
人工智能和电脑游戏领域的先驱阿瑟·塞缪尔创造了“机器学习”这个术语。他将机器学习定义为:“一种研究领域,它让计算机能够在没有明确编程的情况下进行学习。”
以非常普通的方式, 机器学习(ML)可以解释为基于计算机的经验来自动化和改善计算机的学习过程, 而无需实际编程, 即无需任何人工帮助。该过程从提供高质量数据开始, 然后通过使用数据和不同算法构建机器学习模型来训练我们的机器(计算机)。算法的选择取决于我们拥有什么类型的数据以及我们要自动化的任务类型。
示例:考试期间对学生的培训。
在准备考试时, 学生实际上并不是在补习该科目, 而是尝试在完全理解的情况下进行学习。在检查之前, 他们会向他们的机器(大脑)提供大量高质量的数据(来自不同书籍或教师笔记或在线视频讲座的问题和答案)。实际上, 他们正在用输入和输出来训练大脑, 即他们必须采用哪种方法或逻辑来解决不同类型的问题。每次他们解决练习试卷并通过将答案与给出的答案键进行比较来找到性能(准确性/分数)时, 性能会不断提高, 并通过采用的方法获得更多的信心。这就是实际构建模型的方式, 使用数据训练机器(输入和输出都提供给模型), 以及何时对数据进行测试(仅输入), 并通过将其答案与未提供数据的实际输出进行比较来获得模型得分在训练时被喂饱了。研究人员正在努力改进算法和技术, 以使这些模型的性能更好
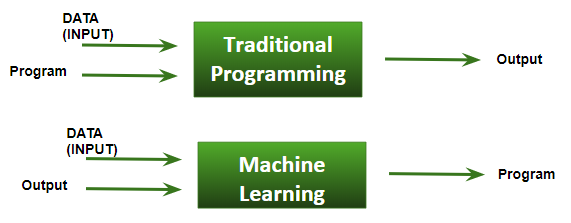
ML和传统编程的基本区别?
- 传统编程:我们输入DATA(输入)+ PROGRAM(逻辑), 在计算机上运行它并获得输出。
- 机器学习:我们输入DATA(输入)+输出, 在训练期间在机器上运行它, 并且机器创建自己的程序(逻辑), 可以在测试时对其进行评估。
学习对计算机到底意味着什么?
据说计算机正在从中学习体会关于某类任务, 如果它在给定任务中的表现随经验而提高。
一个计算机程序据说会从经验E中学习一些任务T和性能测量P,如果它在T中任务的性能(由P测量)随着经验E的提高而提高
例如:玩跳棋。
E =玩许多跳棋游戏的经验
T=下棋的任务。
P =程序在下一场比赛中获胜的概率
通常, 可以将任何机器学习问题分配给以下两种广泛的分类之一:
监督学习和无监督学习。
现实中的事物如何运作:-
谈到在线购物, 有成千上万的用户对品牌, 颜色, 价格范围等有无限的兴趣。在进行网上购物时, 买家倾向于搜索许多产品。现在, 频繁搜索产品将使买家的Facebook, 网页, 搜索引擎或在线商店开始推荐或显示该特定产品的报价。没有人坐在那里为每个用户编写这样的任务, 所有这些任务是完全自动的。 ML在这里发挥作用。研究人员, 数据科学家, 机器学习者使用高质量和大量数据在机器上构建模型, 现在他们的机器可以自动运行, 甚至通过越来越多的经验和时间来进行改进。
传统上, 广告仅使用报纸, 杂志和广播进行, 但是现在技术使我们足够聪明, 可以做定向广告(在线广告系统), 这是一种针对大多数接受受众的有效方法。
即使在医疗保健方面, ML的工作也非常出色。研究人员和科学家准备了训练机器的模型, 用于
检测癌症
只看幻灯片–细胞图像。为了使人类执行此任务, 将花费大量时间。但是现在, 机器不再需要延迟, 机器可以准确地预测是否患有癌症的机会, 而医生只需给出保证电话就可以了。答案(如何实现)非常简单-所需要的只是一台高性能的计算机, 大量高质量的图像数据, 具有良好算法的ML模型, 以实现最新的结果。
医生甚至在使用ML
诊断病人
基于正在考虑的不同参数。
你们可能都使用过IMDB评级, 可以识别人脸的Google相册, 可以使用ML图像文本识别模型从中提取图像的Google Lens, 可以将电子邮件分类为社交, 促销, 更新或论坛的Gmail, 文本分类, 这是ML的一部分。
机器学习如何工作?
以适合处理的任何形式收集过去的数据, 数据质量越好, 越适合建模
数据处理–有时, 收集的数据是原始格式, 需要进行预处理。
示例:某些元组可能缺少某些属性的值, 在这种情况下, 为了执行机器学习或任何形式的数据挖掘, 必须将其填充合适的值。
诸如房屋价格之类的数字属性的缺失值可以用属性的平均值替换, 而类别属性的缺失值可以用最高模式的属性替换。这总是取决于我们使用的过滤器的类型。如果数据是文本或图像形式, 则需要将其转换为数字形式, 无论是列表, 数组还是矩阵。简而言之, 要使数据具有相关性和一致性。将其转换为机器可以理解的格式
将输入数据分为训练, 交叉验证和测试集。两组之间的比例必须为6:2:2
在训练集上使用合适的算法和技术构建模型。
使用训练时未提供给模型的数据测试我们的概念化模型, 并使用F1得分, 准确性和召回率等指标评估其性能。
学习机器学习的先决条件:
- 线性代数
- 统计与概率
- 结石
- 图论
- 编程技巧–语言, 例如Python, R, MATLAB, C ++或Octave

