Python如何实现随机森林?在本指南中,我将向你展示 Python 中的随机森林示例。
一般来说,随机森林是一种有监督的机器学习形式,可用于分类和回归。
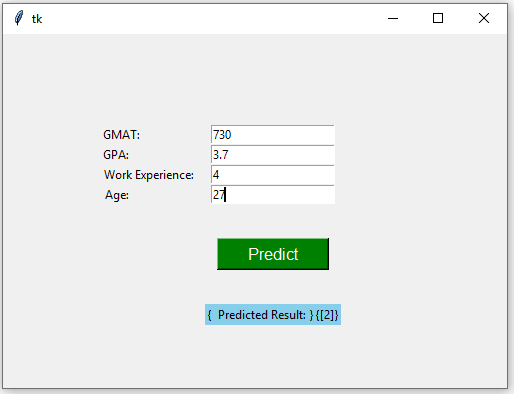
在本Python随机森林教程结束时,你将能够创建以下图形用户界面 (GUI) 来执行基于随机森林模型的预测:
Python随机森林示例
假设你的目标是预测候选人是否会被名牌大学录取。有3种可能的结果:
- 候选人被录取 - 由值2 表示
- 候选人在等候名单上 - 由值1 表示
- 候选人不被录取——用0表示
以下是将用于我们的示例的完整数据集:
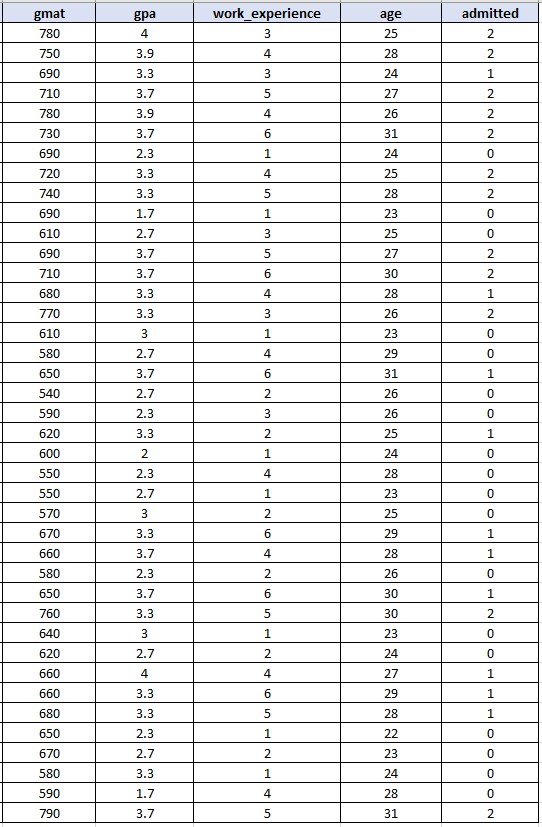
在我们的例子中:
- 在GMAT,GPA,work_experience和年龄是特征 变量
- 在admitted 列表示标签/目标
请注意,上述数据集包含 40 个观察值。实际上,你可能需要更大的样本量才能获得更准确的结果。
在 Python 中应用随机森林的步骤
步骤 1:安装相关的 Python 包
如果你还没有这样做,请安装以下 Python 包:
- pandas – 用于创建 DataFrame 以在 Python 中捕获数据集
- sklearn – 用于执行随机森林
- seaborn – 用于创建混淆矩阵
- matplotlib – 用于显示图表
你可以应用PIP 安装方法来安装这些软件包。
然后,你需要按如下方式导入 Python 包,如下Python随机森林代码示例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import seaborn as sn
import matplotlib.pyplot as plt第 2 步:创建数据帧
接下来,创建 DataFrame以捕获我们示例的数据集:
import pandas as pd
candidates = {'gmat': [780,750,690,710,780,730,690,720,740,690,610,690,710,680,770,610,580,650,540,590,620,600,550,550,570,670,660,580,650,760,640,620,660,660,680,650,670,580,590,790],
'gpa': [4,3.9,3.3,3.7,3.9,3.7,2.3,3.3,3.3,1.7,2.7,3.7,3.7,3.3,3.3,3,2.7,3.7,2.7,2.3,3.3,2,2.3,2.7,3,3.3,3.7,2.3,3.7,3.3,3,2.7,4,3.3,3.3,2.3,2.7,3.3,1.7,3.7],
'work_experience': [3,4,3,5,4,6,1,4,5,1,3,5,6,4,3,1,4,6,2,3,2,1,4,1,2,6,4,2,6,5,1,2,4,6,5,1,2,1,4,5],
'age': [25,28,24,27,26,31,24,25,28,23,25,27,30,28,26,23,29,31,26,26,25,24,28,23,25,29,28,26,30,30,23,24,27,29,28,22,23,24,28,31],
'admitted': [2,2,1,2,2,2,0,2,2,0,0,2,2,1,2,0,0,1,0,0,1,0,0,0,0,1,1,0,1,2,0,0,1,1,1,0,0,0,0,2]
}
df = pd.DataFrame(candidates,columns= ['gmat', 'gpa','work_experience','age','admitted'])
print (df)或者,你可以将数据从外部文件导入 Python。
第 3 步:在 Python 中应用随机森林
Python如何实现随机森林?现在,设置特征(表示为 X)和标签(表示为 y):
X = df[['gmat', 'gpa','work_experience','age']]
y = df['admitted']然后,应用 train_test_split。例如,你可以将测试大小设置为 0.25,因此模型 测试 将基于数据集的 25%,而模型 训练 将基于数据集的 75%:
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=0)应用随机森林如下Python随机森林示例:
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)接下来,添加此代码以获取混淆矩阵:
confusion_matrix = pd.crosstab(y_test, y_pred, rownames=['Actual'], colnames=['Predicted'])
sn.heatmap(confusion_matrix, annot=True)最后,打印精度并绘制混淆矩阵:
print('Accuracy: ',metrics.accuracy_score(y_test, y_pred))
plt.show()将上述所有组件放在一起:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import seaborn as sn
import matplotlib.pyplot as plt
candidates = {'gmat': [780,750,690,710,780,730,690,720,740,690,610,690,710,680,770,610,580,650,540,590,620,600,550,550,570,670,660,580,650,760,640,620,660,660,680,650,670,580,590,790],
'gpa': [4,3.9,3.3,3.7,3.9,3.7,2.3,3.3,3.3,1.7,2.7,3.7,3.7,3.3,3.3,3,2.7,3.7,2.7,2.3,3.3,2,2.3,2.7,3,3.3,3.7,2.3,3.7,3.3,3,2.7,4,3.3,3.3,2.3,2.7,3.3,1.7,3.7],
'work_experience': [3,4,3,5,4,6,1,4,5,1,3,5,6,4,3,1,4,6,2,3,2,1,4,1,2,6,4,2,6,5,1,2,4,6,5,1,2,1,4,5],
'age': [25,28,24,27,26,31,24,25,28,23,25,27,30,28,26,23,29,31,26,26,25,24,28,23,25,29,28,26,30,30,23,24,27,29,28,22,23,24,28,31],
'admitted': [2,2,1,2,2,2,0,2,2,0,0,2,2,1,2,0,0,1,0,0,1,0,0,0,0,1,1,0,1,2,0,0,1,1,1,0,0,0,0,2]
}
df = pd.DataFrame(candidates,columns= ['gmat', 'gpa','work_experience','age','admitted'])
#print (df)
X = df[['gmat', 'gpa','work_experience','age']]
y = df['admitted']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=0)
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
confusion_matrix = pd.crosstab(y_test, y_pred, rownames=['Actual'], colnames=['Predicted'])
sn.heatmap(confusion_matrix, annot=True)
print('Accuracy: ',metrics.accuracy_score(y_test, y_pred))
plt.show()在 Python 中运行代码,你将获得0.8的准确度,然后是混淆矩阵:
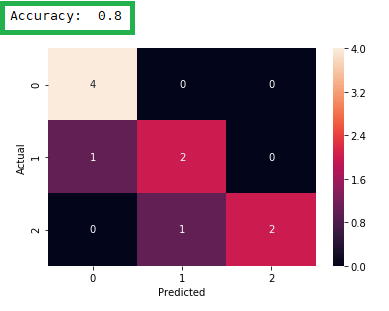
你还可以从混淆矩阵中得出准确度:
准确度 =(主对角线上值的总和)/(矩阵上所有值的总和)
对于我们的示例:
准确度 = (4+2+2)/(4+2+2+1+1) = 0.8
Python随机森林教程:现在让我们通过在 python 代码中打印以下两个组件来深入研究结果:
- print(X_test)
- print(y_pred)
这是使用的Python随机森林代码示例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
candidates = {'gmat': [780,750,690,710,780,730,690,720,740,690,610,690,710,680,770,610,580,650,540,590,620,600,550,550,570,670,660,580,650,760,640,620,660,660,680,650,670,580,590,790],
'gpa': [4,3.9,3.3,3.7,3.9,3.7,2.3,3.3,3.3,1.7,2.7,3.7,3.7,3.3,3.3,3,2.7,3.7,2.7,2.3,3.3,2,2.3,2.7,3,3.3,3.7,2.3,3.7,3.3,3,2.7,4,3.3,3.3,2.3,2.7,3.3,1.7,3.7],
'work_experience': [3,4,3,5,4,6,1,4,5,1,3,5,6,4,3,1,4,6,2,3,2,1,4,1,2,6,4,2,6,5,1,2,4,6,5,1,2,1,4,5],
'age': [25,28,24,27,26,31,24,25,28,23,25,27,30,28,26,23,29,31,26,26,25,24,28,23,25,29,28,26,30,30,23,24,27,29,28,22,23,24,28,31],
