
K-Means 聚类是一个属于无监督 学习的概念。该算法可用于在未标记数据中查找组。Python如何实现K-Means聚类?为了演示这个概念,我将回顾 Python 中 K-Means 聚类的一个简单示例。
这个Python K-Means聚类教程要涵盖的主题:
- 为二维数据集创建 DataFrame
- 找到 3 个簇的质心,然后找到 4 个簇的质心
- 添加图形用户界面 (GUI) 以显示结果
在本教程结束时,你将能够在 Python 中创建以下GUI:
Python K-Means聚类示例
首先,让我们回顾一个带有以下二维数据集的简单示例:
然后,你可以使用pandas DataFrame在 Python 中捕获此数据:
from pandas import DataFrame
Data = {'x': [25,34,22,27,33,33,31,22,35,34,67,54,57,43,50,57,59,52,65,47,49,48,35,33,44,45,38,43,51,46],
'y': [79,51,53,78,59,74,73,57,69,75,51,32,40,47,53,36,35,58,59,50,25,20,14,12,20,5,29,27,8,7]
}
df = DataFrame(Data,columns=['x','y'])
print (df)如果你在 Python 中运行代码,你将获得与我们的数据集匹配的输出:

接下来,你将看到如何使用sklearn找到 3 个集群的质心,然后是 4 个集群的质心。
Python 中的 K-Means 聚类 – 3 个集群
Python如何实现K-Means聚类?根据上述数据创建 DataFrame 后,你需要导入 2 个额外的 Python 模块:
- matplotlib – 用于在 Python 中创建图表
- sklearn——用于在 Python 中应用 K-Means 聚类
在下面的Python K-Means聚类代码示例中,你可以指定集群的数量。对于本示例,按如下方式分配 3 个集群:
KMeans(n_clusters= 3 ).fit(df)
from pandas import DataFrame
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
Data = {'x': [25,34,22,27,33,33,31,22,35,34,67,54,57,43,50,57,59,52,65,47,49,48,35,33,44,45,38,43,51,46],
'y': [79,51,53,78,59,74,73,57,69,75,51,32,40,47,53,36,35,58,59,50,25,20,14,12,20,5,29,27,8,7]
}
df = DataFrame(Data,columns=['x','y'])
kmeans = KMeans(n_clusters=3).fit(df)
centroids = kmeans.cluster_centers_
print(centroids)
plt.scatter(df['x'], df['y'], c= kmeans.labels_.astype(float), s=50, alpha=0.5)
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=50)
plt.show()在 Python 中运行代码,你将看到 3 个具有 3 个不同质心的集群:
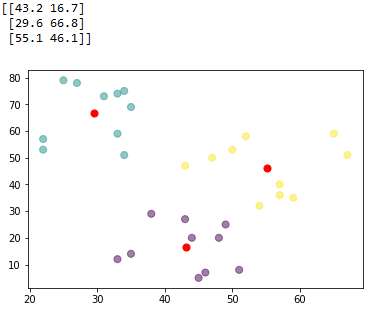
请注意,每个集群的中心(红色)表示属于该集群的所有观测值的平均值。
你可能还会看到,与其他集群的中心相比,属于给定集群的观测值更靠近该集群的中心。
Python 中的 K-Means 聚类 – 4 个集群
Python K-Means聚类示例:现在让我们看看如果你使用 4 个集群会发生什么。在这种情况下,你唯一需要做的就是将n_clusters从 3更改为 4:
KMeans(n_clusters= 4 ).fit(df)
因此,4 个集群的完整 Python 代码如下所示:
from pandas import DataFrame
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
Data = {'x': [25,34,22,27,33,33,31,22,35,34,67,54,57,43,50,57,59,52,65,47,49,48,35,33,44,45,38,43,51,46],
'y': [79,51,53,78,59,74,73,57,69,75,51,32,40,47,53,36,35,58,59,50,25,20,14,12,20,5,29,27,8,7]
}
df = DataFrame(Data,columns=['x','y'])
kmeans = KMeans(n_clusters=4).fit(df)
centroids = kmeans.cluster_centers_
print(centroids)
plt.scatter(df['x'], df['y'], c= kmeans.labels_.astype(float), s=50, alpha=0.5)
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=50)
plt.show()运行代码,你现在将看到 4 个具有 4 个不同质心的集群:
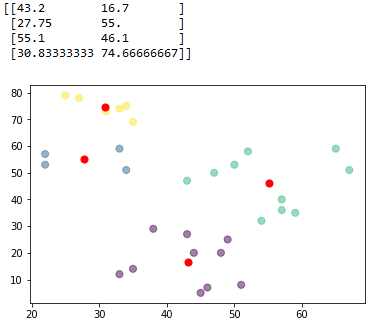
Python K-Means聚类教程:显示结果的 Tkinter GUI
你可以使用Python 中的tkinter 模块在简单的图形用户界面上显示集群。
这是你可以使用的Python K-Means聚类代码示例(对于 3 个集群):
from pandas import DataFrame
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import tkinter as tk
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
Data = {'x': [25,34,22,27,33,33,31,22,35,34,67,54,57,43,50,57,59,52,65,47,49,48,35,33,44,45,38,43,51,46],
'y': [79,51,53,78,59,74,73,57,69,75,51,32,40,47,53,36,35,58,59,50,25,20,14,12,20,5,29,27,8,7]
}
df = DataFrame(Data,columns=['x','y'])
kmeans = KMeans(n_clusters=3).fit(df)
centroids = kmeans.cluster_centers_
root= tk.Tk()
canvas1 = tk.Canvas(root, width = 100, height = 100)
canvas1.pack()
label1 = tk.Label(root, text=centroids, justify = 'center')
canvas1.create_window(70, 50, window=label1)
figure1 = plt.Figure(figsize=(5,4), dpi=100)
ax1 = figure1.add_subplot(111)
ax1.scatter(df['x'], df['y'], c= kmeans.labels_.astype(float), s=50, alpha=0.5)
ax1.scatter(centroids[:, 0], centroids[:, 1], c='red', s=50)
scatter1 = FigureCanvasTkAgg(figure1, root)
scatter1.get_tk_widget().pack(side=tk.LEFT, fill=tk.BOTH)
root.mainloop()这就是在 Python 中运行代码时你会得到的:
Python K-Means聚类示例:更高级的 Tkinter GUI
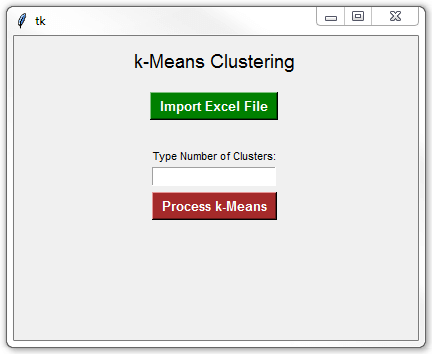
在本教程的最后一部分,我将分享创建更高级的 tkinter GUI 的代码,它允许你:
- 导入带有二维数据集的 Excel 文件
- 输入所需的集群数量
- 显示聚类和质心
这是完整的Python K-Means聚类代码示例:
import tkinter as tk
from tkinter import filedialog
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
root= tk.Tk()
canvas1 = tk.Canvas(root, width = 400, height = 300, relief = 'raised')
canvas1.pack()
label1 = tk.Label(root, text='k-Means Clustering')
label1.config(font=('helvetica', 14))
canvas1.create_window(200, 25, window=label1)
label2 = tk.Label(root, text='Type Number of Clusters:')
label2.config(font=('helvetica', 8))
canvas1.create_window(200, 120, window=label2)
