
在本处理CSV教程中,我们将探索使用 Python 标准库“csv”读取、写入和编辑 CSV(逗号分隔值)文件的方法。
Python如何读写CSV:由于用于数据库的 CSV 文件的流行,这些方法将被证明对跨不同工作领域的程序员至关重要,本Python处理CSV指南会为你详细探讨这些问题。
CSV 文件未标准化。无论如何,在各种 CSV 文件中都可以看到一些常见的结构。在大多数情况下,CSV 文件的第一行保留用于文件列的标题。
每行后面的行形成一行数据,其中字段按与第一行匹配的顺序排序。顾名思义,数据值通常用逗号分隔,但也可以使用其他分隔符。
最后,当在字段中使用关键字符时,某些 CSV 文件将使用双引号。
本Python处理CSV教程中使用的所有示例都将基于以下虚拟数据文件:basic.csv、multiple_delimiters.csv和new_delimiter.csv。
Python如何处理CSV?CSV处理目录如下:
- 读取 CSV(带标题或不带标题)
- CSV 阅读器编码
- 读取单列(无 Pandas)
- CSV 自定义分隔符
- 带有多个分隔符的 CSV
- 写入 CSV 文件
- 搜索和替换 CSV 文件
- Python 字典转 CSV (DictWriter)
- CSV 到 Python 字典 (DictReader)
- 拆分大型 CSV 文件
读取 CSV(带标题或不带标题)
首先,我们将检查最简单的情况:读取整个 CSV 文件并打印读取的每个项目。
import csv
path = "data/basic.csv"
with open(path, newline='') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
for col in row:
print(col,end=" ")
print()让我们分解这段代码。处理 CSV 文件所需的唯一库是“csv”Python 库。在导入库并设置我们的 CSV 文件的路径后,我们使用“open()”方法开始逐行读取文件。
CSV 文件的解析由“csv.reader()”方法处理,稍后将详细讨论。
我们 CSV 文件的每一行都将作为字符串列表返回,你可以随意处理这些字符串。这是上面代码的输出:
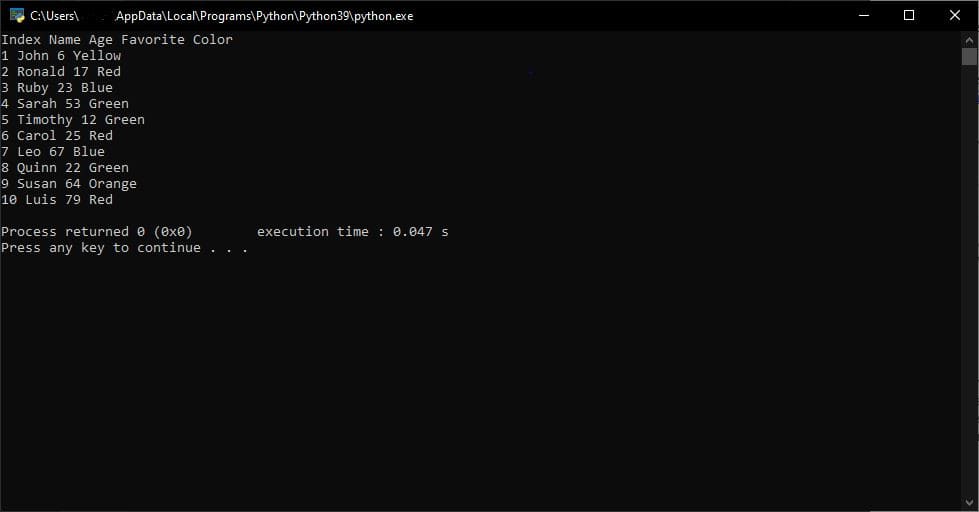
在实践中,我们通常不希望存储 CSV 文件的列的标题。将标题存储在 CSV 的第一行是标准做法。