'admitted': [2,2,1,2,2,2,0,2,2,0,0,2,2,1,2,0,0,1,0,0,1,0,0,0,0,1,1,0,1,2,0,0,1,1,1,0,0,0,0,2]
}
df = pd.DataFrame(candidates,columns= ['gmat', 'gpa','work_experience','age','admitted'])
#print (df)
X = df[['gmat', 'gpa','work_experience','age']]
y = df['admitted']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=0)
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
print (X_test) #test dataset (without the actual outcome)
print (y_pred) #predicted values回想一下,我们的原始数据集有 40 个观察值。由于我们将测试大小设置为 0.25,因此混淆矩阵显示了总共 10 条记录的结果(=40*0.25)。这些是 10 个测试记录:
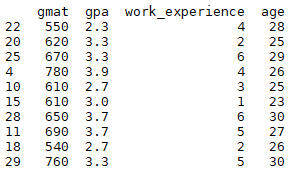
还对这 10 条记录进行了预测(其中 2 = 被录取,1 = 等待名单,0 = 未被录取):

在原始数据集中,你会看到对于测试数据,我们得到了 10 次中的 8 次正确结果:
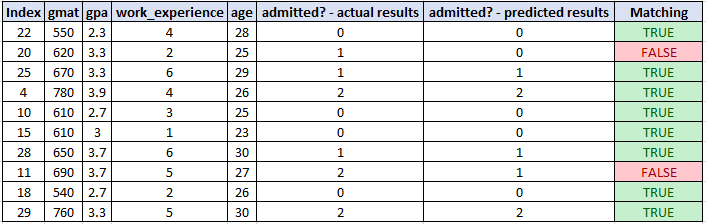
这与 80% 的准确度水平一致。
第 4 步:执行预测 - Python随机森林示例
Python如何实现随机森林?现在让我们根据以下信息进行预测,以确定新候选人是否会被录取:
- gmat = 730
- gpa = 3.7
- work_experience = 4
- age = 27
然后,你需要添加以下语法来进行预测:
prediction = clf.predict([[730,3.7,4,27]])
print ('Predicted Result: ', prediction)所以这就是完整代码的Python随机森林代码示例样子:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
candidates = {'gmat': [780,750,690,710,780,730,690,720,740,690,610,690,710,680,770,610,580,650,540,590,620,600,550,550,570,670,660,580,650,760,640,620,660,660,680,650,670,580,590,790],
'gpa': [4,3.9,3.3,3.7,3.9,3.7,2.3,3.3,3.3,1.7,2.7,3.7,3.7,3.3,3.3,3,2.7,3.7,2.7,2.3,3.3,2,2.3,2.7,3,3.3,3.7,2.3,3.7,3.3,3,2.7,4,3.3,3.3,2.3,2.7,3.3,1.7,3.7],
'work_experience': [3,4,3,5,4,6,1,4,5,1,3,5,6,4,3,1,4,6,2,3,2,1,4,1,2,6,4,2,6,5,1,2,4,6,5,1,2,1,4,5],
'age': [25,28,24,27,26,31,24,25,28,23,25,27,30,28,26,23,29,31,26,26,25,24,28,23,25,29,28,26,30,30,23,24,27,29,28,22,23,24,28,31],
'admitted': [2,2,1,2,2,2,0,2,2,0,0,2,2,1,2,0,0,1,0,0,1,0,0,0,0,1,1,0,1,2,0,0,1,1,1,0,0,0,0,2]
}
df = pd.DataFrame(candidates,columns= ['gmat', 'gpa','work_experience','age','admitted'])
#print (df)
X = df[['gmat', 'gpa','work_experience','age']]
y = df['admitted']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=0)
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
prediction = clf.predict([[730,3.7,4,27]])
print ('Predicted Result: ', prediction)运行代码后,你将获得2的值,这意味着该候选人有望被录取:

你可以通过创建一个简单的图形用户界面 (GUI)来更进一步,你可以在其中输入特征变量以获得预测。
以下是可用于创建 GUI 的完整Python随机森林代码示例(基于 tkinter 包):
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import tkinter as tk
candidates = {'gmat': [780,750,690,710,780,730,690,720,740,690,610,690,710,680,770,610,580,650,540,590,620,600,550,550,570,670,660,580,650,760,640,620,660,660,680,650,670,580,590,790],
'gpa': [4,3.9,3.3,3.7,3.9,3.7,2.3,3.3,3.3,1.7,2.7,3.7,3.7,3.3,3.3,3,2.7,3.7,2.7,2.3,3.3,2,2.3,2.7,3,3.3,3.7,2.3,3.7,3.3,3,2.7,4,3.3,3.3,2.3,2.7,3.3,1.7,3.7],
'work_experience': [3,4,3,5,4,6,1,4,5,1,3,5,6,4,3,1,4,6,2,3,2,1,4,1,2,6,4,2,6,5,1,2,4,6,5,1,2,1,4,5],
'age': [25,28,24,27,26,31,24,25,28,23,25,27,30,28,26,23,29,31,26,26,25,24,28,23,25,29,28,26,30,30,23,24,27,29,28,22,23,24,28,31],
'admitted': [2,2,1,2,2,2,0,2,2,0,0,2,2,1,2,0,0,1,0,0,1,0,0,0,0,1,1,0,1,2,0,0,1,1,1,0,0,0,0,2]
}
df = pd.DataFrame(candidates,columns= ['gmat', 'gpa','work_experience','age','admitted'])
#print (df)
X = df[['gmat', 'gpa','work_experience','age']]
y = df['admitted']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=0)
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
# tkinter GUI
root= tk.Tk()
canvas1 = tk.Canvas(root, width = 500, height = 350)
canvas1.pack()
# GMAT
label1 = tk.Label(root, text=' GMAT:')
canvas1.create_window(100, 100, window=label1)
entry1 = tk.Entry (root)
canvas1.create_window(270, 100, window=entry1)
# GPA
label2 = tk.Label(root, text='GPA: ')
canvas1.create_window(120, 120, window=label2)
entry2 = tk.Entry (root)
canvas1.create_window(270, 120, window=entry2)
# work_experience
label3 = tk.Label(root, text=' Work Experience: ')
canvas1.create_window(140, 140, window=label3)
entry3 = tk.Entry (root)
canvas1.create_window(270, 140, window=entry3)
# Age input
label4 = tk.Label(root, text='Age: ')
canvas1.create_window(160, 160, window=label4)
entry4 = tk.Entry (root)
canvas1.create_window(270, 160, window=entry4)
def values():
global gmat
gmat = float(entry1.get())
global gpa
gpa = float(entry2.get())
global work_experience
work_experience = float(entry3.get())
global age
age = float(entry4.get())
Prediction_result = (' Predicted Result: ', clf.predict([[gmat,gpa,work_experience,age]]))
