一类与其他 2 类线性可分离,但后者彼此不可线性分离。它可以预测观察结果属于 3 种鸢尾花中的哪一种。这称为多类分类数据集。
属性:它有 4 个数字属性、预测属性和类。没有缺失的属性。
属性是:
- 萼片长度厘米
- 萼片宽度厘米
- 花瓣长度厘米
- 花瓣宽度厘米
- 班级:
汇总统计:
|
最小 |
最大限度 |
意思 |
标清 |
类相关 |
| 萼片长度 |
4.3 |
7.9 |
5.84 |
0.83 |
0.7826 |
| 萼片宽度 |
2.0 |
4.4 |
3.05 |
0.43 |
-0.4194 |
| 花瓣长度 |
1.0 |
6.9 |
3.76 |
1.76 |
0.9490(高!) |
| 花瓣宽度 |
0.1 |
2.5 |
1.20 |
0.76 |
0.9565(高!) |
班级分布: 3个班级各占33.3%
其他一些数据集:
糖尿病.arff
该数据集的数据库是 Pima Indians Diabetes。该数据集预测患者在未来 5 年内是否容易患糖尿病。该数据集中的患者都是来自 Pima Indian Heritage 的至少 21 岁的女性。它有 768 个实例和 8 个数字属性以及一个类。这是一个二元分类数据集,其中预测的输出变量是包含两个类别的名义变量。
电离层.arff
这是一个流行的二元分类数据集。该数据集中的实例描述了来自大气层的雷达回波的特性。它用于预测电离层在何处具有某种结构。它有 34 个数字属性和一个类。
类属性是“好”还是“坏”,这是基于 34 个属性观察来预测的。接收到的信号通过以时间脉冲和脉冲数为参数的自相关函数进行处理。
WEKA机器学习:回归数据集
回归数据集可以从 WEKA 网页“
数据集集合”下载。它有 37 个从不同来源获得的回归问题。下载的文件将使用 .arff 格式的回归数据集创建数字/目录。
该目录中的流行数据集有: Longley 经济数据集 (longley.arff)、波士顿房价数据集 (housing.arff) 和哺乳动物睡眠数据集 (sleep.arff)。
现在让我们看看如何使用 WEKA 资源管理器识别数据集中的实值和名义属性。
什么是实值和名义属性
实值属性是仅包含实值的数字属性。这些是可测量的量。这些属性可以按区间缩放(例如温度)或比例缩放(例如平均值、中位数)。
名义属性表示名称或事物的某种表示。这些属性没有顺序,它们代表某个类别。
例如,颜色。
按照下面列出的步骤使用 WEKA 识别数据集中的真实值和名义属性。
