
在这篇文章中,我们将讨论使用 Python 的自然语言处理 (NLP)。本 NLP 教程将使用 Python NLTK 库。NLTK 是一个流行的 Python 库,用于 NLP。
那么什么是 NLP?以及学习 NLP 有什么好处?如何使用Python NLTK?下面我们通过简单的Python NLTK用法示例为你介绍自然语言处理的一般技术。
Python NLTK用法教程目录
- 什么是自然语言处理?
- NLP 的好处
- 自然语言处理实现
- 自然语言处理库
- 安装 NLTK
- 使用纯 Python 标记文本
- 计算词频
- 使用 NLTK 删除停用词
- 使用 NLTK 标记文本
- 标记非英语语言文本
- 从 WordNet 获取同义词
- 从 WordNet 获取反义词
- NLTK 词干提取
- 词干非英语单词
- 使用 WordNet 词形还原
- 词干提取和词形还原的区别
Python NLP教程:什么是自然语言处理?
简而言之,自然语言处理 (NLP) 是关于开发可以理解人类语言的应用程序和服务。
我们在这里谈论自然语言处理 (NLP) 的实际示例,例如语音识别、语音翻译、理解完整句子、理解匹配单词的同义词以及编写完整的语法正确的句子和段落。
这不是全部;你可以考虑有关这些想法及其好处的工业实施。
NLP 的好处
众所周知,博客、社交网站和网页每天产生数百万 GB 的数据。
许多公司正在收集所有这些数据以了解用户及其热情,并向公司提供报告以调整他们的计划。
这些数据可能表明巴西人民对产品 A 感到满意,可以是电影或任何东西,而美国人民对产品 B 感到满意。这可能是即时的(实时结果)。就像搜索引擎所做的那样,它们在正确的时间向正确的人提供适当的结果。
你知道吗,搜索引擎并不是自然语言处理 (NLP) 的唯一实现,还有很多很棒的实现。
自然语言处理实现
这些是自然语言处理 (NLP) 的一些成功实现:
- 搜索引擎如谷歌,雅虎,谷歌等搜索引擎的理解,你是一个高科技的家伙,所以它表明你的结果与你有关。
- 社交网站提要,如 Facebook 新闻提要。新闻提要算法使用自然语言处理了解你的兴趣,并比其他帖子更有可能向你显示相关的广告和帖子。
- 语音引擎,如 Apple Siri。
- 垃圾邮件过滤器,例如 Google 垃圾邮件过滤器。这不仅仅是关于通常的垃圾邮件过滤,现在垃圾邮件过滤器了解电子邮件内容中的内容并查看它是否是垃圾邮件。
自然语言处理库
有许多开源自然语言处理 (NLP) 库,其中有一些:
- 自然语言工具包 (NLTK)。
- Apache OpenNLP。
- 斯坦福 NLP 套件。
- 门 NLP 库。
自然语言工具包 (NLTK) 是最受欢迎的自然语言处理 (NLP) 库,它是用 Python 编写的,背后有一个庞大的社区。
NLTK 也很容易学习;它是你将使用的最简单的自然语言处理 (NLP) 库。
在本 NLP 教程中,我们将使用 Python NLTK 库。
在我开始安装 NLTK 之前,我假设你了解一些Python 基础知识以开始使用。
安装 NLTK
如果你使用的是 Windows 或 Linux 或 Mac,你可以使用 pip安装 NLTK :
$ pip install nltk在撰写本文时,你可以在 Python 2.7、3.4 和 3.5 上使用 NLTK。
或者,你可以从这个tar 的源代码安装它。
要检查 NLTK 是否已正确安装,你可以打开 python 终端并键入以下内容:
Import nltk如果一切顺利,则意味着你已成功安装 NLTK 库。
安装 NLTK 后,你应该通过运行以下代码来安装 NLTK 包:
import nltk
nltk.download()这将显示 NLTK 下载器以选择你需要安装的软件包。
你可以安装所有软件包,因为它们的尺寸很小,所以没问题。现在让我们开始表演。
使用纯 Python 标记文本
首先,我们将抓取一个网页内容,然后我们将分析文本以查看该页面的内容。
我们将使用urllib 模块来抓取网页:
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
print (html)从打印的输出中可以看出,结果中包含了很多需要清理的 HTML 标签。
我们可以使用 BeautifulSoup 来清理抓取的文本,如下所示:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
print (text)现在我们从抓取的网页中获得了一个干净的文本。
很棒,对吧?
