
TensorFlow-Lite植物物种识别介绍
深度学习模型非常庞大,并且需要大量计算才能进行推理。我们是否可以训练需要更少计算能力、更小并且可以部署在手机上的深度学习模型?嗯,答案是肯定的。通过将使用 ArcGIS API for Python训练TensorFlow lite模型的功能集成,我们现在可以训练可部署在移动设备上且尺寸更小的 DL 模型。
我们可以在哪里使用它们?我们可以使用它们来训练多个 DL 模型来执行专门针对移动设备的分类任务。我们所做的一个这样的集成是在“Survey123”应用程序中,这是一个简单而直观的以表格为中心的数据收集解决方案,供多个测量员在执行地面调查时使用,我们集成了一个 tf-lite 模型,在单击它的同时对不同的植物物种进行分类应用程序中的图片,本文有完整的python识别植物示例。
python如何识别植物?本笔记本旨在展示这种能力来训练深度学习模型,该模型可在移动应用程序中使用 TensorFlow Lite 框架进行实时推理。例如,我们将训练之前讨论过的相同植物物种分类模型,但使用较小的数据集。
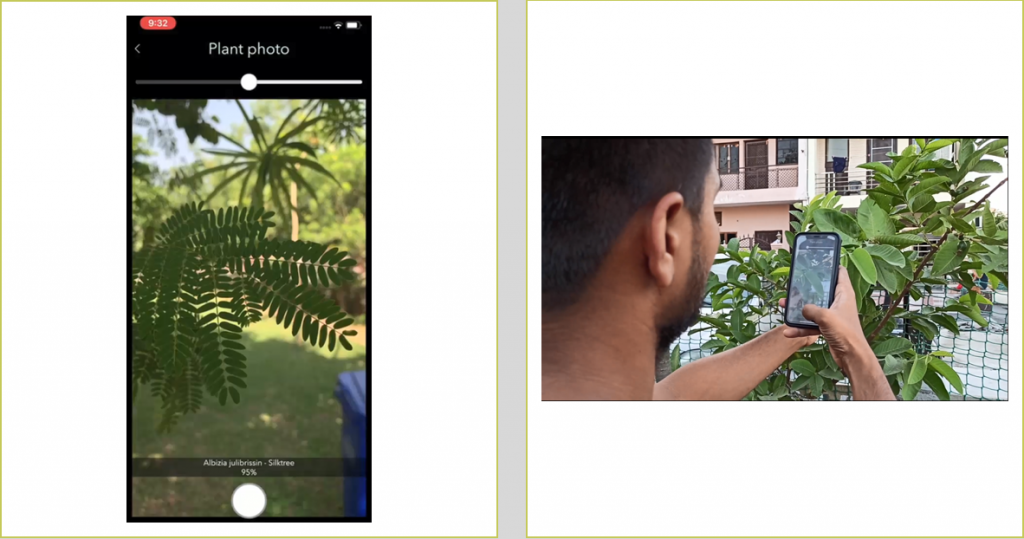
Survey123 应用程序中植物分类器的快照
获取数据进行分析
PlantCLEF数据分为三组:
- 基于在线协作生命百科全书 (EoL) [1]的“可信”训练集。
- “嘈杂”训练集(从 Google 和 Bing 图像搜索结果中获得,包括错误标记或不相关的图像[2]。
- 前几年(2015-2016 年)的图像仅描绘了该物种的一个子集[3]。
TensorFlow-Lite植物物种识别:对于这个笔记本,我们从基于在线协作生命百科全书[1]的“可信”训练集中提取了一个子集,其中包含 100 个植物物种的 39,354 张图像,并使用物种名称更改了它们的物种编号,例如物种编号42'改为'Acanthus mollis'。关于物种名称的信息存在于与每个图像文件一起存在的“xml”文件中。我们编写了一个脚本来执行货币名称和货币编号的映射。要了解我们是如何做到这一点的,请查看这里的脚本。
python识别植物的方法 - 使用以下命令运行下载的脚本。它需要传递三个参数:
- 下载 PlantCLEF 数据的路径
- 目标文件夹的路径
python changes_specie_name_with_number.py 数据/路径目标/路径
python识别植物示例:训练图像分类模型
python如何识别植物?我们将使用arcgis.learnArcGIS API for Python 中的模块训练我们的模型。arcgis.learn包含本研究所需的工具和深度学习能力。此处提供了安装和设置环境的详细文档。
必要的导入
首先,我们需要为 ArcGIS 设置环境变量以启用 TensorFlow 作为后端。要执行此操作,我们可以将ARCGIS_ENABLE_TF_BACKEND参数的值设置为 1,如下所示。
In [1]:
%env ARCGIS_ENABLE_TF_BACKEND=1%env ARCGIS_ENABLE_TF_BACKEND=1
In [2]:
import os
from pathlib import Path
from arcgis.gis import GIS
from arcgis.learn import prepare_data, FeatureClassifier下载数据集
In [2]:
gis = GIS('home')In [3]:
training_data = gis.content.get('81932a51f77b4d2d964218a7c5a4af17')
training_dataOut[3]:
train_a_tensorflow-lite_model_for_identifying_plant_species![]() Image Collection by api_data_owner
Image Collection by api_data_owner
Last Modified: August 31, 2020
0 comments, 0 views
In [4]:
filepath = training_data.download(file_name=training_data.name)In [5]:
import zipfile
with zipfile.ZipFile(filepath, 'r') as zip_ref:
zip_ref.extractall(Path(filepath).parent)In [6]:
data_path = Path(os.path.join(os.path.splitext(filepath)[0]))过滤掉非 RGB 图像
In [7]:
from glob import glob
from PIL import ImageIn [8]:
for image_filepath in glob(os.path.join(data_path, 'images', '**','*.jpg')):
if Image.open(image_filepath).mode != 'RGB':
os.remove(image_filepath)准备数据
我们现在将使用该prepare_data()函数对训练数据应用各种类型的转换和增强。这些增强使我们能够用有限的数据训练更好的模型,并防止模型过度拟合。
在这里,我们将 3 个参数传递给prepare_data()函数。
path:包含训练数据的文件夹路径。chip_size:与导出训练数据时的指定相同。batch_size:你的模型将在一个 epoch 内的每一步训练的图像数量,这直接取决于你的图形卡的内存和你正在使用的模型类型。对于此示例,我们在具有 11GB 内存的 GPU 上使用了 64 的批量大小。
In [9]:
data = prepare_data(
path=data_path,
dataset_type='Imagenet',
batch_size=64,
chip_size=300
)从你的训练数据中可视化一些样本
为了理解训练数据,我们将使用show_batch()arcgis.learn 中的方法。show_batch()从训练数据中随机挑选一些样本并将它们可视化。
rows:我们想要查看结果的行数。
In [10]:
data.show_batch(rows=2)
python识别植物示例:加载模型架构
arcgis.learn提供以FeatureClassifier模型的形式确定每个特征的类别的功能。要了解有关它的工作和使用情况的深入信息,请查看此链接。
TensorFlow-Lite植物物种识别 - 由于我们正在训练要部署在手机上的模型,因此我们必须使用“tensorflow”后端定义模型。为此,我们可以将参数设置backend为“tensorflow”。
In [12]:
model = FeatureClassifier(data, backbone='MobileNetV2', backend='tensorflow')找到最佳学习率
学习率是模型训练中最重要的超参数之一。在这里,我们探索了一系列学习率来指导我们选择最好的学习率。arcgis.learn利用 fast.ai 的学习率查找器为训练模型找到最佳学习率。我们可以使用该lr_find()方法找到可以足够快地训练鲁棒模型的最佳学习率。
In [13]:
lr = model.lr_find()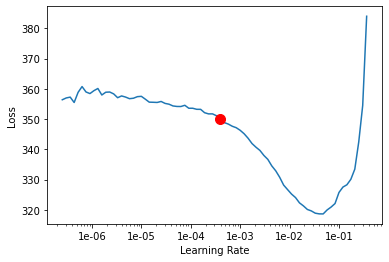
Out[13]: 0.00039810716
根据上面的学习率图,我们可以看到lr_find()我们的训练数据建议的学习率是 0.000691831。我们可以用它来训练我们的模型。在最新版本中,arcgis.learn我们甚至可以在不指定学习率的情况下训练模型。它在内部使用学习率查找器来找到最佳学习率并使用它。
python如何识别植物?拟合模型
python识别植物的方法:为了训练模型,我们使用fit()方法。首先,我们将使用 25 个 epoch 来训练我们的模型。Epoch 定义了模型暴露于整个训练集的次数。
In [14]:
model.fit(25, lr=lr)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 282.509796 | 284.545929 | 06:33 |
