
本 WEKA 教程解释了什么是 Weka机器学习工具、它的功能以及如何下载、安装和使用 Weka 机器学习软件:
在上一教程中,我们了解了 ML 中的支持向量机以及相关概念,例如超平面、支持向量和 SVM 的应用。
机器学习是一个科学领域,其中机器充当人工智能系统。机器可以自行学习,无需任何明确的编码。这是一个访问数据、自行学习并预测结果的迭代过程。为了执行机器学习任务,需要许多工具和脚本。
WEKA 是一个机器学习平台,由许多工具组成,可促进许多机器学习活动,那么如何使用Weka工具呢?
Weka用法指南详细内容如下:
- 什么是WEKA
- 为什么使用 WEKA 机器学习工具
- 如何安装Weka?WEKA 下载安装
- WEKA的图形用户界面
- #1) 简单的 CLI
- #2) 资源管理器
- #3) 实验者
- #4) 知识流
- #5) 工作台
- WEKA Explorer 的特点
- #1) 数据集
- #2) ARFF 数据格式
- #3) XRFF 数据格式
- #4) 数据库连接
- #5) 分类器
- #6) 聚类
- #7) 协会
- #8) 属性部分度量
- #9) 可视化
- 结论
什么是WEKA

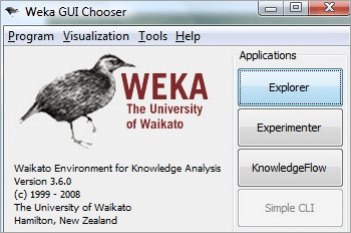
Weka机器学习工具是由新西兰怀卡托大学的科学家/研究人员设计和开发的开源工具。WEKA 代表怀卡托知识分析环境。它由国际科学界开发,并在免费的 GNU GPL 许可下分发。
WEKA 是完全用 Java 开发的。它使用 Java 数据库连接提供与 SQL 数据库的集成。它提供了许多机器学习算法来实现数据挖掘任务。这些算法可以直接使用 WEKA 工具使用,也可以与使用 Java 编程语言的其他应用程序一起使用。
它提供了大量的数据预处理、分类、聚类、回归分析、关联规则创建、特征提取和数据可视化的工具。它是支持机器学习新算法开发的强大工具。
为什么使用 WEKA 机器学习工具
使用 WEKA,用户可以轻松使用机器学习算法。ML 专家可以使用这些方法从大量数据中提取有用的信息。在这里,专家可以创建一个环境来开发新的机器学习方法并在真实数据上实施它们。
WEKA 被机器学习和应用科学研究人员用于学习目的。它是执行许多数据挖掘任务的有效工具。
Weka用法指南:WEKA 下载安装
#1)从这里下载软件。
如何安装Weka?检查计算机系统的配置并从此页面下载稳定版本的 WEKA(目前为 3.8)。
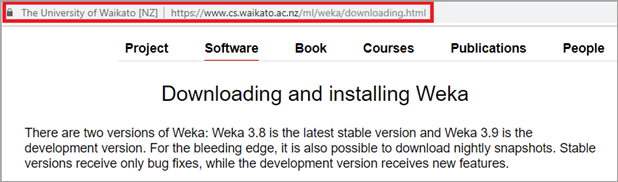