最后,让我们通过像这样拆分文本来将该文本转换为标记:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = [t for t in text.split()]
print (tokens)Python NLTK用法教程:计算词频
文字现在好多了。让我们使用 Python NLTK 计算这些标记的频率分布。
NLTK 中有一个名为 FreqDist() 的函数可以完成这项工作:
from bs4 import BeautifulSoup
import urllib.request
import nltk
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = [t for t in text.split()]
freq = nltk.FreqDist(tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val))如果你搜索输出,你会发现最常见的标记是 PHP。
你可以使用 plot 函数为这些标记绘制图形,如下所示:
freq.plot(20, cumulative=False)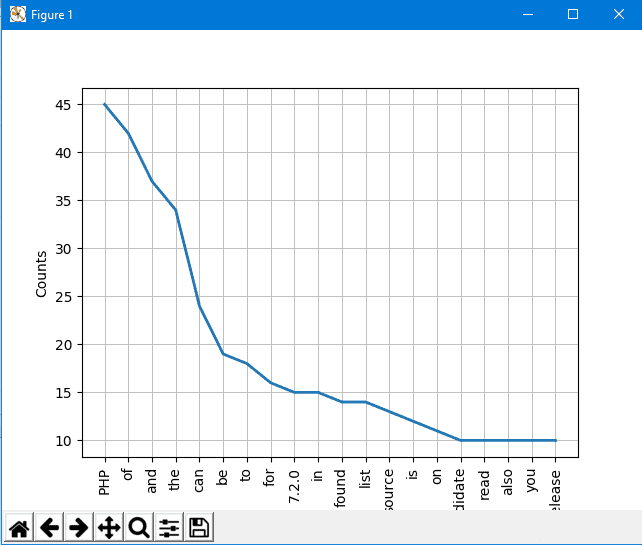
从图中,你可以确定这篇文章是在谈论 PHP。
伟大的!!
有一些词,如 The、Of、a、an 等。这些词是停用词。通常,你应该删除停用词以防止它们影响我们的结果。
Python NLP教程:使用 NLTK 删除停用词
NLTK 带有大多数语言的停用词列表。如何使用Python NLTK?要获取英语停用词,你可以使用以下代码:
from nltk.corpus import stopwords
stopwords.words('english')现在,让我们在绘制图形之前修改我们的代码并清理标记。
首先,我们将复制一份清单;然后我们将遍历标记并删除停用词:
clean_tokens = tokens[:]
sr = stopwords.words('english')
for token in tokens:
if token in stopwords.words('english'):
clean_tokens.remove(token)你可以查看Python 列表函数以了解如何处理列表。
所以最终的Python NLTK用法示例代码应该是这样的:
from bs4 import BeautifulSoup
import urllib.request
import nltk
from nltk.corpus import stopwords
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = [t for t in text.split()]
clean_tokens = tokens[:]
sr = stopwords.words('english')
for token in tokens:
if token in stopwords.words('english'):
clean_tokens.remove(token)
freq = nltk.FreqDist(clean_tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val))如果你现在查看图表,会比以前更好,因为计数中没有停用词。
freq.plot(20,cumulative=False)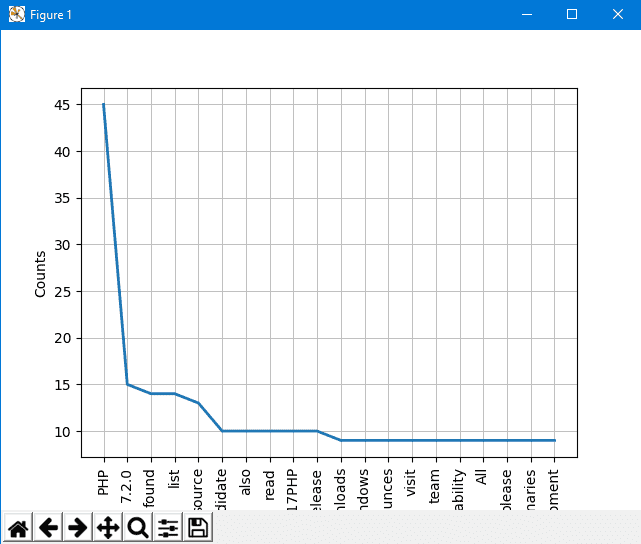
Python NLTK用法教程:使用 NLTK 标记文本
我们看到了如何使用 split 函数将文本拆分为标记。现在我们将看到如何使用 NLTK 标记文本。
对文本进行分词很重要,因为没有分词就无法处理文本。标记化过程意味着将较大的部分分成小部分。
你可以根据需要将段落标记为句子并将句子标记为单词。NLTK 带有句子分词器和单词分词器。
假设我们有如下示例文本:
Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude.为了将此文本标记为句子,我们将使用句子标记器:
from nltk.tokenize import sent_tokenize
mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(sent_tokenize(mytext))输出如下:
['Hello Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']你可能会说这是一项简单的工作,我不需要使用 NLTK 标记化,而且我可以使用正则表达式拆分句子,因为每个句子前面都有标点符号和空格。
好吧,看看下面的文字:
Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude.呃!先生这个词本身就是一个词。好的,让我们试试 NLTK:
from nltk.tokenize import sent_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(sent_tokenize(mytext))输出如下所示:
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']great!它就像一个魅力。
好的,让我们试试 word tokenizer 看看它是如何工作的。
from nltk.tokenize import word_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(word_tokenize(mytext))输出是:
['Hello', 'Mr.', 'Adam', ',', 'how', 'are', 'you', '?', 'I', 'hope', 'everything', 'is', 'going', 'well', '.', 'Today', 'is', 'a', 'good', 'day', ',', 'see', 'you', 'dude', '.']先生这个词果然是一字之差。
NLTK 使用 PunktSentenceTokenizer,它是 nltk.tokenize.punkt 模块的一部分。
这个分词器训练有素,可以使用多种语言。
标记非英语语言文本
要标记其他语言,你可以像这样指定语言:
from nltk.tokenize import sent_tokenize
mytext = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour."