幸运的是,“csv.reader()”会跟踪在“line_num”对象中读取了多少行。使用这个对象,我们可以简单地跳过 CSV 文件的第一行。
import csv
path = "data/basic.csv"
with open(path, newline='') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if(reader.line_num != 1):
for col in row:
print(col,end=" ")
print()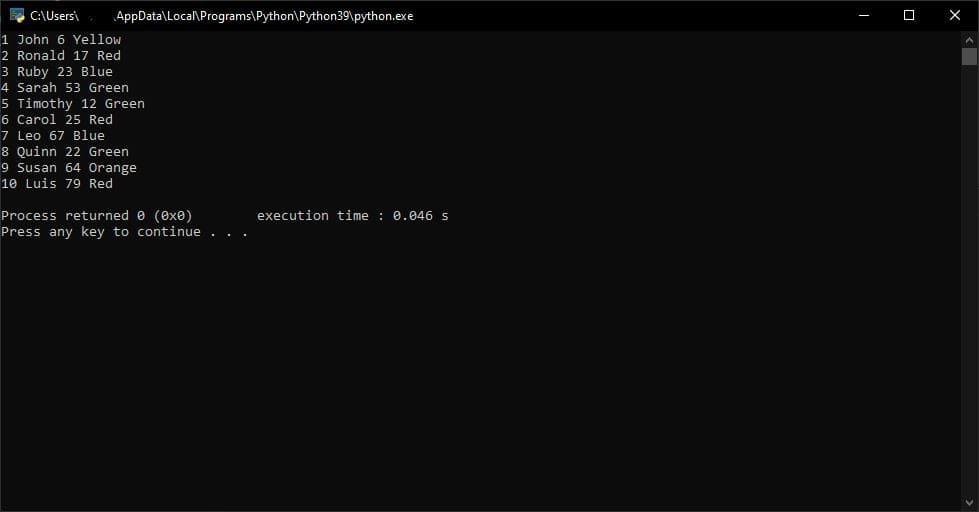
CSV 阅读器编码
在上面的代码中,我们创建了一个名为“reader”的对象,它被分配了“csv.reader()”返回的值。
reader = csv.reader(csvfile)“csv.reader()”方法需要一些有用的参数。我们将只关注两个:“delimiter”参数和“quotechar”。默认情况下,这些参数采用值“,”和“”'。
我们将在下一节讨论分隔符参数。
“quotechar”参数是单个字符,用于定义带有特殊字符的字段。在我们的示例中,我们所有的头文件周围都有这些引号字符。
这允许我们在标题“最喜欢的颜色”中包含一个空格字符。如果我们将“quotechar”更改为“|”,请注意结果如何变化 象征。
import csv
path = "data/basic.csv"
with open(path, newline='') as csvfile:
reader = csv.reader(csvfile, quotechar='|')
for row in reader:
if(reader.line_num != 0):
for col in row:
print(col,end="\t")
print()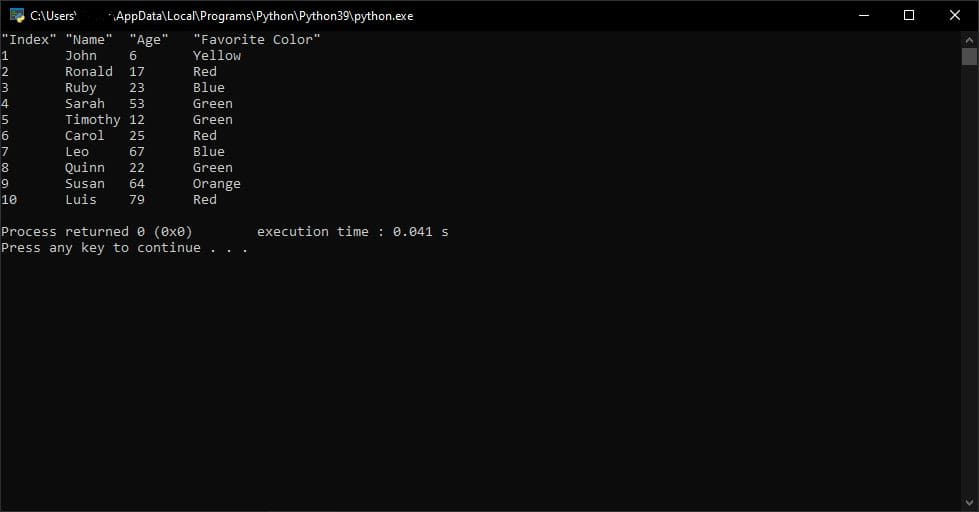
将“quotechar”从'”'更改为“|” 导致标题周围出现双引号。
读取单列(无 Pandas)
Python如何处理CSV?使用我们上面的方法从 CSV 中读取单列很简单。我们的行元素是一个包含列元素的列表。
因此,我们不会打印出整行,而是只从每一行打印出所需的列元素。对于我们的示例,我们将打印出第二列。
import csv
path = "data/basic.csv"
with open(path, newline='') as csvfile:
