

python如何识别声音?正如你可能从这篇文章的标题中看到的那样,我将使用 python 和声音来检测声音模式。更具体地说,敲门模式,就像你敲门时所做的那样。
Python进行声音模式识别:Knock Knock敲敲敲
在我们谈论敲击声音和模式之前,首先我们需要知道声音在计算机上是如何表示的:在非常基本的层面上,声音可以被认为是压力随时间变化的函数,因此我们可以在 2D 中表示声音图表,如下图。
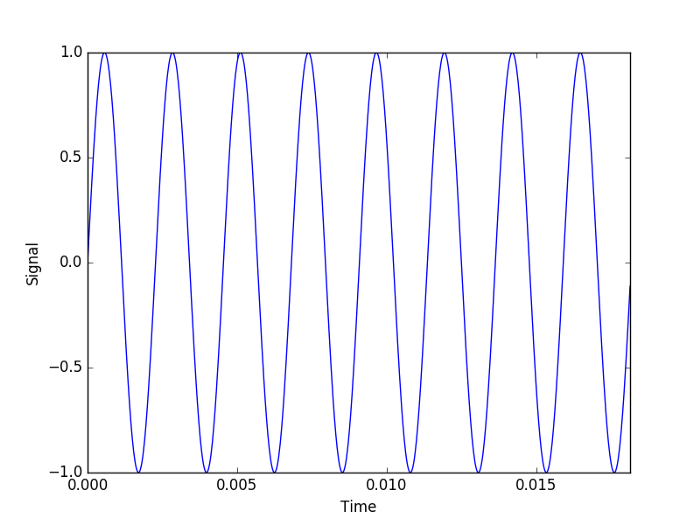
图像克raphs的正弦波440赫兹的频率和44100赫兹的采样率。我们还没有讨论采样,但我们将在下面讨论。
虽然看起来这个声音是一个连续函数,但它不是。为了在计算机上存储声音,我们做了一个小技巧:我们对它进行采样。采样过程非常简单,我们只需选择一个频率、采样率或 fs,并在每一秒内对气压进行 fs 采样,并创建一个大小为 fs x 时间(以秒为单位)的向量。所以我们的声音只是一个非常大的数字数组。
Knock Knock?
但这将如何帮助我们检测敲击模式?
好吧,定义敲击模式的是拍手和拍手之间的时间,我们只需要找出一种方法来根据我们的声音阵列确定敲击之间的时间。我们将在我们的第一次测试中使用这个knock.wav声音。
下面是敲击声音文件的图表。
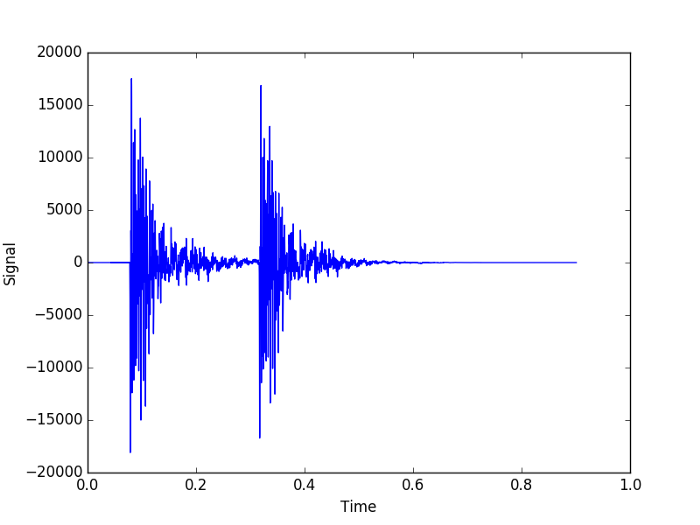
注意从哪里可以清楚地看到敲击声,在此基础上,我们的问题简化为:找到声音信号的峰值并计算它们之间的距离。
python如何识别声音?首先,我们需要将 .wav 文件作为 python 数组读取,假设knock.wav 与你的脚本在同一目录中,我们可以使用 scipy 执行此操作:
from scipy.io.wavfile import read
fs, data = read('knock.wav')
# we will use the size of the array
# to determine the duration of the sound
data_size = len(data)python识别声音的方法 - 要检测单个敲门声,我们需要做两件事:
- 信号中某个点的最小值成为峰值
- 将所有这些峰值聚集为一次敲击的时间距离,我们称之为合并大小
#The minimum value for the sound to be recognized as a knock
min_val = 5000
#The number of indexes on 0.15 seconds
focus_size = int(0.15 * fs)Python进行声音模式识别:我们需要使用采样率将秒转换为数组索引,至于合并大小,选择相当随意,应该考虑到声音被认为是有效敲击所需的响度。
现在算法的精华:
focuses = []
distances = []
idx = 0
while idx < len(data):
if data[idx] > min_val:
mean_idx = idx + focus_size // 2
focuses.append(float(mean_idx) / data_size)
if len(focuses) > 1:
last_focus = focuses[-2]
actual_focus = focuses[-1]
distances.append(actual_focus - last_focus)
idx += focus_size
else:
idx += 1
print focuses
print distances在这里我们做了两件事,首先我们寻找任何超过最小值的值被认为是一个峰值,每次我们找到这样的值时,我们将这个值和接下来 0.1 秒的任何值视为一次单独的爆震。
而这次爆震发生的时间就是焦点的中点。最后,我们来看看所有这些焦点打印之间的差异。