#2)下载成功后,打开文件所在位置,双击下载的文件。将出现升级向导。单击下一步。

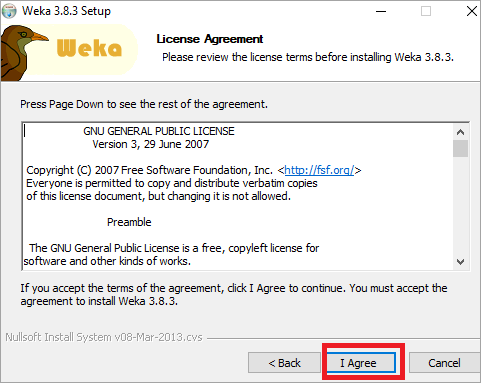
#3)许可协议条款将打开。仔细阅读并点击“我同意”。
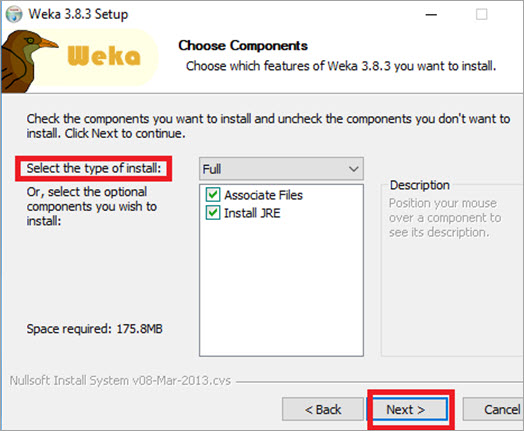
#4)根据你的要求,选择要安装的组件。建议安装完整的组件。单击下一步。
#5)选择目标文件夹,然后单击下一步。
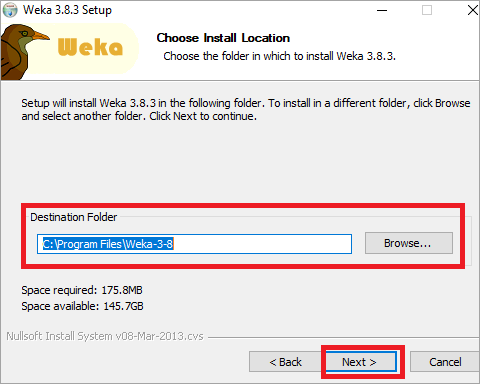
#6)然后,安装将开始。
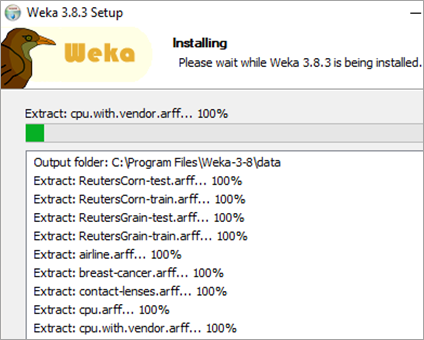
#7)如果系统中没有安装Java,它会先安装Java。
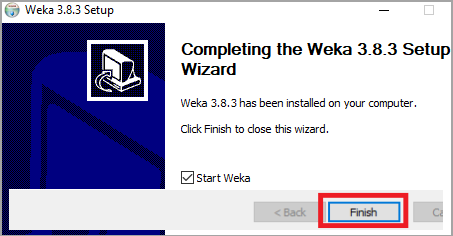
#8)安装完成后,会出现以下窗口。单击下一步。
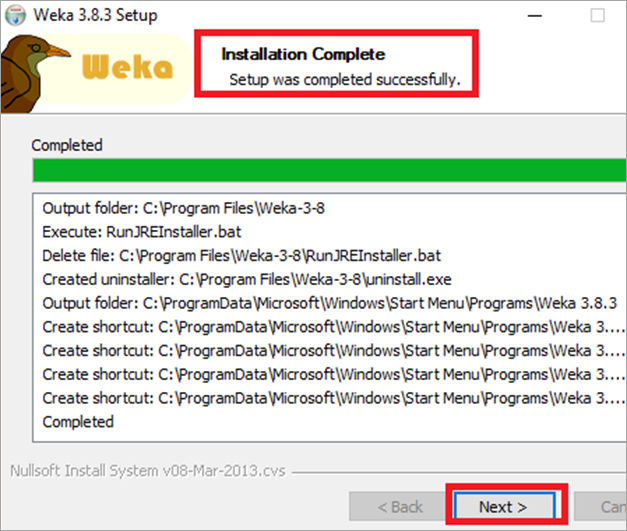
#9)选择开始 Weka 复选框。单击完成。
#10) WEKA 工具和资源管理器窗口打开。
#11)可以从这里下载 WEKA 手册。
WEKA的图形用户界面
如何安装Weka?WEKA 的 GUI 提供了五个选项: Explorer、Experimenter、Knowledge flow、Workbench 和 Simple CLI。让我们分别了解其中的每一个。
#1) 简单的 CLI
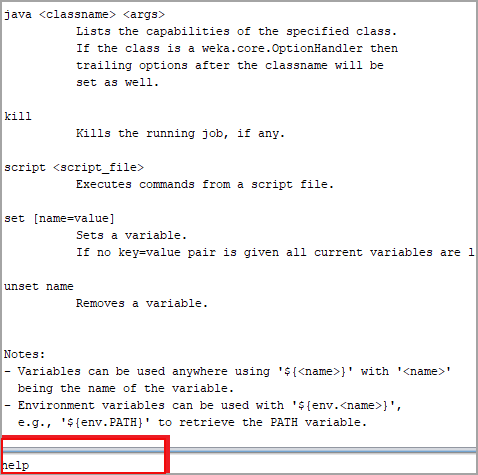
Weka机器学习工具:简单的 CLI 是带有命令行和输出的 Weka Shell。通过“帮助”,可以看到所有命令的概述。简单的 CLI 提供对所有类的访问,例如分类器、集群和过滤器等。
一些简单的 CLI 命令是:
- Break:停止当前线程
- 退出:退出 CLI
- Help[<command>] :输出指定命令的帮助信息
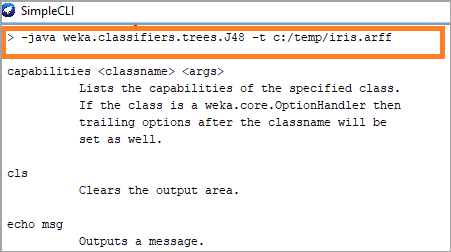
- -java weka.classifiers.trees.J48 -tc:/temp/iris.arff :要调用一个 WEKA 类,在它前面加上 Java 前缀。此命令将指示 WEKA 加载类并使用给定参数执行它。在此命令中,在 IRIS 数据集上调用 J48 分类器。
#2) 如何使用Weka工具?资源管理器
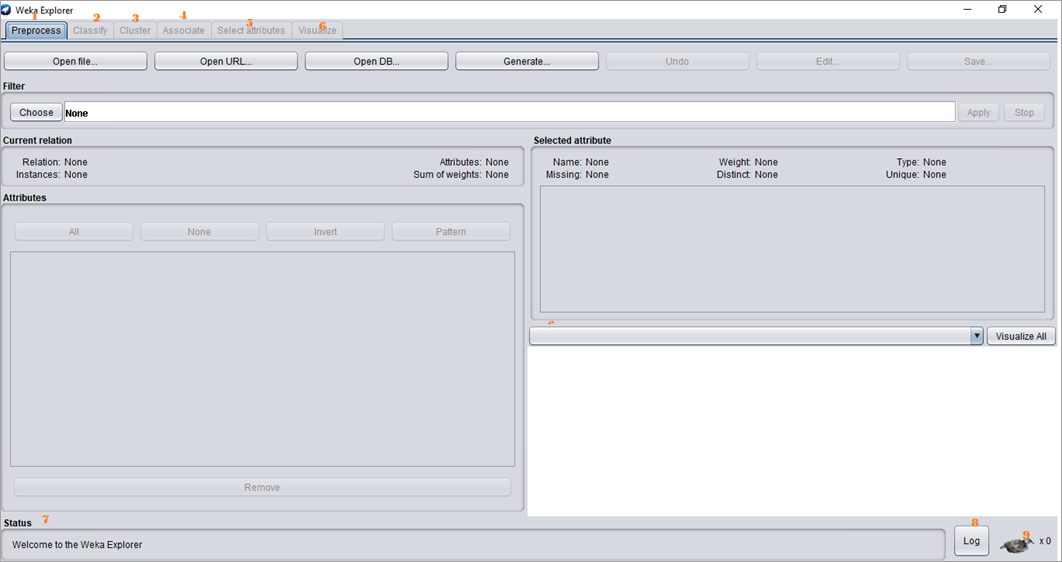