reader = csv.reader(csvfile, delimiter=',')
for row in reader:
print(row[1])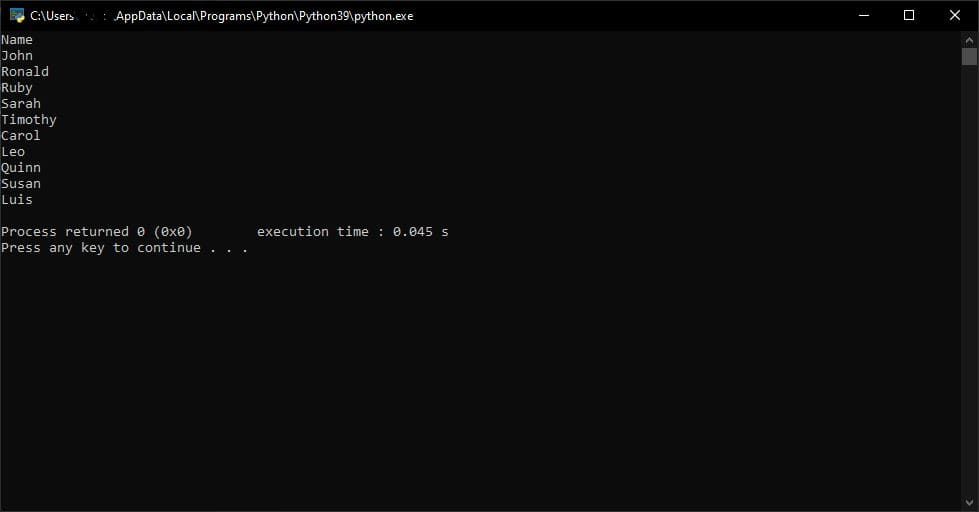
除了本文的Python处理CSV教程,如果你想使用pandas来读取CSV文件,也可以查看pandas教程。
CSV 自定义分隔符
CSV 文件经常使用“,”符号来区分数据值。事实上,逗号符号是 csv.reader() 方法的默认分隔符。
但实际上,数据文件可能会使用其他符号来区分数据值。例如,检查使用“;”的 CSV 文件(称为 new_delimiter.csv)的内容 分隔数据值。
如果我们更改“csv.reader()”方法的“delimiter”参数,则将此 CSV 文件读入 Python 很简单。
reader = csv.reader(csvfile, delimiter=';')请注意我们如何将分隔符参数从“,”更改为“;”。“csv.reader()”方法将通过这个简单的更改按预期解析我们的 CSV 文件。
import csv
path = "data/new_delimiter.csv"
with open(path, newline='') as csvfile:
reader = csv.reader(csvfile, delimiter=';')
for row in reader:
if(reader.line_num != 0):
for col in row:
print(col,end="\t")
print()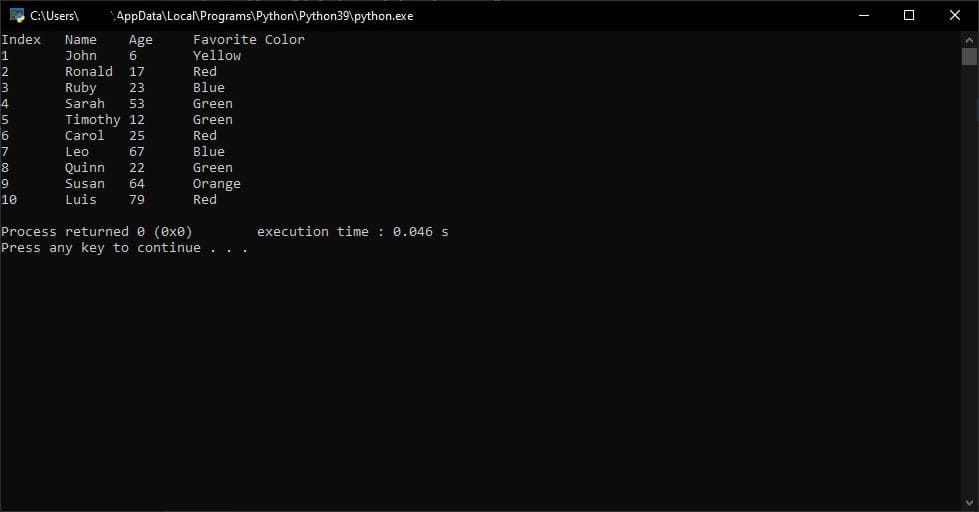
Python处理CSV指南:带有多个分隔符的 CSV
python 中的标准 CSV 包无法处理多个分隔符。为了处理这种情况,我们将使用标准包“re”。
以下示例解析 CSV 文件“multiple_delimiters.csv”。查看“multiple_delimters.csv”中的数据结构,我们看到标题用逗号分隔,其余行用逗号、竖线和文本“分隔符”分隔。
完成所需解析的核心函数是“re.split()”方法,它将两个字符串作为参数:一个表示分隔符的高度结构化的字符串和一个要在这些分隔符处拆分的字符串。首先,让我们看看代码和输出。
import re
path = "data/multiple_delimiters.csv"
with open(path, newline='') as csvfile:
for row in csvfile:
row = re.split('Delimiter|[|]|,|\n', row)
for field in row:
print(field, end='\t')
print()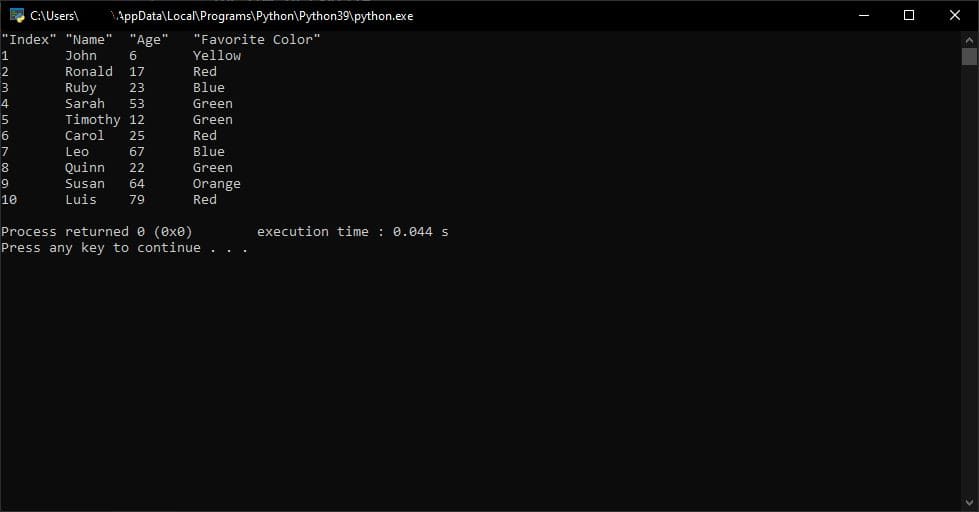
这段代码的关键部分是“re.split()”的第一个参数。
'Delimiter|[|]|,|\n'每个分割点由符号“|”分隔。由于这个符号在我们的文本中也是一个分隔符,我们必须在它周围加上括号来转义字符。
最后,我们将“\n”字符作为分隔符,这样换行符就不会包含在每行的最后一个字段中。要了解这一点的重要性,请检查不包含“\n”作为分割点的结果。
import re
path = "data/multiple_delimiters.csv"
with open(path, newline='') as csvfile:
for row in csvfile:
row = re.split('Delimiter|[|]|,', row)
for field in row:
print(field, end='\t')
print()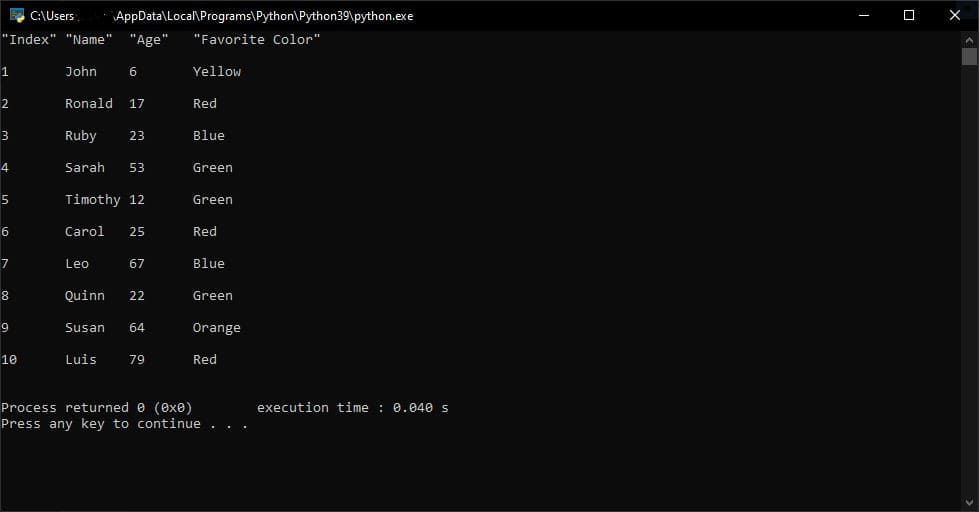
注意我们输出的每一行之间的额外间距。
写入 CSV 文件
写入 CSV 文件将遵循与我们读取文件类似的结构。但是,我们将使用“csv”中的“writer”对象来写入数据,而不是打印数据。
首先,我们将做一个最简单的例子:创建一个 CSV 文件并在其中写入一个标题和一些数据。
import csv
path = "data/write_to_file.csv"
with open(path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['h1'] + ['h2'] + ['h3'])
i = 0
while i < 5:
writer.writerow([i] + [i+1] + [i+2])
i = i+1
Python处理CSV教程:在这个例子中,我们使用“csv.writer()”方法实例化“writer”对象。这样做之后,只需调用“writerow()”方法即可将字符串列表写入文件中的下一行,默认分隔符“,”放置在每个字段元素之间。
