
python如何识别图片中的文字?OpenCV(开源计算机视觉)是一个主要针对实时计算机视觉的编程函数库。python中的OpenCV有助于处理图像并应用各种功能,如调整图像大小、像素操作、对象检测等。在本文中,我们将学习python识别图片文字以及如何使用轮廓来检测图像中的文本并将其保存到文本文件中。
所需安装:
pip install opencv-python
pip install pytesseractOpenCV和OCR实现文本检测和提取:OpenCV包用于读取图像并执行某些图像处理技术。Python-tesseract 是 Google 的 Tesseract-OCR 引擎的包装器,用于识别图像中的文本。
从此链接下载 tesseract 可执行文件。
方法:
在必要的导入之后,使用opencv的imread函数读取示例图像。
对图像应用图像处理:
图像的色彩空间首先被改变并存储在一个变量中。对于颜色转换,我们使用函数 cv2.cvtColor(input_image, flag)。第二个参数标志确定转换的类型。我们可以选择cv2.COLOR_BGR2GRAY和cv2.COLOR_BGR2HSV。cv2.COLOR_BGR2GRAY 帮助我们将 RGB 图像转换为灰度图像,而 cv2.COLOR_BGR2HSV 用于将 RGB 图像转换为 HSV(色相、饱和度、值)颜色空间图像。在这里,我们使用cv2.COLOR_BGR2GRAY。使用 cv2.threshold 函数将阈值应用于转换后的图像。
有3种类型的阈值:
- 简单的阈值
- 自适应阈值
- Otsu 的二值化
有关阈值的更多信息,请参阅使用 OpenCV 的阈值技术。
cv2.threshold() 有 4 个参数,第一个参数是颜色空间改变的图像,然后是最小阈值、最大阈值和需要应用的阈值类型。
要获得矩形结构:
cv2.getStructuringElement() 用于定义椭圆、圆形、矩形等结构元素。这里,我们使用矩形结构元素(cv2.MORPH_RECT)。cv2.getStructuringElement 采用额外大小的内核参数。更大的内核会将更大的文本块组合在一起。选择正确的内核后,使用 cv2.dilate 函数对图像应用膨胀。膨胀使文本组被更准确地检测,因为它膨胀(扩展)了一个文本块。
python识别图片文字 - 寻找轮廓:
cv2.findContours() 用于在膨胀图像中查找轮廓。cv.findContours() 中有三个参数:源图像、轮廓检索模式和轮廓逼近方法。
此函数返回轮廓和层次结构。Contours 是图像中所有轮廓的 Python 列表。每个轮廓都是对象中边界点的 (x, y) 坐标的 Numpy 数组。轮廓通常用于从黑色背景中查找白色对象。应用上述所有图像处理技术,使 Contours 可以检测图像文本块的边界边缘。文本文件以写入模式打开并刷新。打开此文本文件以保存 OCR 输出中的文本。
python如何识别图片中的文字?应用 OCR:
循环遍历每个轮廓并使用函数 cv2.boundingRect() 获取 x 和 y 坐标以及宽度和高度。然后使用函数 cv2.rectangle() 在获得的 x 和 y 坐标以及宽度和高度的帮助下在图像中绘制一个矩形。cv2.rectangle()中有5个参数,第一个参数指定输入图像,后面是x和y坐标(矩形的起始坐标),矩形的结束坐标即(x+w, y+ h),RGB 值中矩形的边界颜色和边界的大小。现在裁剪矩形区域,然后将其传递给 tesseract 以从图像中提取文本。然后我们以追加方式打开创建的文本文件,追加获取的文本并关闭文件。
用于代码的示例图像:

- Python 3 OpenCV和OCR实现文本检测和提取完整代码示例
# Import required packages
import cv2
import pytesseract
# Mention the installed location of Tesseract-OCR in your system
pytesseract.pytesseract.tesseract_cmd = 'System_path_to_tesseract.exe'
# Read image from which text needs to be extracted
img = cv2.imread("sample.jpg")
# Preprocessing the image starts
# Convert the image to gray scale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Performing OTSU threshold
ret, thresh1 = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU | cv2.THRESH_BINARY_INV)
# Specify structure shape and kernel size.
# Kernel size increases or decreases the area
# of the rectangle to be detected.
# A smaller value like (10, 10) will detect
# each word instead of a sentence.
rect_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (18, 18))
# Applying dilation on the threshold image
dilation = cv2.dilate(thresh1, rect_kernel, iterations = 1)
# Finding contours
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_NONE)
# Creating a copy of image
im2 = img.copy()
# A text file is created and flushed
file = open("recognized.txt", "w+")
file.write("")
file.close()
# Looping through the identified contours
# Then rectangular part is cropped and passed on
# to pytesseract for extracting text from it
# Extracted text is then written into the text file
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# Drawing a rectangle on copied image
rect = cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Cropping the text block for giving input to OCR
cropped = im2[y:y + h, x:x + w]
# Open the file in append mode
file = open("recognized.txt", "a")
# Apply OCR on the cropped image
text = pytesseract.image_to_string(cropped)
# Appending the text into file
file.write(text)
file.write("\n")
# Close the file
file.closepython识别图片文字输出结果:
最终文本文件:
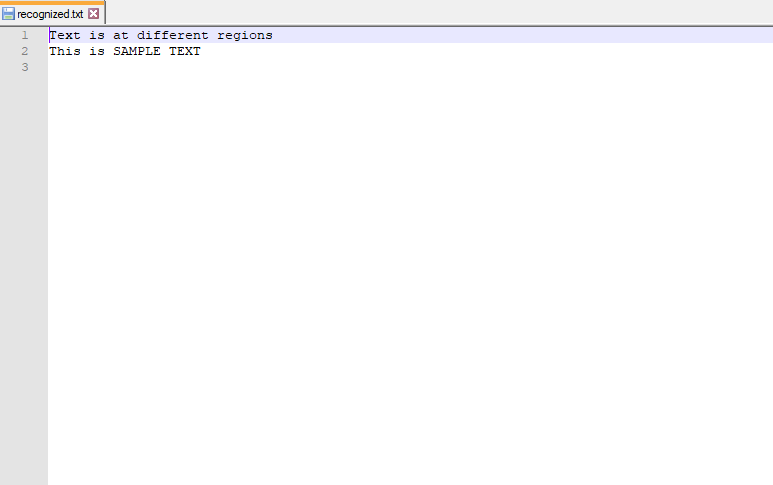
检测到的文本块:


