
逻辑回归和决策树分类是当今使用的两种最流行和最基本的分类算法。没有一种算法比另一种算法更好, 并且一个人的出色性能通常归因于正在处理的数据的性质。
我们可以在不同类别上比较这两种算法–
| 标准 | 逻辑回归 | 决策树分类 |
|---|---|---|
| 可解释性 | 难以解释 | 更可解释 |
| 决策边界 | 线性和单一决策边界 | 将空间分成较小的空间 |
| 易于决策 | 必须设置决策阈值 | 自动处理决策 |
| 过度拟合 | 不容易过拟合 | 容易过拟合 |
| 噪音强 | 噪音强 | 受噪音影响较大 |
| 可扩展性 | 需要足够大的训练集 | 可以在小型训练套件上进行训练 |
作为一个简单的实验, 我们在相同的数据集上运行两个模型并比较它们的性能。
步骤1:导入所需的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier步骤2:读取和清理数据集
cd C:\Users\Dev\Desktop\Kaggle\Sinking Titanic
# Changing the working location to the location of the file
df = pd.read_csv( '_train.csv' )
y = df[ 'Survived' ]
X = df.drop( 'Survived' , axis = 1 )
X = X.drop([ 'Name' , 'Ticket' , 'Cabin' , 'Embarked' ], axis = 1 )
X = X.replace([ 'male' , 'female' ], [ 2 , 3 ])
# Hot-encoding the categorical variables
X.fillna(method = 'ffill' , inplace = True )
# Handling the missing values步骤3:训练和评估Logisitc回归模型
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3 , random_state = 0 )
lr = LogisticRegression()
lr.fit(X_train, y_train)
print (lr.score(X_test, y_test))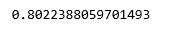
步骤4:训练和评估决策树分类器模型
criteria = [ 'gini' , 'entropy' ]
scores = {}
for c in criteria:
dt = DecisionTreeClassifier(criterion = c)
dt.fit(X_train, y_train)
test_score = dt.score(X_test, y_test)
scores = test_score
print (scores)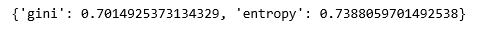
通过比较分数, 我们可以看到逻辑回归模型在当前数据集上的表现更好, 但并非总是如此。
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。