Python如何处理CSV?编辑现有 CSV 文件的内容需要以下步骤:读入 CSV 文件数据,编辑列表(更新信息、追加新信息、删除信息),然后将新数据写回 CSV 文件。
Python如何读写CSV:对于我们的示例,我们将编辑在最后一节“write_to_file.csv”中创建的文件。
我们的目标是将第一行数据的值加倍,删除第二行,并在文件末尾追加一行数据。
import csv
path = "data/write_to_file.csv"
#Read in Data
rows = []
with open(path, newline='') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
rows.append(row)
#Edit the Data
rows[1] = ['0','2','4']
del rows[2]
rows.append(['8','9','10'])
#Write the Data to File
with open(path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(rows)
使用前面几节中讨论的技术,我们读取数据并将列表存储在一个名为“行”的变量中。由于所有元素都是 Python 列表,我们使用标准列表方法进行编辑。
我们以与以前相同的方式打开文件。写作时的唯一区别是我们使用了“writerows()”方法而不是“writerow()”方法。
Python处理CSV指南:搜索和替换 CSV 文件
我们已经通过上一节中讨论的过程创建了一种自然的方式来搜索和替换 CSV 文件。在上面的示例中,我们将 CSV 文件的每一行读入一个名为“行”的列表列表中。
由于“行”是一个列表对象,我们可以使用 Python 的列表方法在将 CSV 文件写回文件之前对其进行编辑。我们在示例中使用了一些列表方法,但另一个有用的方法是“list.replace()”方法,它接受两个参数:首先是要查找的字符串,然后是用于替换找到的字符串的字符串。
例如,用 '10's 替换所有的 '3's 我们可以做到
for row in rows:
row = [field.replace('3','10') for field in row]同样,如果数据作为字典对象导入(稍后讨论),我们可以使用 Python 的字典方法在重新写入文件之前编辑数据。
Python 字典转 CSV (DictWriter)
