
监督学习与无监督学习有哪些不同?本教程通过简单的例子解释了机器学习的类型有哪些,即监督学习、无监督学习、强化学习和半监督学习。你还将了解监督学习与无监督学习之间的差异:
在上一教程中,我们了解了机器学习及其工作原理和应用。我们还看到了机器学习与人工智能的比较,在这篇文章中我们可以看到监督学习与无监督学习有什么区别。
机器学习是一个科学领域,它处理通过经验学习和预测输出的计算机程序。
ML 的主要特点是从经验中学习。当系统接受训练输入数据时,系统改变其参数并调整自身以提供所需的输出时,就会发生学习。输出是训练数据中定义的目标值。
从这个机器学习的类型详细指南中你会学到什么?
- 机器学习的类型
- #1) 监督学习
- 监督学习的例子
- 监督学习算法的类型
- #2) 无监督学习
- 无监督学习的例子
- 无监督算法的类型
- #3) 强化学习
- 强化学习的例子
- #1) 监督学习
- 监督和无监督学习的真实例子
- 监督学习与无监督学习之间的区别
- 半监督学习
- 结论
机器学习的类型有哪些?
机器学习程序分为 3 种类型,如下所示。
- 监督
- 无监督
- 强化学习
让我们详细了解每一个!!
#1) 监督学习
监督学习是在监督者在场的情况下进行的,就像小孩子在老师的帮助下进行的学习一样。当孩子在老师的监督下被训练识别水果、颜色、数字时,这种方法是监督学习。
在这种方法中,孩子的每一步都由老师检查,孩子从他必须产生的输出中学习。
监督学习如何运作?
在有监督的 ML 算法中,输出是已知的。存在输入与输出的映射。因此,为了创建模型,机器需要输入大量训练输入数据(已知输入和相应的输出)。
训练数据有助于实现创建的数据模型的准确度水平。构建的模型现在已准备好接受新的输入数据并预测结果。
什么是标记数据集?
对于给定输入具有已知输出的数据集称为标记数据集。例如,已知带有水果名称的水果图像。因此,当显示新的水果图像时,它会与训练集进行比较以预测答案。
监督学习是一种快速且准确率高的学习机制。监督学习问题包括回归和分类问题。那么监督学习与无监督学习有哪些不同?下面我们会详细看到这些差异信息。
一些监督学习算法是:
- 决策树,
- K-最近邻,
- 线性回归,
- 支持向量机和
- 神经网络。
监督学习的例子
- 第一步,将训练数据集馈送到机器学习算法。
- 使用训练数据集,机器通过改变参数来构建逻辑模型来自我调整。
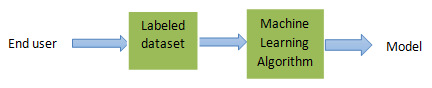
- 然后将构建的模型用于一组新数据以预测结果。

监督学习算法的类型
- 分类:在这些类型的问题中,我们将响应预测为特定类别,例如“是”或“否”。当仅存在 2 个类时,则称为二元分类。对于 2 个以上的类值,称为多类分类。预测的响应值是离散值。例如,它是太阳的形象还是月亮的形象?分类算法将数据分成几类。
- 回归:回归问题将响应预测为连续值,例如预测范围从 -infinity 到 infinity 的值。它可能需要许多值。例如,应用的线性回归算法根据位置、附近机场、房屋大小等许多参数来预测房屋成本。
#2) 机器学习的类型详细指南:无监督学习
无监督学习不需要监督者的帮助,就像鱼自己学会游泳一样。这是一个独立的学习过程。
在此模型中,由于没有与输入映射的输出,因此目标值未知/未标记。系统需要从输入的数据中自行学习并检测隐藏的模式。
什么是未标记数据集?
所有输入值都具有未知输出值的数据集称为未标记数据集。
无监督学习如何运作?
由于没有已知的输出值可用于在输入和输出之间构建逻辑模型,因此使用一些技术来挖掘数据规则、模式和具有相似类型的数据组。这些组帮助最终用户更好地理解数据并找到有意义的输出。
馈送的输入不像训练数据那样采用适当的结构形式(在监督学习中)。它可能包含异常值、噪声数据等。这些输入一起输入到系统中。在训练模型时,输入被组织成集群。
无监督学习算法包括聚类和关联算法,例如:
- 先验,
- K-means 聚类和其他关联规则挖掘算法。
当新数据输入模型时,它会将结果预测为输入所属的类标签。如果类标签不存在,则将生成一个新类。
在经历发现数据中模式的过程时,模型会自行调整其参数,因此也称为自组织。将通过找出输入之间的相似性来形成集群。
例如,在线购买产品时,如果将黄油放入购物车,则建议购买面包、奶酪等。无监督模型查看数据点并预测与产品相关的其他属性。
无监督学习的例子

无监督算法的类型
- 聚类算法:寻找相同形状、大小、颜色、价格等数据项之间的相似性并将它们分组以形成聚类的方法是聚类分析。
- 异常值检测:在这种方法中,数据集是对数据中任何类型的差异和异常的搜索。例如,用于欺诈检测的系统检测到信用卡上的高价值交易。
- 关联规则挖掘:在这种类型的挖掘中,它找出最常出现的项集或元素之间的关联。“经常一起购买的产品”等关联。
- 自编码器:输入被压缩成编码形式并重新创建以去除噪声数据。该技术用于改善图像和视频质量。
#3) 机器学习的类型有哪些?强化学习
在这种类型的学习中,算法通过反馈机制和过去的经验进行学习。总是希望算法中的每一步都被用来达到一个目标。
因此,无论何时采取下一步行动,它都会收到来自上一步的反馈,以及从经验中学习以预测下一步可能是什么。这个过程也称为达到目标的试错过程。
强化学习是一个长期的迭代过程。反馈的数量越多,系统就越准确。基本的强化学习也称为马尔可夫决策过程。
强化学习的例子
强化学习的例子是电子游戏,玩家完成游戏的特定级别并获得奖励积分。游戏通过奖励动作向玩家提供反馈,以提高他/她的表现。
强化学习用于训练机器人、自动驾驶汽车、库存自动管理等。
一些流行的强化学习算法包括:
- Q-学习,
- 深度对抗网络
- 时间差异
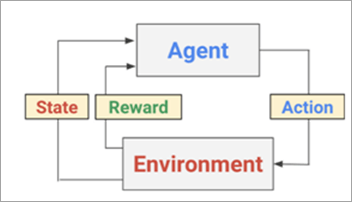
下图描述了强化学习的反馈机制。
- 输入由作为 AI 元素的代理观察。
- 该 AI 代理根据做出的决定对环境采取行动。
- 环境的响应以奖励的形式作为反馈发送给人工智能。
- 还保存对环境执行的状态和操作。
【图片来源】
监督学习与无监督学习有什么区别?监督和无监督学习的真实例子
对于监督学习:
#1)以一篮子蔬菜为例,有洋葱、胡萝卜、萝卜、西红柿等,我们可以将它们以组的形式排列。
#2)我们创建了一个训练数据表来理解监督学习。
训练数据表根据以下因素对蔬菜进行表征:
- 形状
- 颜色
- 尺寸
| 形状 | 颜色 | 尺寸 | 蔬菜 |
|---|---|---|---|
| 圆形的 | 棕色的 | 大 | 洋葱 |
| 圆形的 | 红色的 | 中等的 | 番茄 |
| 圆柱形 | 白色的 | 大 | 萝卜 |
| 圆柱形 | 红色的 | 中等的 | 萝卜 |
当这个训练数据表被输入机器时,它会使用蔬菜的形状、颜色、大小等建立一个逻辑模型,来预测结果(蔬菜)。
当一个新的输入输入到这个模型时,算法将分析参数并输出水果的名称。
对于无监督学习:
在无监督学习中,它根据属性创建组或集群。在上面的样本数据集中,vegetable的参数是:
#1) 形状
蔬菜根据形状分组。
- 圆形:洋葱和番茄。
- 圆柱形:萝卜和胡萝卜。
取另一个参数,例如大小。
#2) 尺寸
蔬菜根据大小和形状分组:
- 中号圆形:番茄
- 大尺寸和圆形:洋葱
在无监督学习中,我们没有任何训练数据集和结果变量,而在监督学习中,训练数据是已知的,用于训练算法。
监督学习与无监督学习之间的区别
| 监督 | 无监督 |
|---|---|
| 在监督学习算法中,给定输入的输出是已知的。 | 在无监督学习算法中,给定输入的输出是未知的。 |
| 算法从标记的数据集中学习。这些数据有助于评估训练数据的准确性。 | 该算法提供了未标记的数据,它试图在数据项之间找到模式和关联。 |
| 它是一种预测建模技术,可以准确预测未来的结果。 | 它是一种描述性建模技术,可以解释元素与元素历史之间的真实关系。 |
| 它包括分类和回归算法。 | 它包括聚类和关联规则学习算法。 |
| 监督学习的一些算法是线性回归、朴素贝叶斯和神经网络。 | 一些用于无监督学习的算法是 k-means 聚类、Apriori 等。 |
| 这种类型的学习相对复杂,因为它需要标记数据。 | 它不太复杂,因为不需要理解和标记数据。 |
| 它比无监督学习更准确,因为输入数据和相应的输出是众所周知的,机器只需要给出预测。 | 由于输入数据未标记,因此准确性较低。因此,机器必须首先理解和标记数据,然后给出预测。 |
| 这是一个在线数据分析过程,不需要人工交互。 | 这是对数据的实时分析。 |
半监督学习
半监督学习方法采用标记和未标记的训练数据输入。当难以从未标记的数据中提取有用的特征(监督方法)并且数据专家发现难以标记输入数据(无监督方法)时,这种类型的学习很有用。
这些算法中只有少量的标记数据才能导致模型的准确性。
例如半监督学习的包括CT扫描和MRI的其中一个医学专家可以在扫描标签几点任何疾病,同时也很难标注所有的扫描。
机器学习的类型详细指南结论
机器学习的类型有哪些?机器学习任务大致分为监督式、无监督式、半监督式和强化学习任务。
监督学习与无监督学习有什么区别?监督学习是在标记数据的帮助下学习。ML 算法由一个训练数据集提供,其中对于每个输入数据的输出都是已知的,以预测未来的结果。
该模型高度准确且速度快,但需要很高的专业知识和时间来构建。此外,如果数据发生变化,这些模型需要重建。ML 任务(例如回归和分类)是在监督学习环境下执行的。
无监督学习是在没有监督者帮助的情况下进行的。输入 ML 算法的输入数据是未标记的,即对于每个输入,没有输出是已知的。该算法本身会找出输入数据中的趋势和模式,并在输入的不同属性之间建立关联。
监督学习与无监督学习有哪些不同?这种类型的学习对于发现数据模式、创建数据集群和实时分析非常有用。聚类、KNN 算法等任务属于无监督学习。
半监督学习任务通过使用标记和未标记数据预测结果来实现监督和无监督算法的优势。强化学习是一种反馈机制,机器从环境的不断反馈中学习以实现其目标。
在这种类型的学习中,人工智能代理对数据执行一些操作,环境给予奖励。强化学习被用于儿童、自动驾驶汽车等的多人游戏。
请继续关注我们即将发布的教程,以了解有关机器学习和人工神经网络的更多信息!

