
本遗传算法教程详细解释了什么是遗传算法及其在机器学习中的作用:
在上一教程中,我们了解了人工神经网络模型——多层感知器、反向传播、径向偏差和 Kohonen 自组织地图,包括它们的架构。
遗传算法工作原理:我们将专注于比神经网络更早出现的遗传算法,但现在 GA 已被 NN 接管。尽管如此,GA在现实生活中仍有应用,例如调度、玩游戏、机器人、硬件设计、旅行商问题等优化问题。
如何理解遗传算法?机器学习中的遗传算法是基于自然选择和遗传学的进化思想的算法。GA 是自适应启发式搜索算法,即算法遵循随时间变化的迭代模式。这是一种强化学习,其中需要反馈而不告诉正确的路径。反馈可以是正面的,也可以是负面的。
你会学到什么:
- 为什么要使用遗传算法
- 遗传算法的生物学背景
- 什么是遗传算法
- 染色体与 GA 的相关性
- GA 中的重要术语
- 一个简单的遗传算法
- 轮盘选择方法
- 其他选择方法
- 交叉
- 突变
- 何时停止遗传算法
- 遗传算法的优缺点
- 遗传算法的应用
- 结论
为什么要使用遗传算法
GA 是更健壮的算法,可用于各种优化问题。与其他 AI 算法不同,这些算法在存在噪声的情况下不会轻易偏离。GA 可用于搜索大空间或多模态空间。
遗传算法的生物学背景
遗传学源自希腊语“Genesis”,意思是成长。遗传决定了后代在进化过程中的遗传因素、相似性和差异。机器学习中的遗传算法也源自自然进化。
生物染色体中的一些术语
- 染色体:一个物种的所有遗传信息都存储在染色体中。
- 基因:染色体分为几个部分,称为基因。
- 等位基因:基因识别个体的特征。基因组合形成属性的可能性称为等位基因。一个基因可以有不同的等位基因。
- 基因库:群体库中所有等位基因的所有可能的基因组合称为基因库。
- 基因组:一个物种的基因组称为基因组。
- 基因座:每个基因在基因组中都有一个位置,称为基因座。
- 基因型:个体基因的完整组合称为基因型。
- 表型:一组解码形式的基因型称为表型。
什么是遗传算法?如何理解遗传算法?
遗传算法教程:遗传算法像在自然系统中一样刺激进化过程。查尔斯·达尔文提出了进化论,在自然进化中,生物按照“适者生存”的原则进化。GA 搜索旨在鼓励“适者生存”的理论。
GA 执行随机搜索以解决优化问题。GA 使用的技术使用以前的历史信息来引导他们的搜索在新的搜索空间中进行优化。
染色体与 GA 的相关性
人体有由基因组成的染色体。特定物种的所有基因的集合称为基因组。在生物中,基因组存储在不同的染色体中,而在 GA 中,所有基因都存储在同一条染色体中。
自然进化与遗传算法术语的比较
| 自然进化 | 遗传算法 |
|---|---|
| 染色体 | 细绳 |
| 基因 | 特征 |
| 等位基因 | 特征值 |
| 基因型 | 编码字符串 |
| 表型 | 解码结构 |
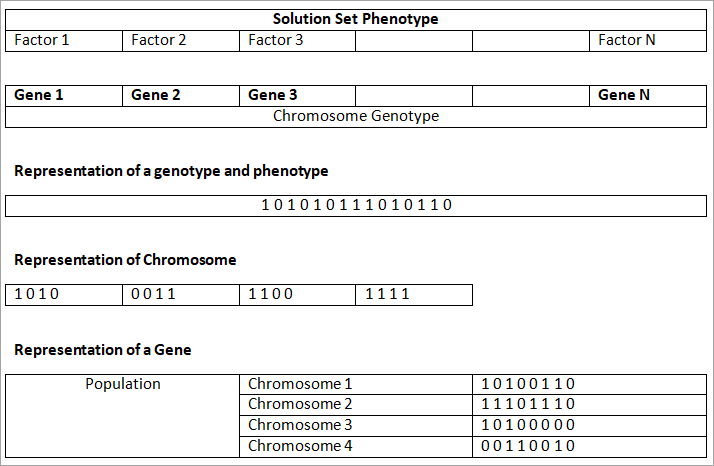
GA 中的重要术语
- 人口:是一群人。种群包括被测试个体的数量、搜索空间信息和表型参数。通常,种群是随机初始化的。
- 个体:个体是群体中的单一解。一个人有一组称为基因的参数。基因结合形成染色体。
- 基因:基因是遗传算法的基石。染色体由基因组成。基因可能决定问题的解决方案。它们由随机长度的位(0 或 1)字符串表示。
- 适应度:适应度说明问题表型的价值。适应度函数表明解与最优解的接近程度。适应度函数的确定方法有很多,例如与问题相关的所有参数的总和——欧氏距离等。没有任何规则来评估适应度函数。
遗传算法工作原理:一个简单的遗传算法
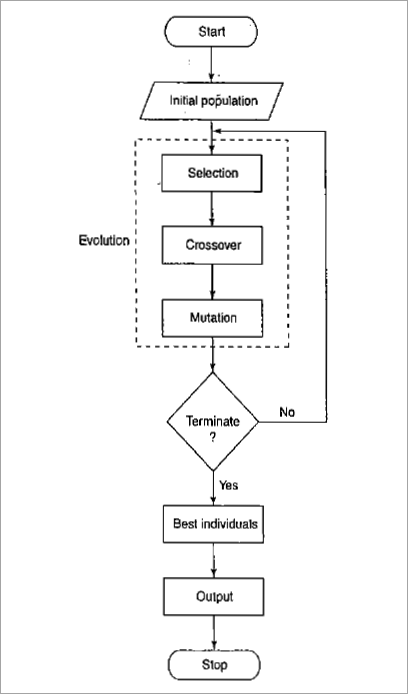
如何理解遗传算法?一个简单的机器学习中的遗传算法有一群个体染色体。这些染色体代表可能的解决方案。将复制算子应用于这些染色体组以执行突变和重组。因此,找到合适的复制算子很重要,因为 GA 的行为取决于它。
一个简单的遗传算法如下:
#1)从随机创建的人口开始。
#2)计算每个染色体的适应度函数。
#3)重复这些步骤直到创建 n 个后代。后代的创建如下所示。
- 从种群中选择一对染色体。
- 以概率 p c交叉配对以形成后代。
- 以概率 p m变异交叉。
#4)用新的种群替换原来的种群并转到步骤 2。
让我们看看在这个迭代过程中遵循的步骤。生成初始染色体群体。初始种群应包含足够的基因,以便可以生成任何解决方案。第一个种群池是随机生成的。
- 选择:根据适应度函数选择最佳基因组。选择具有最佳适应度函数的字符串。
- 繁殖:通过重组和变异产生新的后代。
- 评估:评估生成的新染色体的适合度。
- 替换:在这一步中,用新生成的种群替换旧种群。
轮盘选择方法
轮盘选择是广泛使用的选择方法。
选择过程很短,如下图所示:

在这种方法中,通过轮盘进行线性搜索。轮子上的槽根据个人的适应度值进行称重。目标值根据适应度总和在种群中的比例随机设定。
然后搜索总体,直到达到目标值。这种方法不能保证个体的适者,但有可能是最适者。
让我们看看轮盘赌选择涉及的步骤。
个体的期望值=个体适应度/总体适应度。轮槽根据个人的健康状况分配给他们。轮子旋转 N 次,其中 N 是种群中的个体总数。轮换结束后,将选定的个体放入父母池中。
- 设总体中多个个体的总期望值为 S。
- 重复步骤 3-5 n 次。
- 选择一个介于 0 和 S 之间的整数 s。
- 循环遍历种群中的个体,对期望值求和,直到总和大于 s。
- 选择其期望值使总和超过极限 s 的个体。
轮盘选择的缺点:
- 如果适应度差异很大,那么轮盘的周长将被最高适应度函数的染色体取最大,因此其他人被选中的机会很小。
- 它很吵。
- 进化取决于种群适应度的变化。
遗传算法教程:其他选择方法
遗传算法的“选择”步骤中还使用了许多其他选择方法。
我们将讨论另外两种广泛使用的方法:
#1) 排名选择:在这种方法中,每个染色体都从排名中获得一个适应度值。最差适应度为1,最佳适应度为N,属于慢收敛方法。在这种方法中,多样性被保留,导致搜索成功。
选择潜在的父母,然后举行比赛来决定哪些人将成为父母。
#2) 锦标赛选择:在这种方法中,对人群应用了选择性压力策略。最好的个体是具有最高适应度的个体。该个体是种群中怒族个体之间的锦标赛比赛的获胜者。
锦标赛人口与获胜者一起再次添加到池中以产生新的后代。获胜者和交配池中个体的适应度值的差异为最佳结果提供了选择压力。
交叉
这是一个带走2个人并从中生出一个孩子的过程。选择后的繁殖过程会克隆出好的刺。交叉算子应用于字符串以产生更好的后代。
交叉算子的实现如下:
- 从种群中随机选择两个个体来产生后代。
- 沿着字符串的长度随机选择一个交叉站点。
- 交换站点上的值。
执行的交叉可以是单点交叉、两点交叉、多点交叉等。单点交叉有一个交叉点,而两点交叉点有2个交换点。
我们可以在下面的例子中看到这一点:
单点交叉