label_Prediction = tk.Label(root, text= Prediction_result, bg='sky blue')
canvas1.create_window(270, 280, window=label_Prediction)
button1 = tk.Button (root, text=' Predict ',command=values, bg='green', fg='white', font=11)
canvas1.create_window(270, 220, window=button1)
root.mainloop()运行代码,你会得到这样的显示:
为新候选人键入以下值:
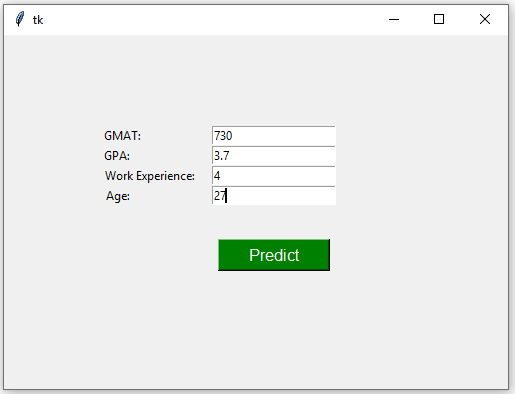
在输入框中输入完值后,单击“预测”按钮,你将得到 2 的预测(即,候选人有望被录取):
你可以尝试不同的值组合以查看预测结果。
Python随机森林教程:如何确定特征的重要性
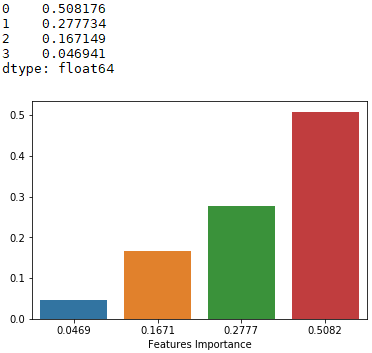
Python如何实现随机森林?在本指南的最后一节中,你将看到如何获得特征的重要性分数。一般来说,你可以考虑排除得分较低的特征。
以下是你需要添加以获得功能重要性的语法,如下Python随机森林代码示例:
featureImportances = pd.Series(clf.feature_importances_).sort_values(ascending=False)
print(featureImportances)
sn.barplot(x=round(featureImportances,4), y=featureImportances)
plt.xlabel('Features Importance')
plt.show()这是完整的Python随机森林示例代码(确保还导入了 matplotlib 包):
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import seaborn as sn
import matplotlib.pyplot as plt
candidates = {'gmat': [780,750,690,710,780,730,690,720,740,690,610,690,710,680,770,610,580,650,540,590,620,600,550,550,570,670,660,580,650,760,640,620,660,660,680,650,670,580,590,790],
'gpa': [4,3.9,3.3,3.7,3.9,3.7,2.3,3.3,3.3,1.7,2.7,3.7,3.7,3.3,3.3,3,2.7,3.7,2.7,2.3,3.3,2,2.3,2.7,3,3.3,3.7,2.3,3.7,3.3,3,2.7,4,3.3,3.3,2.3,2.7,3.3,1.7,3.7],
'work_experience': [3,4,3,5,4,6,1,4,5,1,3,5,6,4,3,1,4,6,2,3,2,1,4,1,2,6,4,2,6,5,1,2,4,6,5,1,2,1,4,5],
'age': [25,28,24,27,26,31,24,25,28,23,25,27,30,28,26,23,29,31,26,26,25,24,28,23,25,29,28,26,30,30,23,24,27,29,28,22,23,24,28,31],
'admitted': [2,2,1,2,2,2,0,2,2,0,0,2,2,1,2,0,0,1,0,0,1,0,0,0,0,1,1,0,1,2,0,0,1,1,1,0,0,0,0,2]
}
df = pd.DataFrame(candidates,columns= ['gmat', 'gpa','work_experience','age','admitted'])
X = df[['gmat', 'gpa','work_experience','age']]
y = df['admitted']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=0)
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
featureImportances = pd.Series(clf.feature_importances_).sort_values(ascending=False)
print(featureImportances)
sn.barplot(x=round(featureImportances,4), y=featureImportances)
plt.xlabel('Features Importance')
plt.show()正如你所观察到的,年龄的分数较低(即 0.046941),因此可能会被排除在模型之外: