
一旦您了解了 Scrapy 的基础知识,第一个复杂问题就是必须处理Python爬虫模拟登录。这样做有助于了解登录的工作原理以及如何在浏览器中观察该过程。Python爬虫怎么模拟登录?我们将在本文中讨论这个以及scrapy如何处理登录过程。
在这篇文章中你将学到
- 如何使用 FormRequest 类进行简单的Python爬虫登录过程
- 如何使用该
fromresponse方法进行更复杂的登录程序 - 如何做基本的 XPATH 选择器
- 了解会话和令牌浏览器身份验证的区别
- CSRF 是什么以及为什么了解它很重要
- 如何处理 Scrapy 中的令牌认证
简单的登录程序
当您将数据输入网站表单字段时,这些数据会被打包。浏览器将在头中发送一个 POST 请求。登录时可以有很多 POST 和重定向请求。
要做到牛逼,他中最简单的在Scrapy我们可以使用Scrapy的FormRequest类登录程序。实际上,最好使用 FormRequests 方法之一来处理表单数据,但稍后会详细介绍!
有了这个,让我们先看看它是如何工作的,然后再以此为基础。要在我们的爬虫蜘蛛中使用它,我们必须先导入它。
from scrapy.http import FormRequest现在start_url我们使用一种start_requests()方法,而不是在我们的蜘蛛开始时使用。这允许我们使用与表单填写相关的方法。
让我们深入了解 scrapy.spider 代码,看看它是如何工作的。请记住,这是我们在启动蜘蛛时总是提到的地方。
当我们start_requests()从那个类调用方法时,这就是幕后的东西。
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)在这里,我们循环遍历start_urls. 对于每个 url,我们使用该scrapy.requests()方法并传递一个 url 和一个名为 dont_filter 的关键字。现在dont_filter=True意味着不过滤重复的请求。
通过使用 FormRequest 子类,我们扩展了scrapy.http.Request该类。FormRequest 为我们提供了从响应中预填充表单字段的功能。我们扩展scrapy.http.Request并访问它的所有关键字参数。
让我们看看这是什么样子。
from scrapy.http import FormRequests
import scrapy
def start_requests(self):
return [
FormRequest("INSERT URL", formdata={"user":"user",
"pass":"pass"}, callback=self.parse)]
def parse(self,response):
pass注意
1. 默认parse()函数处理脚本的响应和规则以获取您想要的数据。
2. 在函数中,start_request我们使用 FormRequest 类。我们为它提供一个 url 和关键字参数 formdata 以及我们的用户名和密码。
3. Scrapy 为我们处理 cookie,而我们无需在start_request.
4. 我们使用回调关键字参数将蜘蛛引导至解析函数。

Python爬虫怎么模拟登录?隐藏数据
有些站点会要求您传递乍一看似乎并不重要的表单数据。要登录,需要通过 cookie 对网站进行身份验证。有时页面有一个需要传递的隐藏字段。获得该值的唯一方法是通过登录。
为了解决这个问题,我们需要做两个请求,一个请求传递一些数据并捕获隐藏字段数据。第二个登录请求。
这次我们将使用一个start_request函数,但会传递第一个请求。我们将处理回调以将信息传递给第二个函数。
对于第二个请求,我们将使用该FormRequest.from_response()方法。此方法使用我们指定的字段中填充的数据模拟点击。事实上,from_response()返回一个新的 FormRequest 对象。此对象的默认设置是模拟具有 类型的可点击项目的点击<input_type=submit>。
我们可以在from_response()方法中指定不同的方式。建议参考scrapy文档!例如,如果你不想让scrapy 点击你可以使用关键字dont_click=True。from_response()方法中的所有参数都传递给 FormRequest。
def start_requests():
return [
Request("URL", callback = self.parse_item)
]
def parse_item(self,response):
return FormRequest.from_response(response, formdata=
{'user':'user', 'pass':'pass'})在这里,我们获得所需的标头,start_requests()然后将其传递给parse_item()
使用FormRequest.from_response()我们传递带有适当标题的表单数据。

浏览器身份验证基础知识
HTTP 是一种无状态协议。这意味着从请求到响应没有消息状态的记录。如果您作为请求登录,则会在另一个请求中忘记这一点。烦人什么的!
第一个解决方案是创建一个会话。当我们执行 POST 请求时,会在服务器数据库中创建一个会话。一个 cookie,它是一个字典,它附加到具有会话 ID 的响应。cookie 被返回给浏览器。
当我们用这个 cookie 尝试另一个请求时,服务器会查找它并检查会话 ID。获取配置文件数据匹配并将响应发送回浏览器。
Cookie 身份验证是有状态的。身份验证记录存储在客户端和服务器端。
现在我们有了单页应用程序,前端和后端的解耦要复杂得多!当与另一台服务器联系时,我们从一台服务器获得的会话 cookie 将不起作用。这就是基于令牌的身份验证的用武之地。