Python 的“csv”库还提供了一种将字典写入 CSV 文件的便捷方法。
import csv
Dictionary1 = {'header1': '5', 'header2': '10', 'header3': '13'}
Dictionary2 = {'header1': '6', 'header2': '11', 'header3': '15'}
Dictionary3 = {'header1': '7', 'header2': '18', 'header3': '17'}
Dictionary4 = {'header1': '8', 'header2': '13', 'header3': '18'}
path = "data/write_to_file.csv"
with open(path, 'w', newline='') as csvfile:
headers = ['header1', 'header2', 'header3']
writer = csv.DictWriter(csvfile, fieldnames=headers)
writer.writeheader()
writer.writerow(Dictionary1)
writer.writerow(Dictionary2)
writer.writerow(Dictionary3)
writer.writerow(Dictionary4)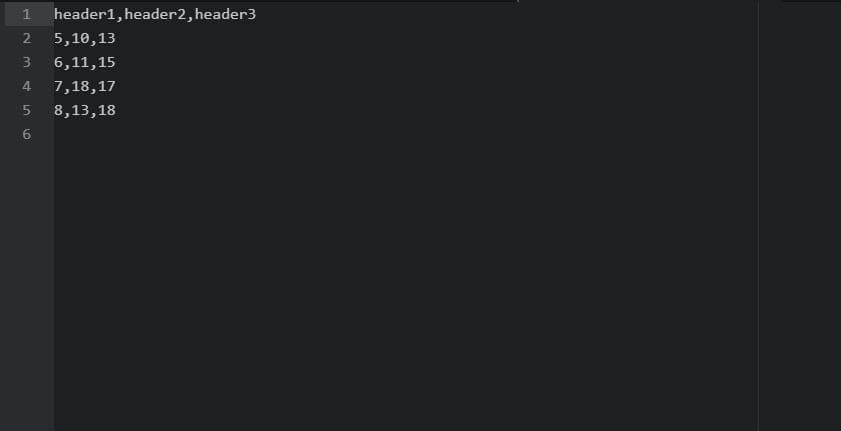
在这个例子中,我们有四个具有相同键的字典。键与 CSV 文件中所需的标题名称相匹配至关重要。
由于我们将作为字典对象输入行,因此我们使用“csv.DictWriter()”方法实例化我们的 writer 对象并指定我们的标题。
完成后,就像调用“writerow()”方法开始写入我们的 CSV 文件一样简单。
CSV 到 Python 字典 (DictReader)
CSV 库还提供了一种直观的“csv.DictReader()”方法,该方法将 CSV 文件中的行输入到字典对象中。这是一个简单的例子。
import csv
path = "data/basic.csv"
with open(path, newline='') as csvfile:
reader = csv.DictReader(csvfile, delimiter=',')
for row in reader:
print(row)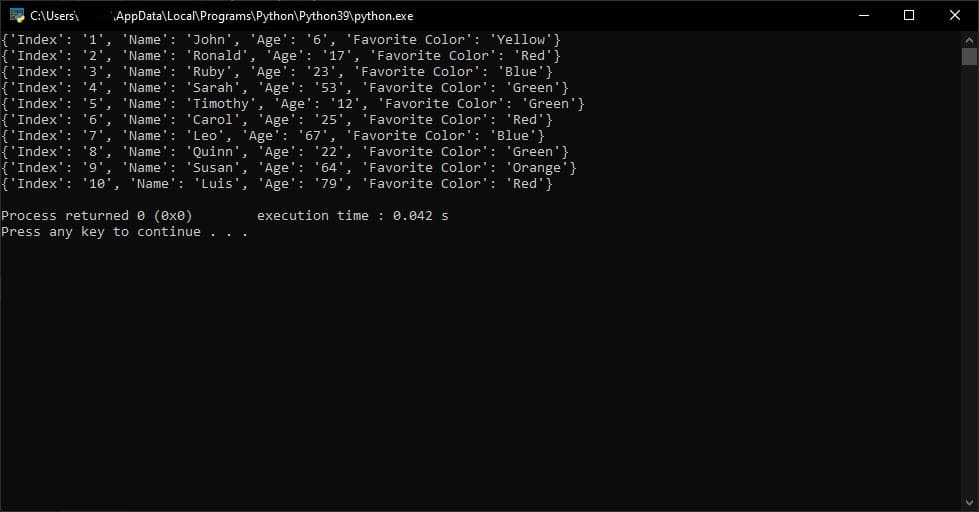