#1)打开 WEKA 并选择“应用程序”下的“资源管理器”。
 #2)
#2)选择“预处理”选项卡。点击“打开文件”。使用 WEKA 用户,你可以访问 WEKA 示例文件。
 #3)
#3)从本地系统上存储的 WEKA3.8 文件夹中选择输入文件。选择预定义的 .arff 文件“credit-g.arff”文件,然后单击“打开”。
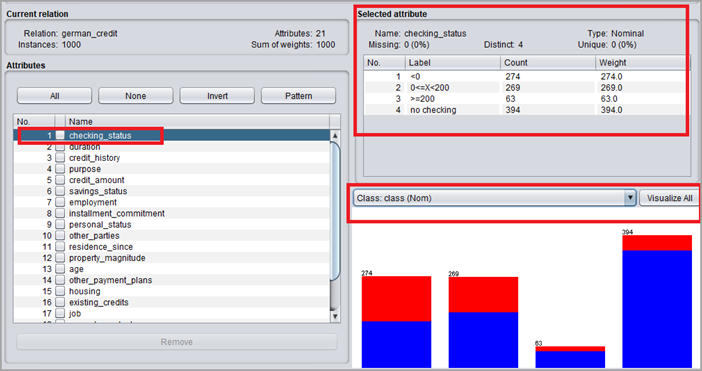
 #4)
#4)属性列表将在左侧面板上打开。选定的属性统计信息将与直方图一起显示在右侧面板上。
WEKA数据集详解 -
数据集分析:
在左侧面板中,当前关系显示:
- 关系名称: german_credit 是示例文件。
- 实例:数据集中的数据行数为 1000。
- 属性:数据集中的 21 个属性。
当前关系下方的面板显示属性的名称。
在右侧面板中,将显示选定的属性统计信息。选择
属性“checking_status”。
表明:
- 属性名称
- 缺失:数据集中属性的任何缺失值。在这种情况下为 0%。
- Distinct:该属性有 4 个不同的值。
- 类型:属性是名义类型,即不带任何数值。
- 计数:在1000个实例中,每个不同类标签的计数都写在计数列中。
- 直方图:它将显示属性的输出类标签。这个数据集中的类标签要么好要么坏。有 700 个好的实例(用蓝色标记)和 300 个坏的实例(用红色标记)。
- 对于标签 < 0,好或坏的实例数量几乎相同。
- 对于标签,0<= X<200,决策好的实例多于决策坏的实例。
- 类似地,对于标签 >= 200,最大实例是好的,并且没有检查标签具有更多决策好的实例。
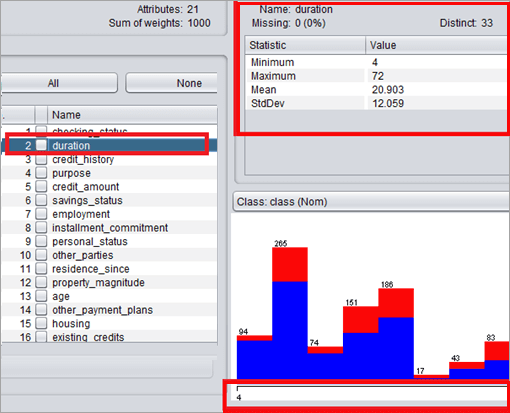
 对于下一个属性“持续时间”。
右侧面板显示:
对于下一个属性“持续时间”。
右侧面板显示:
- 名称:这是属性的名称。
- 类型:属性的类型是数字。
- 缺失值:该属性没有任何缺失值。
- Distinct:它在 1000 个实例中有 33 个不同的值。这意味着在 1000 个实例中它有 33 个不同的值。
- 唯一:它有 5 个不匹配的唯一值。
- 最小值:属性的最小值为 4。
- 最大值:该属性的最大值为 72。
- 均值:均值是将所有值相加除以实例。
- 标准差:属性持续时间的标准差。
- 直方图:直方图描绘了 4 个单位的持续时间,一个好的类出现的最大实例。随着持续时间增加到 38 个单位,好的类标签的实例数量会减少。持续时间达到 72 个单位,其中只有一个实例将决策归类为坏的。