Python爬虫模拟登录:基于令牌的身份验证
令牌是另一种浏览器身份验证方法。现在使用的标准令牌是 Json Web 令牌 (JWT)。
基于令牌的身份验证的优点是它是无状态的。服务器不记录哪些用户登录。每个请求都有一个令牌,服务器用它来检查真实性。令牌通常在授权头承载 (JWT) 中发送,但也可以在 POST 请求的正文中。
JWT 由三部分组成,头部、PAYLOAD和签名
###HEADER###
{
"alg": "HS256",
"typ": "JWT"
}
###PAYLOAD###
{
"sub": "1234567890",
"name": "John Doe",
"iat": 1516239022
}
###SIGNATURE###
{
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload),
secret)现在 JWT 使用编码算法进行签名。例如 HMACSHA256 看起来像这样。
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkFkbyBLdWtpYyIsImFkbWluIjp0cnVlLCJpYXQiOjE0这可以使用像这里这样的网站进行解码,重要的是要知道数据没有加密。
用户输入登录详细信息并附加令牌。然后服务器验证登录是否正确,然后对发送的令牌进行签名。此令牌存储在客户端,但实际上可以存储为会话或 cookie。请记住,cookie 是键和值的字典。
Python爬虫怎么模拟登录?对服务器的请求包括此令牌以进行身份验证。服务器解码此令牌,如果令牌有效,则请求将被发回。当用户注销时,令牌在客户端被销毁。不与服务器交互。这为我们提供了一些安全性。

CSRF 是关于什么的?
Python爬虫登录过程:在谈论基于令牌的身份验证时,您将在这里使用这个术语。所以了解它们很有用。这就是为什么基于令牌的身份验证变得流行的核心。
CSRF 代表跨站请求伪造,是一个网络安全漏洞。它允许攻击者让用户执行他们不打算执行的操作。例如,通过更改帐户的电子邮件地址。
要发生 CSRF 攻击,需要三件事。首先是应用程序内有理由更改的相关操作。基于 cookie 的会话处理以进行身份验证,并且没有不可预测的请求参数。
有了这些,攻击者就可以创建一个带有更改电子邮件地址表单的网页。用户输入数据,表单在对原始网站的请求中使用用户会话 cookie。但改用新的电子邮件地址。
为了处理这种攻击,我们可以使用令牌来检查用户而不是基于会话的 cookie。