entry1 = tk.Entry (root)
canvas1.create_window(200, 140, window=entry1)
def getExcel ():
global df
import_file_path = filedialog.askopenfilename()
read_file = pd.read_excel (import_file_path)
df = DataFrame(read_file,columns=['x','y'])
browseButtonExcel = tk.Button(text=" Import Excel File ", command=getExcel, bg='green', fg='white', font=('helvetica', 10, 'bold'))
canvas1.create_window(200, 70, window=browseButtonExcel)
def getKMeans ():
global df
global numberOfClusters
numberOfClusters = int(entry1.get())
kmeans = KMeans(n_clusters=numberOfClusters).fit(df)
centroids = kmeans.cluster_centers_
label3 = tk.Label(root, text= centroids)
canvas1.create_window(200, 250, window=label3)
figure1 = plt.Figure(figsize=(4,3), dpi=100)
ax1 = figure1.add_subplot(111)
ax1.scatter(df['x'], df['y'], c= kmeans.labels_.astype(float), s=50, alpha=0.5)
ax1.scatter(centroids[:, 0], centroids[:, 1], c='red', s=50)
scatter1 = FigureCanvasTkAgg(figure1, root)
scatter1.get_tk_widget().pack(side=tk.RIGHT, fill=tk.BOTH)
processButton = tk.Button(text=' Process k-Means ', command=getKMeans, bg='brown', fg='white', font=('helvetica', 10, 'bold'))
canvas1.create_window(200, 170, window=processButton)
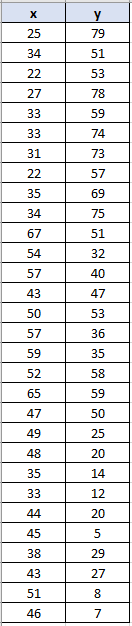
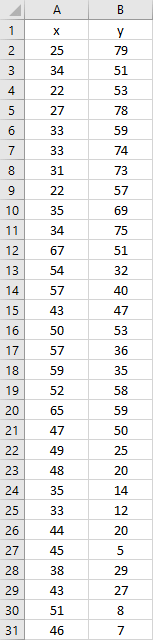
root.mainloop()Python如何实现K-Means聚类?在运行上述代码之前,你需要将二维数据集存储在 Excel 文件中。例如,你可以将以下日期集复制到 Excel 文件中:
| X | Y |
| 25 | 79 |
| 34 | 51 |
| 22 | 53 |
| 27 | 78 |
| 33 | 59 |
| 33 | 74 |
| 31 | 73 |
| 22 | 57 |
| 35 | 69 |
| 34 | 75 |
| 67 | 51 |
| 54 | 32 |
| 57 | 40 |
| 43 | 47 |
| 50 | 53 |
| 57 | 36 |
| 59 | 35 |
| 52 | 58 |
| 65 | 59 |
| 47 | 50 |
| 49 | 25 |
| 48 | 20 |
| 35 | 14 |
| 33 | 12 |
| 44 | 20 |
| 45 | 5 |
| 38 | 29 |
| 43 | 27 |
| 51 | 8 |
| 46 | 7 |
这是数据复制到 Excel 后的样子:
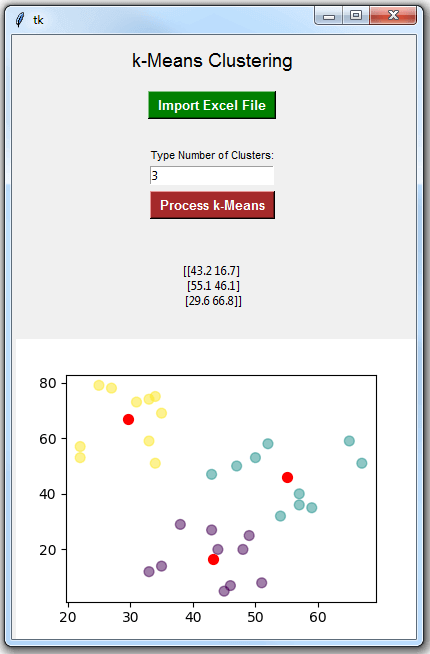
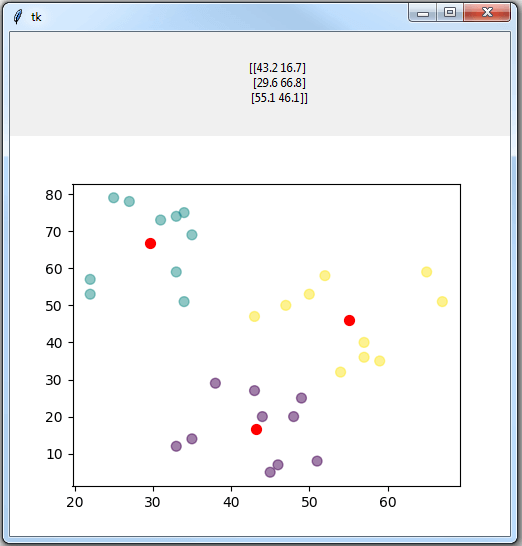
Python K-Means聚类示例:接下来,运行 Python 代码,你将看到以下 GUI:
按绿色按钮导入你的 Excel 文件(将打开一个对话框以帮助你找到并导入你的 Excel 文件)。
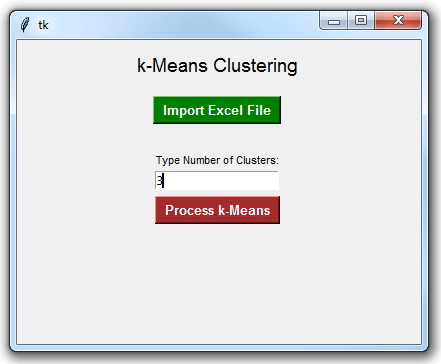
导入 Excel 文件后,在输入框中键入聚类数,然后单击红色按钮处理 k 均值。例如,我在输入框中输入了 3:
这是我得到的结果:
以上就是Python K-Means聚类教程的全部内容,你还可以可以通过访问sklearn 文档了解更多关于 K-Means聚类在 Python 中的应用。