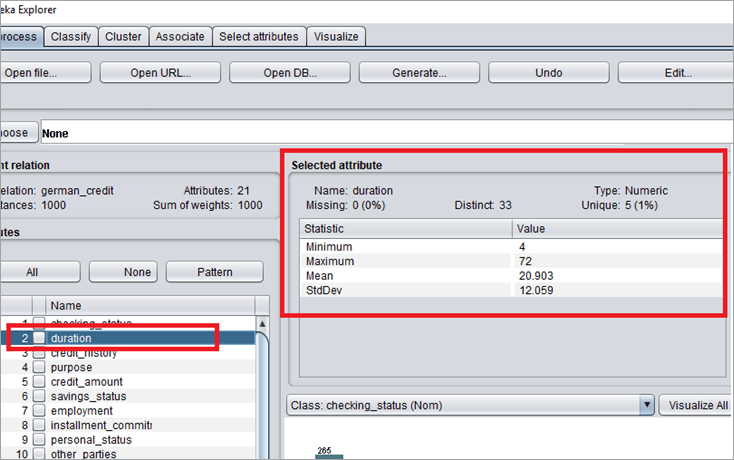
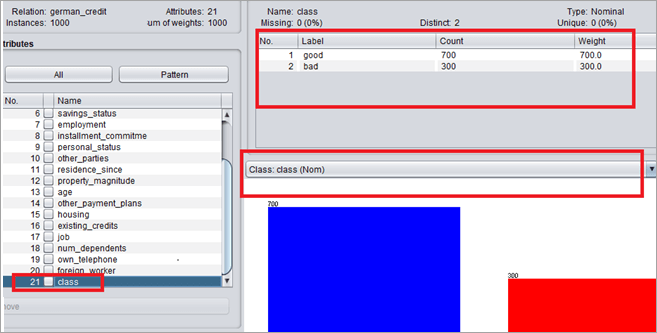
类是名义型的分类特征。
它有两个不同的价值:好的和坏的。好类标签有 700 个实例,坏类标签有 300 个实例。
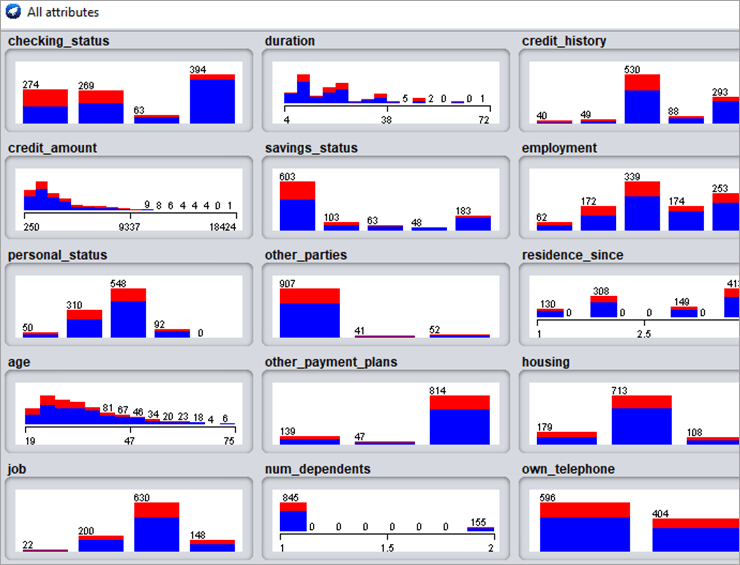
要可视化数据集的所有属性,请单击“Visualize All”。
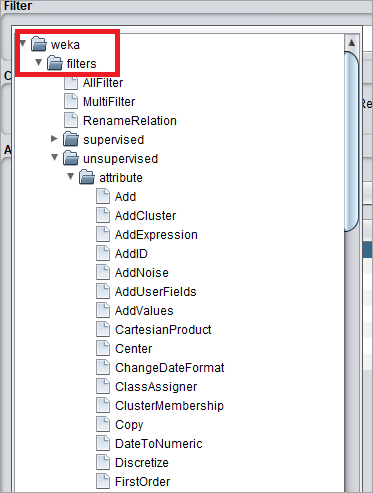
 #5)
#5)要仅找出数字属性,请单击“过滤器”按钮。从那里,单击
选择 -> WEKA > 过滤器 -> 无监督类型 -> 删除类型。
WEKA 过滤器具有许多功能来转换数据集的属性值,使其适用于算法。
例如,属性的数值转换。
从数据集中过滤名义和实值属性是使用 WEKA 过滤器的另一个例子。
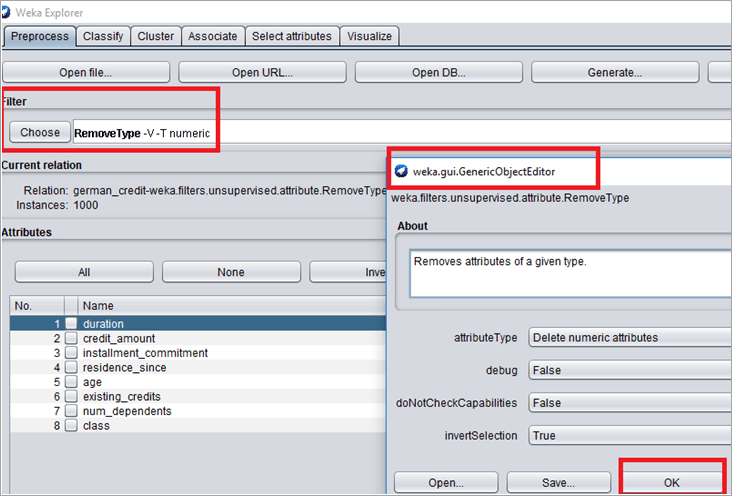
 #6)
#6)单击过滤器选项卡中的 RemoveType。将打开一个对象编辑器窗口。选择属性类型“删除数字属性”,然后单击“确定”。
 #7)
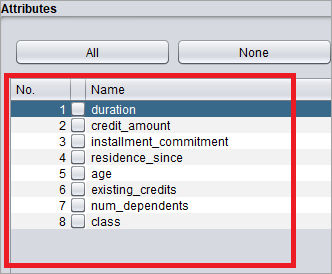
#7)应用过滤器。只会显示数字属性。
class 属性是名义类型。它对输出进行分类,因此无法删除。因此它是用数字属性看到的。
 输出:
输出:
识别数据集中的实值和名义值属性。类标签的可视化以直方图的形式显示。
WEKA机器学习:Weka 决策树分类算法
WEKA J48算法介绍 - 现在,我们将看到如何使用 J48 分类器在 weather.nominal.arff 数据集上实现决策树分类。
天气.nominal.arff
它是 WEKA 直接提供的示例数据集。该数据集预测天气是否适合打板球。该数据集有 5 个属性和 14 个实例。类标签“play”将输出分类为“是”或“否”。
什么是决策树
决策树是一种分类技术,由根节点、分支(边或链接)和叶节点三部分组成。根代表不同属性的测试条件,分支代表测试中可能存在的所有可能结果,叶节点包含其所属类的标签。根节点位于树的开头,也称为树的顶部。
J48 分级机
是一种生成决策树的算法,由C4.5(ID3的扩展)生成。它也被称为统计分类器。对于决策树分类,我们需要一个数据库。
步骤包括:
#1)打开 WEKA 资源管理器。
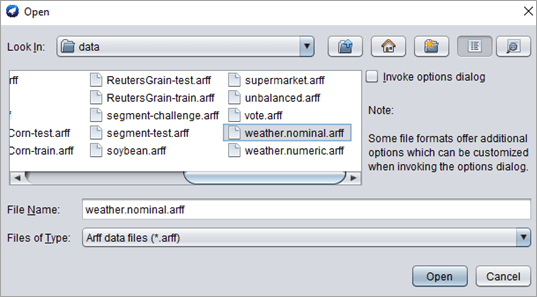
#2)从预处理选项卡选项下的“选择文件”中选择weather.nominal.arff 文件。
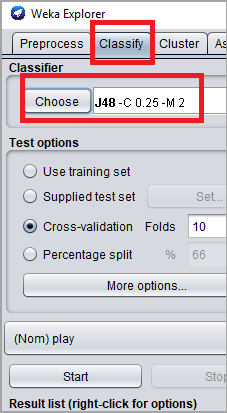
#3)转到“分类”选项卡对未分类的数据进行分类。单击“选择”按钮。从这里,选择“trees -> J48”。
让我们也快速浏览一下“选择”按钮中的其他选项:
- 贝叶斯:它是数值属性的密度估计。
- Meta:这是一个多响应线性回归。
- 功能:逻辑回归。
- 懒惰:它自动设置混合熵。
- Rule:它是一个规则学习器。
- 树:树对数据进行分类。
 #4)
#4)WEKA分类器介绍:点击开始按钮。分类器输出将显示在右侧面板上。
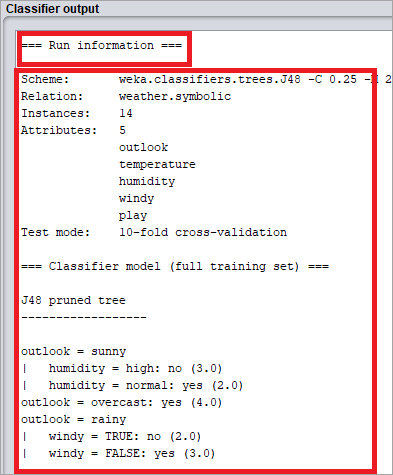
它将面板中的运行信息显示为:
- 方案:使用的分类算法。
- 实例:数据集中的数据行数。
- 属性:数据集有 5 个属性。
- 叶子的数量和树的大小描述了决策树。
- 构建模型所需的时间:输出时间。
- 使用属性和实例数量修剪的 J48 的完整分类。
 #5)
#5)要可视化树,请右键单击结果并选择可视化树。
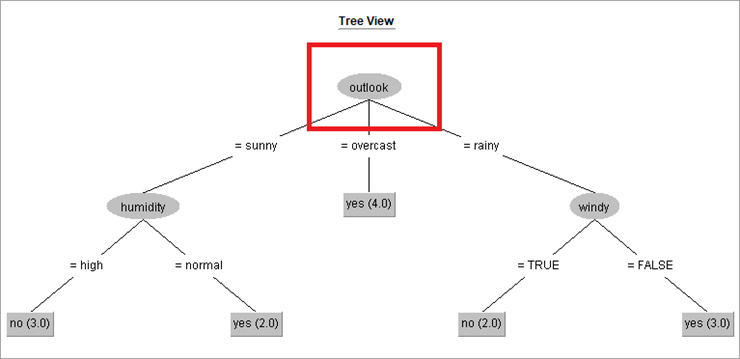 输出
输出:
输出采用决策树的形式。主要属性是“前景”。
如果前景晴朗,则树会进一步分析湿度。如果湿度高,则类标签播放=“是”。
如果前景是阴天,班级标签,播放是“是”。服从分类的实例数为 4。
如果展望为多雨,则进行进一步分类以分析属性“有风”。如果windy=true,则播放=“否”。遵守outlook=windy 和windy=true 分类的实例数为2。
WEKA机器学习总结
WEKA数据集详解 - WEKA 提供了广泛的样本数据集来应用机器学习算法。用户可以在这些样本数据集上执行分类、回归、属性选择、关联等机器学习任务,也可以学习使用它们的工具。
WEKA explorer 用于执行多种功能,从预处理开始。预处理将输入作为 .arff 文件,处理输入,并给出可供其他计算机程序使用的输出。在 WEKA 中,预处理的输出给出了数据集中存在的属性,这些属性可以进一步用于统计分析和与类标签的比较。
WEKA J48算法介绍 - WEKA 还为决策树提供了许多分类算法。J48 是输出决策树的流行分类算法之一。使用分类选项卡,用户可以可视化决策树。如果决策树过多,可以从预处理选项卡中通过删除不需要的属性并再次启动分类过程来应用树修剪。