print(sent_tokenize(mytext,"french"))结果将是这样的:
['Bonjour M. Adam, comment allez-vous?', "J'espère que tout va bien.", "Aujourd'hui est un bon jour."]我们做得很好。
从 WordNet 获取同义词
如果你还记得,我们使用 nltk.download() 安装了 NLTK 包。其中一个软件包是 WordNet。
WordNet 是一个为自然语言处理而构建的数据库。它包括同义词组和简要定义。
你可以像这样获得给定单词的这些定义和示例:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain")
print(syn[0].definition())
print(syn[0].examples())结果是:
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']WordNet 包含很多定义:
from nltk.corpus import wordnet
syn = wordnet.synsets("NLP")
print(syn[0].definition())
syn = wordnet.synsets("Python")
print(syn[0].definition())结果是:
the branch of information science that deals with natural language information
large Old World boas你可以使用 WordNet 获得这样的同义词:
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)输出是:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']COOL!!
从 WordNet 获取反义词
你可以用同样的方式得到反义词,你所要做的就是在将它们添加到数组之前检查引理是否是反义词。
from nltk.corpus import wordnet
antonyms = []
for syn in wordnet.synsets("small"):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(antonyms)输出是:
['large', 'big', 'big']这就是 NLTK 在自然语言处理中的强大之处。
如何使用Python NLTK?NLTK 词干提取
词干提取意味着从词中去除词缀并返回词根。例如:工作一词的词干 => 工作。
搜索引擎在索引页面时使用这种技术,因此许多人为同一个词编写不同的版本,并且所有版本都源于根词。
词干的算法有很多,但最常用的算法是波特词干算法。
NLTK 有一个名为 PorterStemmer 的类,它使用 Porter Stemming 算法,Python NLTK用法示例如下:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('working'))结果是:
work够清楚。
还有一些其他的词干算法,如Lancaster 词干算法。
该算法的输出显示了几个单词的稍微不同的结果。你可以同时尝试这两种方法以查看结果。
Python NLTK用法教程:词干非英语单词
SnowballStemmer 可以阻止除英语之外的 13 种语言。
支持的语言有:
from nltk.stem import SnowballStemmer
print(SnowballStemmer.languages)'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish'你可以使用 SnowballStemmer 类的词干函数来词干非英语单词,如下所示:
from nltk.stem import SnowballStemmer
french_stemmer = SnowballStemmer('french')
print(french_stemmer.stem("French word"))法国人可以告诉我们结果:)。
使用 WordNet 词形还原
Word lemmatizing 类似于词干提取,但不同的是词形还原的结果是一个真实的词。
与词干提取不同,当你尝试提取某些词时,会产生如下结果:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('increases'))结果是:
increas现在,如果我们尝试使用 NLTK WordNet 对同一个词进行词形还原,结果是正确的:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('increases'))结果是
increase结果可能以同义词或具有相同含义的不同单词结束。
有时,如果你尝试将单词词形还原为单词 play,最终会得到相同的单词。
这是因为语音的默认部分是名词。要获取动词,你应该像这样指定它:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))结果是:
play这是一个非常好的文本压缩级别;你最终会得到大约 50% 到 60% 的压缩。
结果可能是动词、名词、形容词或副词:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))结果是:
play
playing
playing
playing如何使用Python NLTK?词干提取和词形还原的区别
好的,让我们尝试对一些单词进行词干提取和词形还原,Python NLTK用法示例如下:
from nltk.stem import WordNetLemmatizer
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
print(stemmer.stem('stones'))
print(stemmer.stem('speaking'))
print(stemmer.stem('bedroom'))
print(stemmer.stem('jokes'))
print(stemmer.stem('lisa'))
print(stemmer.stem('purple'))
print('----------------------')
print(lemmatizer.lemmatize('stones'))
print(lemmatizer.lemmatize('speaking'))
print(lemmatizer.lemmatize('bedroom'))
print(lemmatizer.lemmatize('jokes'))
print(lemmatizer.lemmatize('lisa'))
print(lemmatizer.lemmatize('purple'))结果是:
stone
speak
bedroom
joke
lisa
purpl
----------------------
stone
speaking
bedroom
joke
lisa
purplePython NLTK用法教程:Stemming 在不知道上下文的情况下对单词进行处理,这就是为什么 Stemming 比词形还原准确度低且速度快的原因。
在我看来,词形还原优于词干。Word lemmatizing 返回一个真实的单词,即使它不是同一个单词,它可能是同义词,但至少它是一个真实的单词。
有时你并不关心这种级别的准确度,你需要的只是速度;在这种情况下,词干更好。
我们在本Python NLP教程中讨论的所有步骤都是文本预处理,除了这个Python NLTK用法示例,在以后的文章中,我们将讨论使用 Python NLTK 进行文本分析。
我已尽最大努力使文章变得简单和简单。希望对你有帮助。