WEKA Explorer 窗口显示从预处理开始的不同选项卡。最初,预处理选项卡处于活动状态,因为首先对数据集进行预处理,然后再对其应用算法并探索数据集。
选项卡如下:
- 预处理:选择并修改加载的数据。
- 分类:对数据应用训练和测试算法,对数据进行分类和回归。
- 集群:从数据形成集群。
- Associate:挖掘数据的关联规则。
- 选择属性:应用属性选择措施。
- 可视化:可以看到数据的 2D 表示。
- 状态栏:窗口的最底部显示状态栏。此部分以消息的形式显示当前正在发生的事情,例如正在加载文件。右键这个,可以看到内存 信息,也可以运行运行 垃圾回收 器 释放空间。
- 日志按钮:它存储带有时间戳的 Weka 中所有操作的日志。单击“日志”按钮时,日志将显示在单独的窗口中。
- WEKA Bird 图标:右下角显示WEKA Bird 图标,代表同时运行的进程数(x.)。当进程运行时,鸟会四处走动。
#3) 实验者
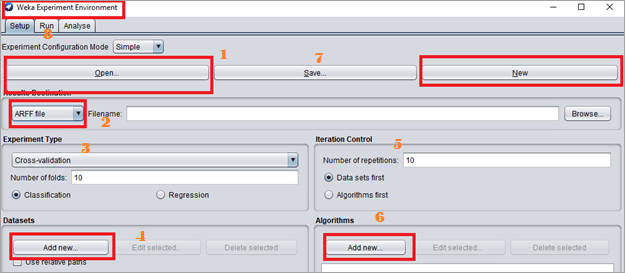
WEKA 实验者按钮允许用户在数据集的一个实验中创建、运行和修改不同的方案。实验者有两种类型的配置:简单和高级。这两种配置都允许用户在本地和远程计算机上运行实验。
- “打开”和“新建”按钮将打开用户可以执行的新实验窗口。
- 结果:从 ARFF、JDFC 和 CSV 文件设置结果目标文件。
- 实验类型:用户可以在交叉验证和训练/测试百分比拆分之间进行选择。用户可以根据使用的数据集和分类器在分类和回归之间进行选择。
- 数据集:用户可以从这里浏览和选择数据集。如果在不同的机器上工作,则单击相对路径复选框。支持的数据集格式为 ARFF、C4.5、CSV、libsvm、bsi 和 XRFF。
- 迭代:默认迭代次数设置为 10。数据集优先和算法优先有助于在数据集和算法之间切换,以便算法可以在所有数据集上运行。
- 算法: “新按钮”添加了新算法。用户可以选择一个分类器。
- 使用 Save 按钮保存实验。
- 使用运行按钮运行实验。
#4) 知识流
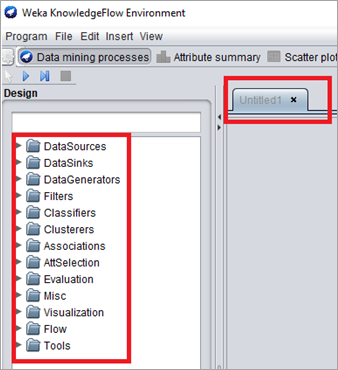
知识流显示了 WEKA 算法的图形表示。用户可以选择组件并创建工作流来分析数据集。数据可以分批或增量处理。可以设计并行工作流,每个工作流都将在单独的线程中运行。
可用的不同组件是数据源、数据保护程序、过滤器、分类器、集群、评估和可视化。
#5) 工作台
WEKA 有一个工作台模块,它在一个窗口中包含所有的 GUI。
Weka用法指南:WEKA Explorer 的特点
#1) 数据集