两点交叉

交叉概率
P c,交叉概率是描述交叉执行频率的术语。0% 概率意味着新染色体将是旧染色体的精确副本,而 100% 概率意味着所有新染色体都是通过交叉产生的。
遗传算法工作原理:突变
如何理解遗传算法?变异是在交叉后完成的。而交叉只关注当前的解决方案,变异操作搜索整个搜索空间。这种方法是恢复丢失的遗传信息并分发遗传信息。
该算子有助于维持种群的遗传多样性。它有助于防止局部最小值并防止从任何人群中生成无用的解决方案。
变异以多种方式执行,例如以小概率反转每个基因的值或仅在提高解的质量时才执行变异。
一些突变的方法是:
- 翻转:从 0 变为 1 或从 1 变为 0。
- 互换:随机选择两个位置,值互换。
- 反转:选择随机位置并将其旁边的位反转。
让我们看一下每个示例:
翻转

换乘

倒车

突变概率
P m,突变概率是一个决定染色体突变频率的术语。如果突变概率为 100%,则意味着整个染色体都发生了变化。如果不进行突变,则交叉后直接产生新的后代。
通用机器学习中的遗传算法的一个例子突变概率: P m,突变概率是一个决定染色体突变频率的术语。如果突变概率为 100%,则意味着整个染色体都发生了变化。
如果不进行突变,则交叉后直接产生新的后代。染色体的初始种群为 A、B、C、D。种群大小为 4。
适应度函数被视为字符串中 1 的数量。
| 染色体 | Fitness |
|---|---|
| A:00000110 | 2 |
| B:11101110 | 6 |
| C:00100000 | 1 |
| D:00110100 | 3 |
适应度的总和为 12,这意味着,平均适应度函数将是 ~ 12/4 = 3
交叉概率= 0.7
突变概率= 0.001
#1)如果选择 B 和 C,则不进行交叉,因为 C 的适应度值低于平均适应度。
#2) B 突变 => B:11101110 -> B ' : 01101110 以保持种群多样性
#3)选择B和D,进行交叉。
B: 11101110 E:10110100 –> D:00110100 F:01101110

#4)如果 E 发生了变异,则
E: 10110100 -> E ' : 10110000
对应的染色体如下表所示。顺序是随机放置的。
| 染色体 | Fitness |
|---|---|
| A:01101110 | 5 |
| B:00100000 | 1 |
| C: 10110000 | 3 |
| D:01101110 | 5 |
尽管适应度值为 6 的最适个体丢失,但总体的平均适应度增加,为: 14/4 = 3.5
遗传算法教程:何时停止遗传算法
遗传算法工作原理 - 当满足下列某些条件时,遗传算法将停止:
#1) 最佳个体收敛:当最小适应度低于收敛值时,算法停止。它导致更快的收敛。
#2) 最差个体收敛:当群体中最不适合的个体达到低于收敛的最小适应度值时,算法停止。在这种方法中,最低适应度标准保持在种群中。这意味着不能保证最好的个体,但会出现最小的适应度值个体。
#3)适应度之和:在该方法中,如果适应度之和小于或等于收敛值,则停止搜索。它保证所有种群都在适应度范围内。
#4)中值适应度:在这种方法中,群体中至少有一半的个体会优于或等于收敛值。
一些收敛标准或停止条件可以是:
- 当特定数量的世代进化时。
- 当达到运行算法的指定时间时。
- 当种群的适应度值不会随着迭代而进一步改变时。
遗传算法的优缺点
遗传算法的优点是:
- 它有更广阔的解决空间。
- 更容易发现全局最优。
- 并行性:多个 GA 可以使用同一个 CPU 一起运行而不会相互干扰。它们独立地并行运行。
遗传算法的局限性:
- 适应度函数识别是一个限制。
- 算法的收敛可能太快或太慢。
- 对交叉、变异概率、种群大小等参数的选择存在限制。
遗传算法的应用
GA 可以有效地解决高维问题。当搜索空间非常大、没有可用的数学问题解决技术并且其他传统搜索算法不起作用时,GA 可以有效地使用。
一些使用 GA 的应用:
- 优化问题:优化问题的最佳示例之一是使用 GA 的旅行商问题。其他优化问题如作业调度、音质优化 GAs 也被广泛使用。
- 免疫系统模型: GA 用于模拟进化期间单个基因和多基因家族的免疫系统的各个方面。
- 机器学习: GA 已被用于解决与分类、预测、创建学习和分类规则相关的问题。
遗传算法教程总结
如何理解遗传算法?机器学习中的遗传算法基于自然进化的方法。这些算法不同于其他分类算法,因为它们使用编码参数(0 或 1),群体中有多个个体,并且它们使用概率方法进行收敛。
随着交叉和变异的过程,遗传算法在连续的世代收敛。GA 算法的执行并不总是保证成功的解决方案。遗传算法在优化 - 作业调度问题方面非常有效。
希望本教程能够丰富你对遗传算法概念的了解!!

