
在这篇文章中,我将展示一个如何使用Python抓取AJAX页面的示例。
Python爬取ajax概述
Python如何爬取AJAX?Python爬虫ajax页面不仅仅涉及手动查看要抓取的页面的 HTML。这是因为 AJAX 页面使用 javascript 向服务器发出数据请求,然后动态呈现到当前页面中。
接下来,要抓取正在呈现的数据,您必须确定所发出请求的格式和端点,以便您可以复制请求,以及响应的格式,以便您可以解析它。
该AJAX页面,我将展示如何抓取AJAX的页面是 工作页面为 Apple.com。
我在这篇文章中开发的抓取工具使用Requests和 BeautifulSoup。我假设您在 OSX 上使用 Chrome 浏览器。对于使用其他浏览器/操作系统组合的用户,概念保持不变。
Python爬虫相关推荐:Python爬虫模拟登录
Python爬取ajax:查找 AJAX 请求
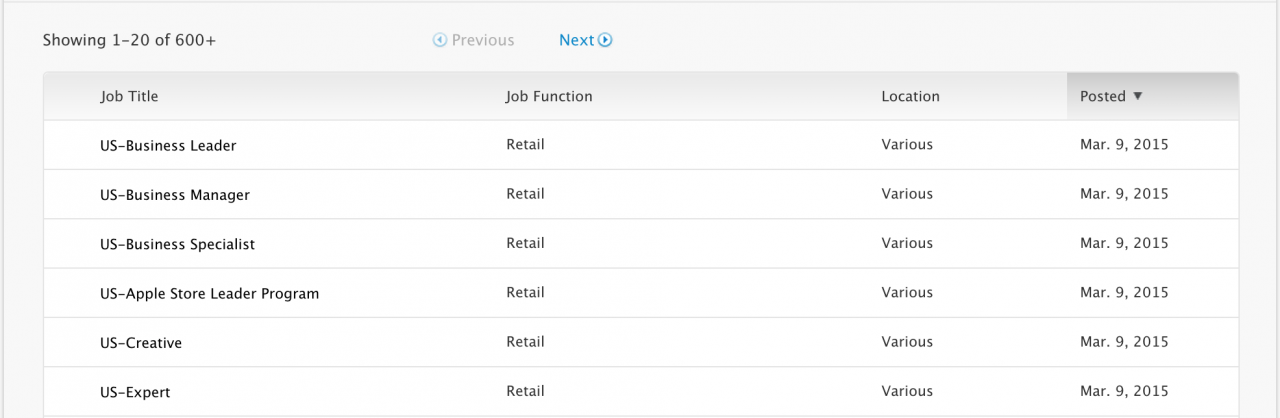
打开页面https://jobs.apple.com/us/search。向下滚动一点,您将看到如下所示的职位列表。
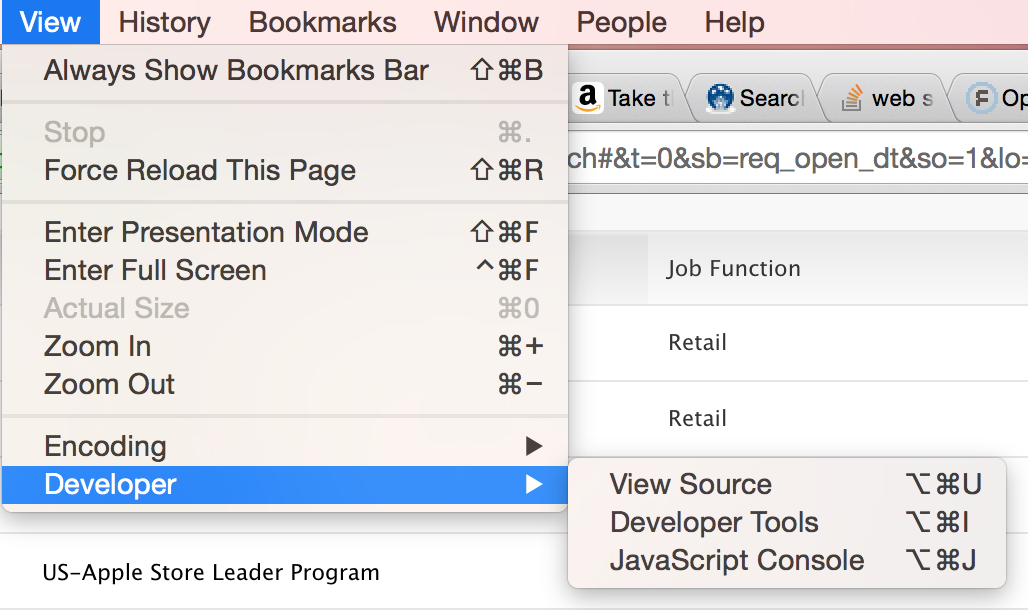
通过选择查看 > 开发人员 > 开发人员工具打开 Chrome 开发人员工具
您的浏览器屏幕应该一分为二,开发人员工具窗口出现在下半部分。选择网络选项卡。
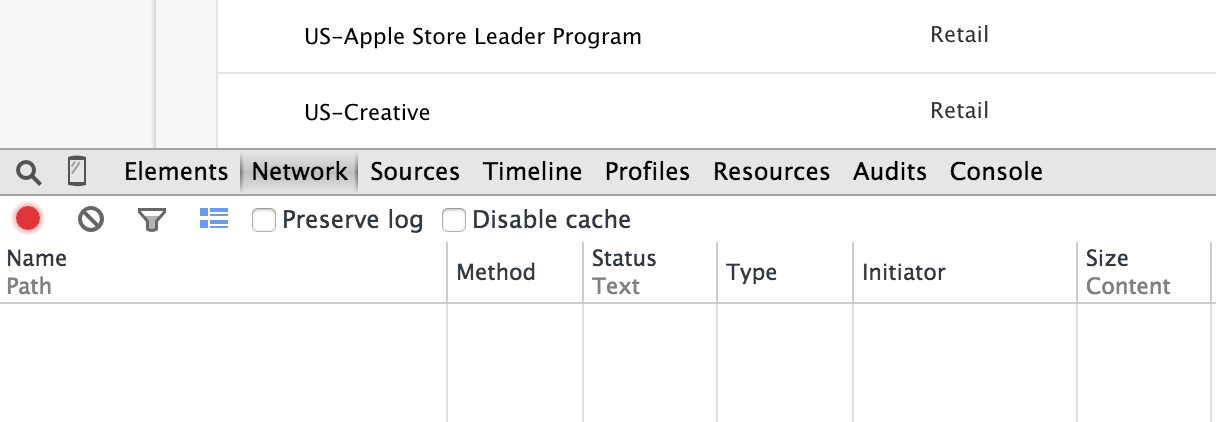
刷新页面。您应该看到 Network 选项卡填满了为 Apple 工作页面发出的 HTTP 请求。向下滚动,直到看到对搜索结果的 POST 请求。

单击该行以查看该请求的详细信息。
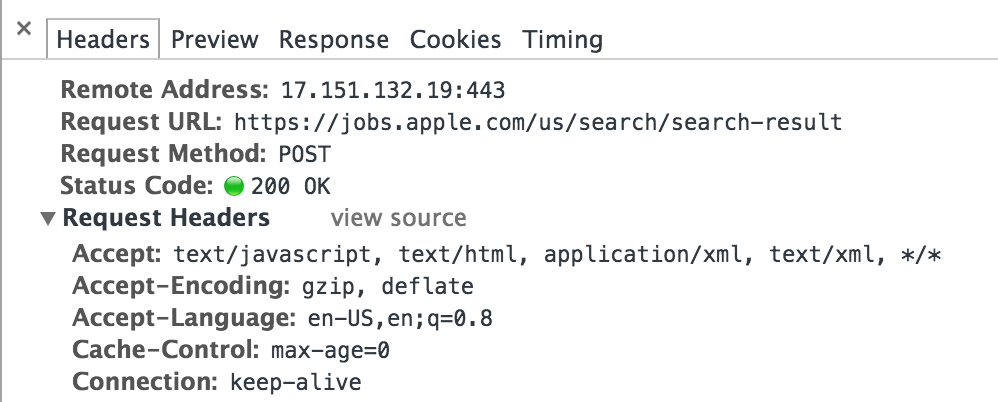
在标题选项卡下,向下滚动直到看到表单数据。

这是检索在页面上呈现的作业的Python爬虫ajax请求。所以要从这个页面抓取作业,我们需要复制这个请求。我们来看看这个请求的细节。
有两个参数:searchRequestJson和clientOffset。我们将在我们的请求中发送两者。该clientOffset 参数是简单的。它只是设置为-300。该searchRequestJson场是比较复杂的。这是一个格式化的列表。