为了模块化,让我们把它包装在一个函数上,如下python识别声音示例:
from scipy.io.wavfile import read
def calc_distances(sound_file):
#The minimun value for the sound to be recognized as a knock
min_val = 5000
fs, data = read(sound_file)
data_size = len(data)
#The number of indexes on 0.15 seconds
focus_size = int(0.15 * fs)
focuses = []
distances = []
idx = 0
while idx < len(data):
if data[idx] > min_val:
mean_idx = idx + focus_size // 2
focuses.append(float(mean_idx) / data_size)
if len(focuses) > 1:
last_focus = focuses[-2]
actual_focus = focuses[-1]
distances.append(actual_focus - last_focus)
idx += focus_size
else:
idx += 1
return distances
print calc_distances('knock.wav')python如何识别声音?比较敲门声
假设我们有第二个敲击声,比如这里的knock2.wav:
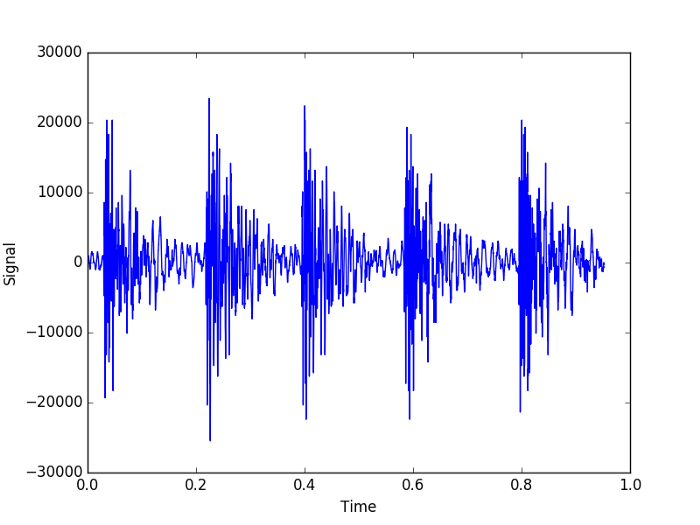
python识别声音的方法 - 如果我们计算它的焦点,我们有:
print calc_distances('knock2.wav')
# Outputs
[0.1978195192433994, 0.18560357283593854, 0.19873899908052017, 0.22172599500853807]Python进行声音模式识别:我们的代码显示有 4 个峰值,但是如果你查看图表,你可以清楚地看到 5 个峰值,这是因为拍手比我们的合并大小可以处理的更快。有办法解决这个问题,第一个是调整参数,另一个是将峰值检测算法更改为更完整(和复杂)的算法。
好的,我们快到了……要比较所需的模式 (knock.wav) 和测试模式 (knock2.wav),我们可以这样做,如下python识别声音示例:
def accept_test(pattern, test, min_error):
if len(pattern) > len(test):
return False
for i, dt in enumerate(pattern):
if not dt - test[i] < min_error:
return False
return True
pattern = calc_distances('knock.wav')
test = calc_distances('knock2.wav')
# the minimum difference between the patterns in seconds
min_error = 0.1
print accept_test(pattern, test, min_error)
# outputs
Truepython如何识别声音?我们可以看到测试被接受了,如果你同时听两个,你会注意到尽管第二个声音有更多的掌声,但前两个鼓掌在这两种声音上的距离相当相似。
正如你所看到的,它确实有效,虽然它没有检测到微秒的模式,但对于玩具秘密敲击电子锁或任何其他简单应用来说已经足够了。声音处理领域有很多可能性,python 肯定对它有用,我希望你和我一样喜欢这个。