正如我们在输出中看到的,每一行都存储为一个字典对象。
Python处理CSV教程:拆分大型 CSV 文件
如果我们希望将一个大 CSV 文件拆分为较小的 CSV 文件,Python如何处理CSV?我们使用以下步骤进行Python如何读写CSV:将文件作为行列表输入,将前半行写入一个文件,将后半行写入另一个文件。
这是一个简单的例子,我们将“basic.csv”转换为“basic_1.csv”和“basic_2.csv”。
import csv
path = "data/basic.csv"
#Read in Data
rows = []
with open(path, newline='') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
rows.append(row)
Number_of_Rows = len(rows)
#Write Half of the Data to a File
path = "data/basic_1.csv"
with open(path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(rows[0]) #Header
for row in rows[1:int((Number_of_Rows+1)/2)]:
writer.writerow(row)
#Write the Second Half of the Data to a File
path = "data/basic_2.csv"
with open(path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(rows[0]) #Header
for row in rows[int((Number_of_Rows+1)/2):]:
writer.writerow(row)basic_1.csv:
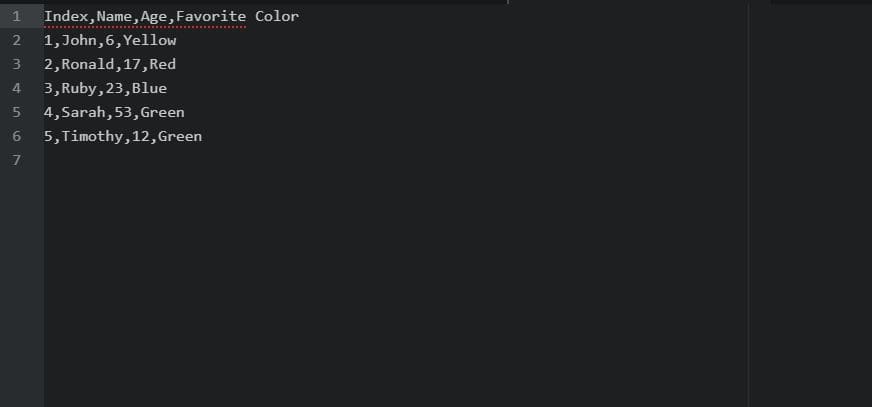
basic_2.csv:
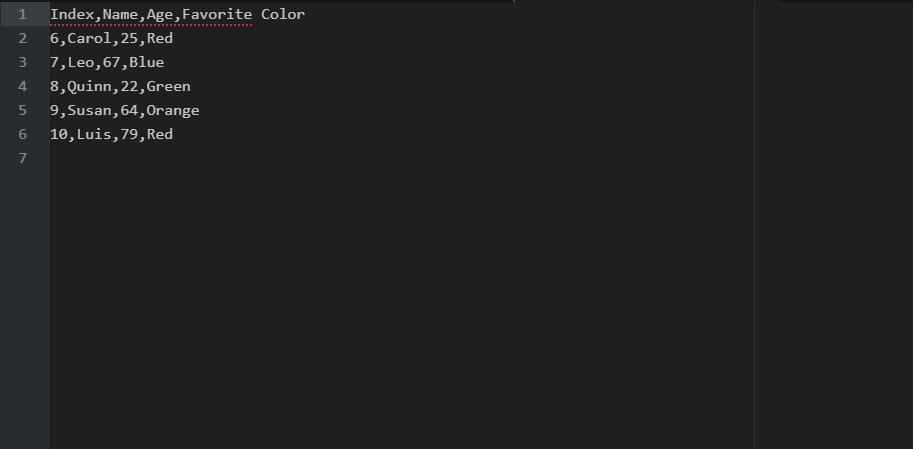
在这些示例中,没有使用新方法。相反,我们有两个单独的 while 循环来处理写入两个 CSV 文件的前半部分和后半部分。以上就是Python处理CSV指南的完整内容,希望这些内容可以帮助到你,如果有任何问题,请在下方评论。