{
"searchString":"",
"jobType":0,
"sortBy":"req_open_dt",
"sortOrder":"1",
"language":null,
"autocomplete":null,
"delta":0,
"numberOfResults":0,
"pageNumber":0,
"internalExternalIndicator":0,
"lastRunDate":0,
"countryLang":null,
"filters":{
"locations":{
"location":[
{
"type":0,
"code":"USA",
"countryCode":null,
"stateCode":null,
"cityCode":null,
"cityName":null
}
]
},
"languageSkills":null,
"jobFunctions":null,
"retailJobSpecs":null,
"businessLine":null,
"hiringManagerId":null
},
"requisitionIds":null
}
该searchRequestionJsonparmater是一个JSON字符串,其pageNumber字段,结果页面返回的请求控件。对于我们检索的每个页面,该字段都会增加。
这是等效的 Python 字典。当我们发送请求时,我们会将这个 dict 转换为 JSON 字符串。
{
"searchString":"",
"jobType":0,
"sortBy":"req_open_dt",
"sortOrder":"1",
"language":None,
"autocomplete":None,
"delta":0,
"numberOfResults":0,
"pageNumber":0,
"internalExternalIndicator":0,
"lastRunDate":0,
"countryLang":None,
"filters":{
"locations":{
"location":[{
"type":0,
"code":"USA",
"countryCode":None,
"stateCode":None,
"cityCode":None,
"cityName":None
}]
},
"languageSkills":None,
"jobFunctions":None,
"retailJobSpecs":None,
"businessLine":None,
"hiringManagerId":None
},
"requisitionIds":None
}
Python抓取AJAX页面:响应格式
接下来单击“响应”选项卡以查看如何为查询返回作业。

作业以 XML 格式返回。如果您选择整个响应并格式化结果,您将获得如下所示的列表。
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<result>
<count>2557</count>
<requisition>
<jobfunction>Retail</jobfunction>
<jobId>USABL</jobId>
<jobTypeCategory>Retail</jobTypeCategory>
<location>Various</location>
<retailPostingDate>Mar. 7, 2015</retailPostingDate>
<retailPostingTitle>US-Business Leader</retailPostingTitle>
</requisition>
<requisition>
<jobfunction>Retail</jobfunction>
<jobId>USABM</jobId>
<jobTypeCategory>Retail</jobTypeCategory>
<location>Various</location>
<retailPostingDate>Mar. 7, 2015</retailPostingDate>
<retailPostingTitle>US-Business Manager</retailPostingTitle>
</requisition>
...