如何使用Weka工具?数据集由项目组成。它代表一个对象,例如:在营销数据库中,它将代表客户和产品。数据集由属性描述。数据集包含数据库中的数据元组。数据集具有可以是名义、数字或字符串的属性。在 Weka 中,数据集由weka.core.Instances类表示。
用 5 个例子表示数据集:
@data
晴天,假,85,85,没有
晴天,真,80,90,没有
阴天,假,83,86,是
下雨,假,70,96,是下雨,假,68,80
,是
什么是属性?
属性是表示数据对象特征的数据字段。例如,在客户数据库中,属性将是 customer_id、customer_email、customer_address 等。属性有不同的类型。
这些可能的类型是:
A) 名义属性: 与名称相关并具有预定义值(例如颜色、天气)的属性。这些属性称为分类属性。这些属性没有任何顺序,它们的值也称为枚举。
@attribute 展望{晴天,阴天,下雨}:名义属性的声明。
B) 二元属性:这些属性仅代表值 0 和 1。这些是只有 2 个类别的名义属性类型。这些属性也称为布尔值。
C) 序数属性:在它们之间保持某种顺序或排名的属性是序数属性。无法预测连续值,只能保持顺序。例如:尺寸、等级等。
D) 数字属性: 表示可测量数量的属性是数字属性。这些由实数或整数表示。例如:温度、湿度。
@attribute 湿度真实:数字属性的声明
E) 字符串属性:这些属性表示用双引号表示的字符列表。
#2) Weka机器学习工具:ARFF 数据格式
WEKA 使用 ARFF 文件进行数据分析。ARFF 代表属性关系文件格式。它有 3 个部分:关系、属性和数据。每个部分都以“@”开头。
ARFF 文件采用 Nominal、Numeric、String、Date 和 Relational 数据属性。WEKA 中存在一些著名的机器学习数据集作为 ARFF。
ARFF 的格式为:
@relation <关系名称>
@attribute <属性名称和数据类型>
@data
ARFF 文件的一个例子是:
@relation weather
@attribute outlook {sunny, overcast, rainy}:
@attribute temperature real
@attribute humidity real
@attribute windy {TRUE, FALSE}
@attribute play {yes, no} //class attribute: The class attribute represents the output.
@data
sunny, FALSE,85,85,no
sunny, TRUE,80,90,no
overcast, FALSE,83,86,yes
rainy, FALSE,70,96,yes
rainy, FALSE,68,80,yes#3) XRFF 数据格式
XRFF 代表 XML 属性关系文件格式。它表示可以存储评论、属性和实例权重的数据。它具有 .xrff 扩展名和 .xrff.gz(压缩格式)文件扩展名。XRFF 文件以 XML 格式表示数据。
#4) 数据库连接
使用 WEKA,可以很容易地使用 JDBC 驱动程序连接到数据库。连接数据库需要JDBC驱动,例如:
MS SQL Server (com.microsoft.jdbc.sqlserver.SQLServerDriver)
ORACLE(oracle.jdbc.driver.OracleDriver)
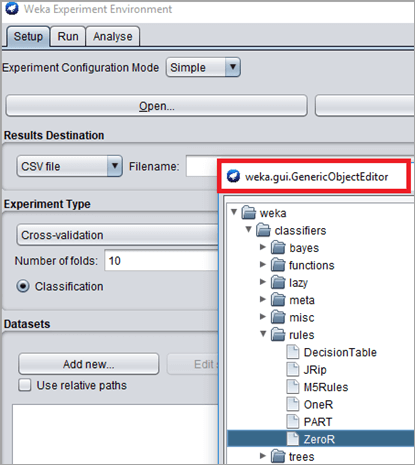
#5) 分类器
为了预测输出数据,WEKA 包含分类器。可供学习的分类算法有决策树、支持向量机、基于实例的分类器、逻辑回归和贝叶斯网络。根据使用试验和测试的要求,用户可以找到合适的算法来分析数据。分类器用于根据属性的特征对数据集进行分类。
#6) 聚类
WEKA 使用 Cluster 选项卡来预测数据集中的相似性。基于聚类,用户可以找出对分析有用的属性而忽略其他属性。WEKA 中可用的聚类算法有 k-means、EM、Cobweb、X-means 和 FarhtestFirst。
#7) 协会
WEKA 中唯一可用于找出关联规则的算法是 Apriori。
#8) 如何使用Weka工具?属性部分度量
WEKA 使用 2 种方法来为计算目的选择最佳属性:
- 使用搜索方法算法: Best-first、前向选择、随机、穷举、遗传算法和排序算法。
- 使用评估方法算法:基于相关性、包装器、信息增益、卡方。
#9) 可视化
WEKA 支持数据的 2D 表示、带旋转的 3D 可视化以及单个属性的 1D 表示。它具有用于标称属性和“隐藏”数据点的“抖动”选项。
WEKA 的其他主要特点是:
- 它是一个开源工具,具有“资源管理器”、“实验者”和“知识流”形式的图形用户界面。
- 它是独立于平台的。
- 它包含 49 个数据预处理工具。
- WEKA 中有 76 种分类和回归算法,8 种聚类算法
- 它有15种属性选择算法和10种特征选择算法。
- 它有 3 种查找关联规则的算法。
- 使用 WEKA,用户可以为机器学习开发自定义代码。
Weka用法指南总结
如何安装Weka?在本Weka机器学习工具教程中,我们介绍了开源 WEKA 机器学习软件,并逐步解释了下载和安装过程。我们还看到了 Weka 图形用户界面可用的五个选项,即 Explorer、Experimenter、Knowledge flow、Workbench 和 Simple CLI。
我们还通过示例了解了 WEKA 的功能。功能包括数据集、ARFF 数据格式、数据库连接等。