| 1 | 219.822098 | 216.609177 | 06:11 |
| 2 | 184.608017 | 179.594299 | 06:16 |
| 3 | 157.201462 | 152.107513 | 06:13 |
| 4 | 146.833130 | 143.230316 | 06:08 |
| 5 | 142.532150 | 140.502411 | 06:06 |
| 6 | 130.854355 | 128.107193 | 06:13 |
| 7 | 123.135384 | 120.282646 | 06:16 |
| 8 | 122.825447 | 121.192963 | 06:15 |
| 9 | 113.097366 | 110.876205 | 06:09 |
| 10 | 110.630867 | 107.839455 | 06:05 |
| 11 | 105.668732 | 102.160103 | 06:08 |
| 12 | 104.367531 | 101.760544 | 06:11 |
| 13 | 96.982460 | 92.826294 | 06:10 |
| 14 | 94.381241 | 90.038216 | 06:11 |
| 15 | 91.442261 | 87.211021 | 06:12 |
| 16 | 89.456108 | 84.471718 | 06:19 |
| 17 | 88.846085 | 85.127541 | 06:02 |
| 18 | 85.060516 | 80.282585 | 06:05 |
| 19 | 83.723434 | 80.030220 | 06:20 |
| 20 | 82.750427 | 78.108757 | 06:26 |
| 21 | 81.436134 | 77.348999 | 06:27 |
| 22 | 80.915581 | 77.150444 | 06:26 |
| 23 | 81.231522 | 77.088852 | 06:26 |
| 24 | 80.637024 | 76.966454 | 06:26 |
python识别植物示例:在验证集中可视化结果
下面的代码将选择一些随机样本,并排向我们展示真实情况和相应的模型预测。这使我们能够在笔记本本身中验证模型的结果。一旦满意,我们就可以保存模型并在我们的工作流程中进一步使用它。
In [15]:
model.show_results(rows=4, thresh=0.2)
在这里,来自训练数据的地面实况的子集与模型的预测一起被可视化。正如我们所看到的,我们的模型表现良好,预测与真实情况相当。
保存模型
TensorFlow-Lite植物物种识别:我们将以 tf-lite 格式保存我们训练的模型。
我们将使用该save()方法来保存训练好的模型。默认情况下,它将保存到我们的训练数据文件夹中的“模型”子文件夹中。
In [ ]:
model.save('Plant-identification-25-tflite', framework="tflite")python如何识别植物?部署模型
tf-lite 模型现在可以部署在移动设备上。Survey123 for ArcGIS 即将推出的功能集成了此类 tf-lite 模型。要了解有关在 Survey123 中部署此模型的更多信息,请加入早期采用者社区以访问 Survey123 私人测试版。
参考文献
[1] http://otmedia.lirmm.fr/LifeCLEF/PlantCLEF2017/TrainPackages/PlantCLEF2017Train1EOL.tar.gz
[2] http://otmedia.lirmm.fr/LifeCLEF/PlantCLEF2017/TrainPackages/PlantCLEF2017Train2Web.txt
[3] http://otmedia.lirmm.fr/LifeCLEF/PlantCLEF2015/Packages/TrainingPackage/PlantCLEF2015TrainingData.tar.gz

