
无监督学习:
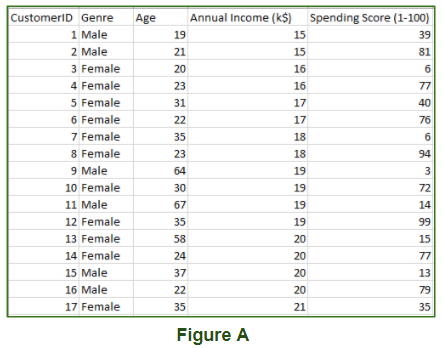
这是一种学习, 我们在训练时不给模型指定目标, 即训练模型仅输入参数值。该模型本身必须找到可以学习的方式。图A中的数据集是购物中心数据, 其中包含订阅其客户的客户的信息。订阅后, 他们将获得一张会员卡, 因此, 商场将获得有关客户及其每次购买的完整信息。现在, 使用这些数据和无监督的学习技术, 商城可以轻松地根据我们输入的参数对客户进行分组。
我们提供的训练数据是–
- 非结构化数据:可能包含嘈杂(无意义)的数据, 缺失的值或未知的数据
- 未标记的数据:数据仅包含输入参数的值, 没有目标值(输出)。与"监督"方法中标记为"一个"的标签相比, 它很容易收集。
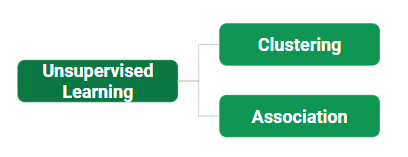
无监督学习的类型:
- 聚类:我们的机器模型发现, 该技术广泛应用于基于不同模式的分组数据。例如, 在上图中, 我们没有得到输出参数值, 因此将使用此技术根据数据提供的输入参数对客户端进行分组。
- 协会:该技术是一种基于规则的ML技术, 可发现大型数据集的参数之间的某些非常有用的关系。例如购物商店使用基于此技术的算法来根据客户行为找出某件商品的销售与其他商品之间的关系。一旦训练有素, 这些模型就可以用于通过计划不同的报价来增加销售量。
一些算法:
K均值聚类
DBSCAN –带有噪声的应用程序的基于密度的空间聚类
BIRCH –使用层次结构的平衡迭代减少和聚类
层次聚类
半监督学习:
顾名思义, 它的工作介于有监督技术和无监督技术之间。当我们处理有点标记的数据而其余大部分未标记的数据时, 我们会使用这些技术。我们可以使用非监督技术来预测标签, 然后将这些标签提供给监督技术。此技术通常适用于通常未标记所有图像的图像数据集的情况。
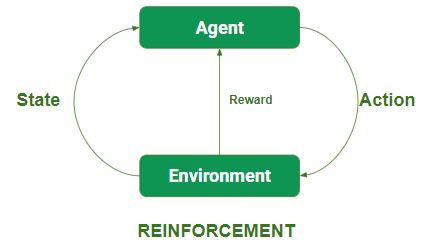
强化学习:
在这种技术中, 模型使用奖励反馈来学习行为或模式, 从而不断提高其性能。这些算法特定于特定问题, 例如Google自驾车AlphaGo, 机器人可以与人甚至自己竞争, 以提高Go Game的性能。每次我们输入数据时, 他们都会学习并将数据添加到它的知识即训练数据中。因此, 它学习的越多, 就越能得到训练并因此经验丰富。
代理观察输入。
代理通过做出一些决定来执行操作。
在执行之后, 代理会获得奖励并相应地得到加强, 并且模型将状态-状态信息对存储。
一些算法:
时差(TD)
Q学习
深度对抗网络
希望你喜欢这篇文章
![从字法上最小长度N的排列,使得对于正好为K个索引,a[i] a[i]+1](https://www.lsbin.com/wp-content/themes/begin%20lts/img/loading.png)