</result>
对于我们的抓取工具,我们将提取列表中每个职位的职位名称、ID 和位置。
Python爬虫ajax:实现Scraper
我们现在有足够的信息来编写我们的Scraper。Python如何爬取AJAX?在我们开始代码之前,让我们总结一下我们需要我们的爬虫做什么:
- 构建
searchRequestJson字典。 - 初始化
searchRequestJson['pageNumber']为 0。 - 将
searchRequestJsondict 转换为 JSON 字符串 https://jobs.apple.com/us/search/search-result使用searchRequestJson和clientOffset参数发送 POST 请求。- 使用 BeautifulSoup 解析 XML 响应并提取每个工作的职位名称、ID 和位置。
- 增加dict的
pageNumber字段searchRequestJson。 - 转到第 3 步以获取下一页结果。
现在让我们编写Python爬取ajax的代码。
首先,创建一个名为AppleJobsScraperdict的类,search_request用于构建searchRequestJson字符串。
#!/usr/bin/env python
import json
import requests
from bs4 import BeautifulSoup
class AppleJobsScraper(object):
def __init__(self):
self.search_request = {
"searchString":"",
"jobType":0,
"sortBy":"req_open_dt",
"sortOrder":"1",
"language":None,
"autocomplete":None,
"delta":0,
"numberOfResults":0,
"pageNumber":None,
"internalExternalIndicator":0,
"lastRunDate":0,
"countryLang":None,
"filters":{
"locations":{
"location":[{
"type":0,
"code":"USA",
"countryCode":None,
"stateCode":None,
"cityCode":None,
"cityName":None
}]
},
"languageSkills":None,
"jobFunctions":None,
"retailJobSpecs":None,
"businessLine":None,
"hiringManagerId":None},
"requisitionIds":None
}
接下来,添加一个名为 的方法scrape。它将调用scrape_jobs并打印返回的作业列表。
def scrape(self):
jobs = self.scrape_jobs()
for job in jobs:
print job
该scrape_jobs方法是我们实现前面讨论Python抓取AJAX页面步骤的地方。
def scrape_jobs(self, max_pages=3):
jobs = []
pageno = 0
self.search_request['pageNumber'] = pageno
while pageno < max_pages:
payload = {
'searchRequestJson': json.dumps(self.search_request),
'clientOffset': '-300'
}
r = requests.post(
url='https://jobs.apple.com/us/search/search-result',
data=payload,
headers={
'X-Requested-With': 'XMLHttpRequest'
}
)
s = BeautifulSoup(r.text)
if not s.requisition:
break
for r in s.findAll('requisition'):
job = {}
job['jobid'] = r.jobid.text
job['title'] = r.postingtitle and \
r.postingtitle.text or r.retailpostingtitle.text
job['location'] = r.location.text
jobs.append(job)
# Next page
pageno += 1
self.search_request['pageNumber'] = pageno
return jobs
Python如何爬取AJAX?下面是实现代码的详细步骤解析:
在第 4 行,我们初始化pageNumber为 0 以获取作业的第一页。
然后在第 7-10 行,我们为将在 POST 请求中发送的参数创建一个字典。我们在此过程中search_request使用转换为 JSON 字符串json.dumps。
接下来在第 12-18 行,我们发送 POST 请求。我已经包含了 headers 参数来展示如何控制请求中发送的标头,但在这种情况下没有必要使请求工作。
发送请求后,我们使用 BeautifulSoup 解析我们的响应并提取所需的字段。
在第 33-34 行,我们增加页面,然后重复我们之前的步骤,直到我们得到max_pages(默认为 3)个结果。
让我们通过实例化Scraper并调用scrape().
if __name__ == '__main__':
scraper = AppleJobsScraper()
scraper.scrape()
现在从命令行运行这个Python爬虫ajax程序:
$ ./scraper.py | head
{'title': u'US-Business Leader', 'location': u'Various', 'jobid': u'USABL'}
{'title': u'US-Business Manager', 'location': u'Various', 'jobid': u'USABM'}
{'title': u'US-Business Specialist', 'location': u'Various', 'jobid': u'USABS'}
{'title': u'US-Apple Store Leader Program', 'location': u'Various', 'jobid': u'USALP'}
{'title': u'US-Creative', 'location': u'Various', 'jobid': u'USACR'}
{'title': u'US-Expert', 'location': u'Various', 'jobid': u'USAEX'}
{'title': u'US-Inventory Specialist', 'location': u'Various', 'jobid': u'USAIS'}
{'title': u'US-Manager', 'location': u'Various', 'jobid': u'USAMN'}
{'title': u'US-Market Leader', 'location': u'Various', 'jobid': u'USAML'}
{'title': u'US-Genius', 'location': u'Various', 'jobid': u'USAGN'}
如果您想查看完整的Python抓取AJAX页面的实现,可以在github上找到本文的源代码 。

