
Bagging分类器是一个集合元估计器, 它使每个基本分类器适合原始数据集的随机子集, 然后将其单个预测(通过投票或平均)进行汇总以形成最终预测。通过将随机化引入其构造过程中, 然后对其进行整体化, 这样的元估计器通常可以用作减少黑盒估计器(例如, 决策树)的方差的方式。
每个基本分类器均与训练集并行训练, 该训练集是通过从原始训练数据集中随机绘制并替换N个示例(或数据)而生成的,其中N是原始训练集的大小。每个基本分类器的训练集彼此独立。许多原始数据可能会在结果训练集中重复, 而其他一些数据可能会被忽略。
套袋可通过平均或投票减少过拟合(方差), 但是, 这会导致偏差增加, 不过可以通过方差的减少来补偿。
套袋如何在训练数据集上工作?
套袋如何在虚构训练数据集上工作, 如下所示。由于Bagging用替换对原始训练数据集进行了重新采样, 因此某些实例(或数据)可能会多次显示, 而另一些则被忽略。
原始训练数据集:1, 2, 3, 4, 5, 6, 7, 8, 9, 10
重采样训练集1:2, 3, 3, 5, 6, 1, 8, 10, 9, 1
重采样训练集2:1、1、5、6、3、8、9、10、2、7
重采样训练集3:1、5、8、9、2、10、9、7、5、4
套袋分类器的算法:
Classifier generation:
Let N be the size of the training set.
for each of t iterations:
sample N instances with replacement from the original training set.
apply the learning algorithm to the sample.
store the resulting classifier.
Classification:
for each of the t classifiers:
predict class of instance using classifier.
return class that was predicted most often.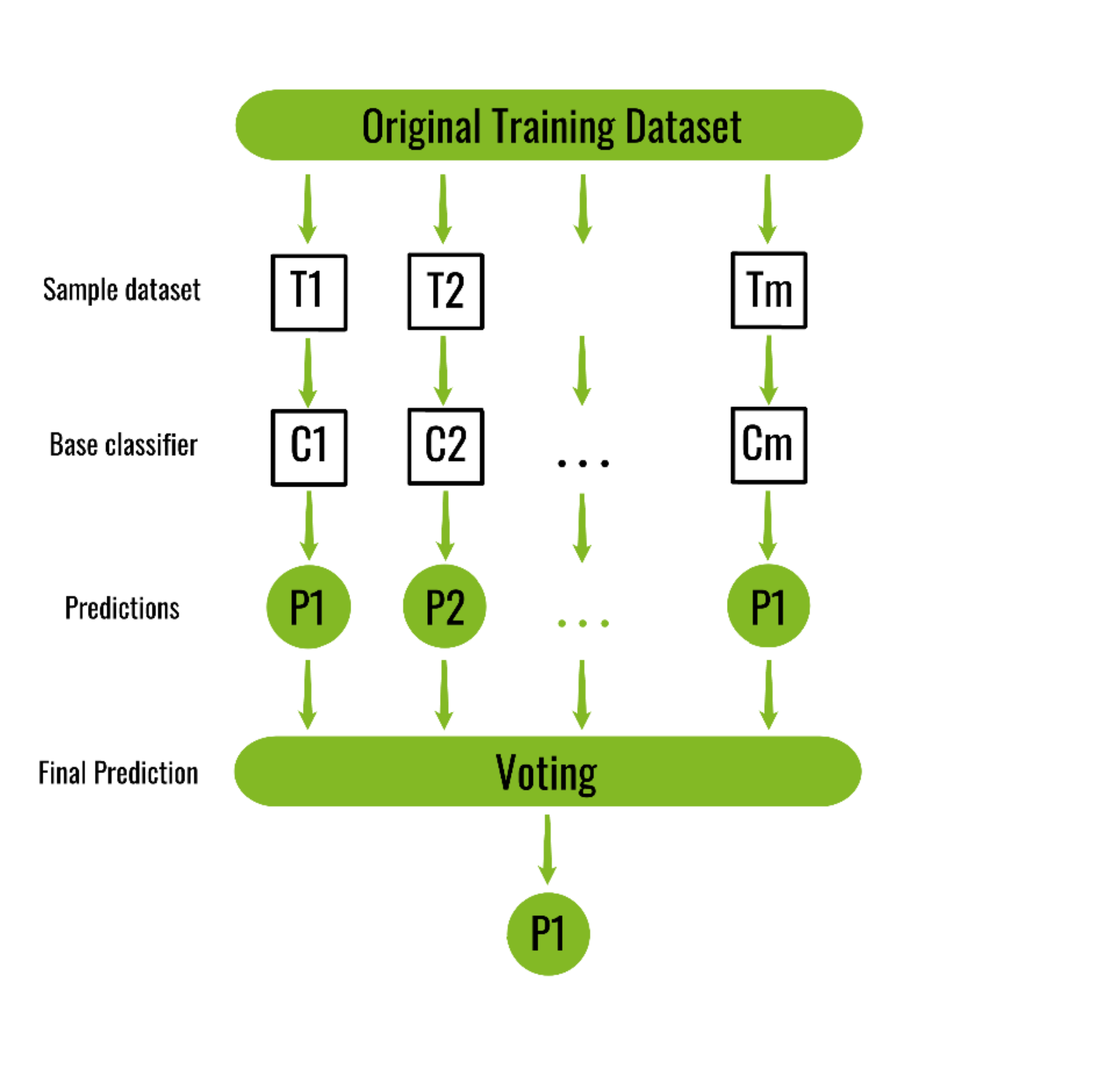
以下是上述算法的Python实现:
from sklearn import model_selection
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
# load the data
url = "/home/debomit/Downloads/wine_data.xlsx"
dataframe = pd.read_excel(url)
arr = dataframe.values
X = arr[:, 1 : 14 ]
Y = arr[:, 0 ]
seed = 8
kfold = model_selection.KFold(n_splits = 3 , random_state = seed)
# initialize the base classifier
base_cls = DecisionTreeClassifier()
# no. of base classifier
num_trees = 500
# bagging classifier
model = BaggingClassifier(base_estimator = base_cls, n_estimators = num_trees, random_state = seed)
results = model_selection.cross_val_score(model, X, Y, cv = kfold)
print ( "accuracy :" )
print (results.mean())输出如下:
accuracy :
0.8372093023255814首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。