使用 Scrapy 处理基于令牌的身份验证
要确定是否有必要使用令牌,我们必须使用 chrome/firefox 开发人员工具。为此,我们将抓取quotes.toscrape.com。我们实现Python爬虫模拟登录过程并查看发送了哪些标头。为此,我们在登录前滚动到网络选项卡,然后模拟登录过程。所有请求都将出现在下方。
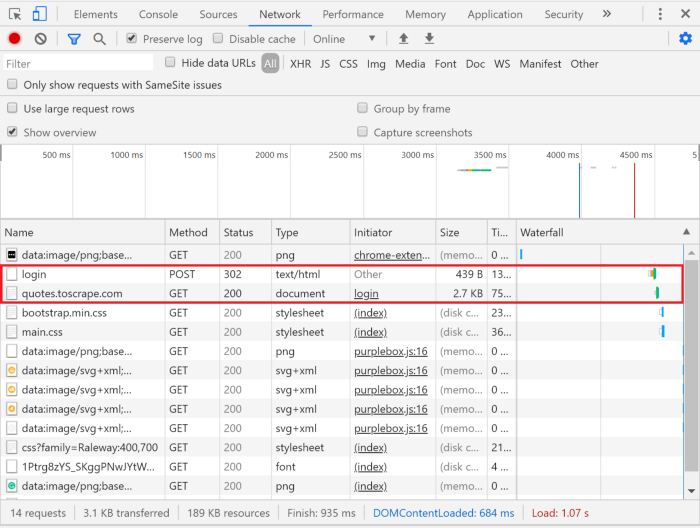
选择左侧的登录名可以让我们看到下面的请求标头。
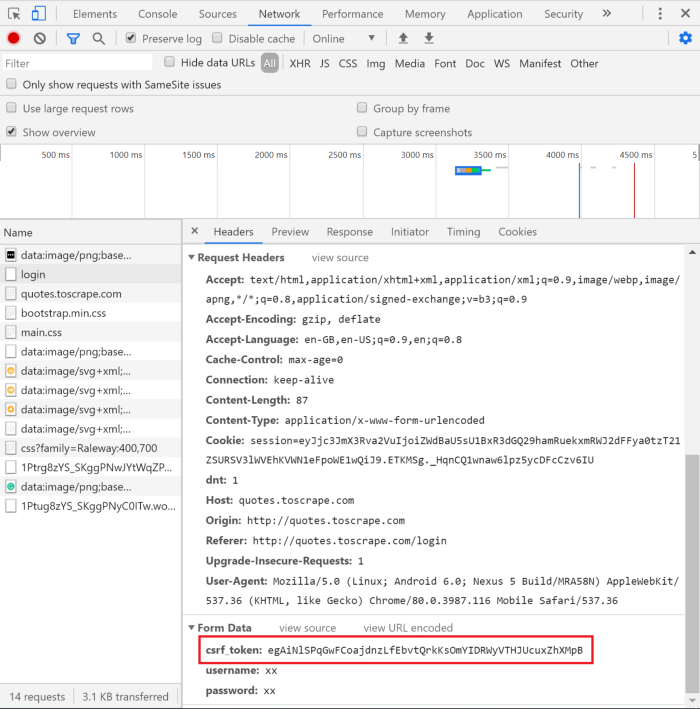
正如您在表单数据中看到的那样csrf_token。
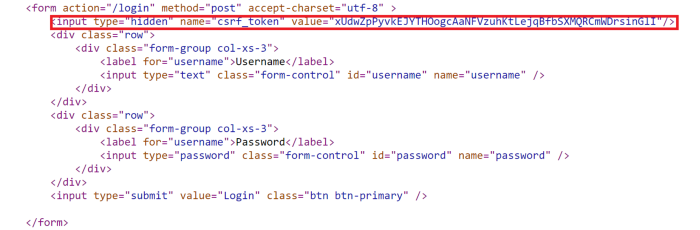
请记住,当我们注销时,此令牌会被销毁。我们有必要在将其作为 POST 请求发送之前获取它。为此,我们必须查看 HTML。下面看到的表单的 html 标签。
我们可以在表单字段中看到这里 <input=’Hidden’ name=’csrf_token’> value=”xxx”>
Python爬虫登录过程:XPATH 基础
现在要进行任何报废,去 shell 看看 xpath 选择器是否能在你的蜘蛛中工作是很有用的。所以在这里我们获取 url 并测试我们需要的 xpath。
fetch("url")
response.xpath('//*[@name='csrf_token']/@value').extract_first()输出
u'xUdwZpPyvkEJYTHOogcAaNFVzuhKtLejqBfbSXMQRCmWDrsinGlI'让我们分解 xpath 选择器。
首先,xpath 将 html 文档作为树进行处理,并将文档分成多个节点。根节点是文档元素的父节点<html>。元素节点代表 html 标签。属性节点表示来自元素节点的任何属性。文本节点表示元素节点中的任何文本。
第一个//是 adescendant-or-self这意味着它选择当前节点或它下面的任何节点。//*表示选择所有没有注释或文本节点的节点。
我们[@用来指定属性csrf_token,/@然后指定它的值。extract_first()将获取它找到的第一个值。
所以我们有我们的 xpath 选择器来获取csrf_token,然后我们可以使用它来传递给 FormRequest
现在我们有了这种理解,我们可以查看使用它的代码。
import scrapy
from scrapy.http import FormRequests
class LoginSpider(Scrapy.spider):
name = 'login'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/login']
def parse(self,response):
csrf_token = response.xpath('//*[@name='csrf_token']
/@value').extract_first()')
yield FormRequests.from_response(response, formdata={'csrf_token': csrf_token, 'user':'user', 'pass','pass'}, callback=self.parse_after_login)
def parse_after_login(self,response):
passPython爬虫怎么模拟登录?注意事项
1. 我们像以前一样导入scrapy和FormRequests
2. 我们填充变量name,allowed_domains和start_urls。
3. 我们csrf_token为登录页面中的令牌分配给 xpath 选择器值。
4. 使用 FormRequests 子类指定响应,并输入我们想要的表单数据。在这种情况下,我们指定csrf_token用户名和密码。
5. Python爬虫模拟登录成功后,使用回调将蜘蛛引向该函数。
呼!挺能通过的。希望使 Scrapy 的Python爬虫登录过程更易于管理。直到下一次!

