
数据:
可以是任何未经解释和分析的未经处理的事实, 值, 文本, 声音或图片。数据是所有数据分析, 机器学习和人工智能中最重要的部分。没有数据, 我们就无法训练任何模型, 所有现代研究和自动化都将徒劳无功。大企业正在花费大量金钱只是为了收集尽可能多的某些数据。
例子:
为什么Facebook要以190亿美元的巨额价格收购WhatsApp?
答案非常简单且合乎逻辑-可以访问Facebook可能没有但WhatsApp将拥有的用户信息。用户的信息对于Facebook至关重要, 因为这将有助于改善他们的服务。
信息:
已经被解释和操纵的数据, 现在对用户具有一些有意义的推断。
知识:
推断信息, 经验, 学习和见识的结合。导致个人或组织的意识或概念建立。

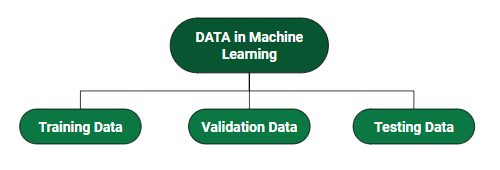
我们如何在机器学习中拆分数据?
- 训练数据:我们用来训练模型的数据部分。这是模型实际看到的数据(输入和输出)并从中学习。
- 验证数据:用来对模型进行频繁评估的那部分数据适合于训练数据集, 同时改善了所涉及的超参数(在模型开始学习之前初始设置参数)。在实际训练模型时, 这些数据将发挥重要作用。
- 测试数据:一旦我们的模型经过全面训练, 测试数据即可提供公正的评估。当我们输入测试数据的输入时, 我们的模型将预测一些值(看不到实际输出)。经过预测, 我们通过将模型与测试数据中存在的实际输出进行比较来评估模型。这是我们进行评估的方式, 并了解我们的模型从作为培训数据设置的培训数据中获得的经验教训。
考虑一个例子:
有一家购物市场的拥有者进行了一项调查, 他为此列出了一长串向客户询问的问题和答案, 这些问题和答案是
数据
。现在, 每当他想推断任何东西, 而不仅仅是遍历成千上万个客户的每个问题, 以找到相关的东西时, 这将是耗时且无济于事的。为了减少这种开销和时间浪费并简化工作, 根据自己的便利, 通过软件, 计算, 图形等对数据进行操作, 从操作数据得出的推论是
信息
。因此, 数据必不可少。现在
知识
在区分具有相同信息的两个人方面发挥作用。知识实际上不是技术内容, 而是与人类的思维过程相关联。
数据属性–
- 数量:数据规模。随着世界人口和技术的不断增长, 每一毫秒都会生成大量数据。
- 品种:不同形式的数据–医疗保健, 图像, 视频, 音频剪辑。
- 速度:数据流和生成的速率。
- 值:研究人员可以从数据中推断出数据的意义。
- 准确性:我们正在处理的数据的确定性和正确性。
有关数据的一些事实:
- 与2005年相比, 到2020年将产生300倍的数据, 即40 Zettabytes(1ZB = 10 ^ 21字节)。
- 到2011年, 医疗保健行业的数据将达到1610亿千兆字节
- 每天大约有2亿活跃用户发送4亿条推文
- 每个月, 用户完成的视频流超过40亿小时。
- 用户每月共享300亿种不同类型的内容。
- 据报道, 大约27%的数据不准确, 因此, 三分之二的商业理想主义者或领导者不信任他们做出决策所依据的信息。
上述事实只是对实际存在的大量数据统计信息的一瞥。当我们谈论现实世界场景时, 当前存在且每时每刻都在生成的数据量超出了我们的想象力。

