
路由器是必不可少的联网设备, 可通过网络引导数据流。路由器有一个或多个输入和输出接口分别接收和发送数据包。由于路由器的内存有限, 因此路由器可能会用完空间来容纳新到达的数据包。如果数据包的到达速率大于数据包从路由器内存中退出的速率, 则会发生这种情况。在这种情况下, 新的数据包将被忽略or较旧的数据包被丢弃。作为资源分配机制的一部分, 路由器必须实施某种排队规则, 以控制在需要时如何缓冲或丢弃数据包。
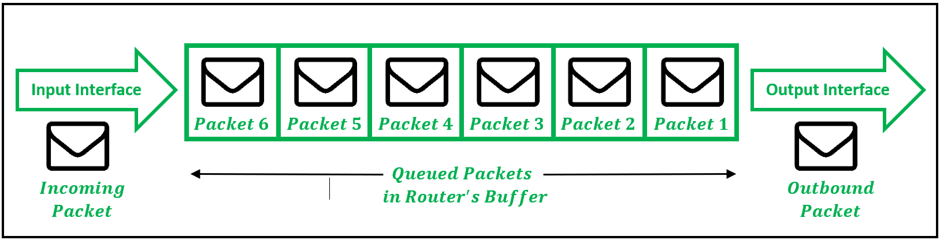
图。1:
路由器的入站和出站流量的描述
队列拥塞和排队纪律
路由器队列由于其可用的有限缓冲存储器而易于拥塞。当入口流量的速率变得大于在输出接口上可以转发的流量时, 就会发现拥塞。造成这种情况的潜在原因主要包括:
- 传入流量的速度超过传出速率
- 来自所有输入接口的总流量超过了总输出容量
- 路由器处理器无法处理转发表的大小来确定路由路径
为了在这种拥塞情况下管理路由器内存向数据包的分配, 路由器可能会遵循不同的规则来确定保留哪些数据包以及丢弃哪些数据包。因此, 我们在路由器中具有以下重要的排队规则:
先进先出队列(FIFO)
大多数路由器遵循的默认排队方案是FIFO。通常, 这几乎不需要在服务器上进行任何配置。 FIFO中的所有数据包都以到达路由器的相同顺序进行服务。内存达到饱和后, 尝试进入路由器的新数据包将被丢弃(尾巴下降)。但是, 这种方案不适用于实时应用, 特别是在拥塞期间。连续发送数据包的实时应用程序(如VoIP)在拥塞时可能会饿死, 并丢弃所有数据包。
优先排队(PQ)
在优先级排队中, 路由器不使用单个队列, 而是根据某种优先级度量将内存分为多个队列。此后, 每个队列以FIFO方式处理, 同时逐个循环浏览队列。队列被标记为高, 中, 要么低根据优先级。高优先级队列的数据包始终在中优先级队列的数据包之前进行处理。同样, 中队列中的数据包总是在普通队列中的数据包之前进行处理, 等等。只要高优先级队列中存在某些数据包, 就不会处理其他队列中的数据包。因此, 高优先级的数据包切到该行的最前面, 并首先得到服务。清空较高优先级的队列后, 只有那时是服务的优先级较低的队列。
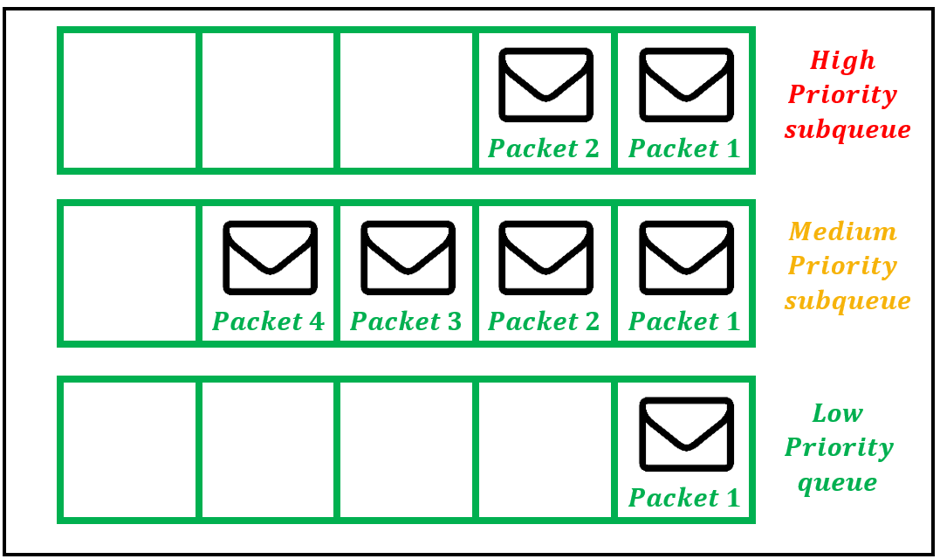
图2:优先级排队方案中使用的多个子队列
PQ的明显优势是高优先级的流量总是先被处理。然而,PQ方案的一个显著缺点是,由于缺乏服务,较低优先级的队列通常无法接收任何服务。高优先级流量的恒定流会使低优先级队列挨饿
加权公平排队(WFQ)
加权公平排队(WFQ)根据流量动态创建队列, 并根据优先级为这些流量分配带宽。子队列被动态分配带宽。假设存在3个队列, 当它们都处于活动状态时, 它们的带宽百分比分别为20%, 30%和50%。然后, 如果20%队列处于空闲状态, 则在保留原始带宽比率的同时, 在其余队列之间分配释放的带宽。因此, 现在分配20%队列(75/2)%, 现在分配50%队列(125/2)%带宽。
交通流量根据数据包中的各种标头字段进行区分和标识, 例如:
- 源IP地址和目的IP地址
- 源和目标TCP(或UDP)端口
- IP协议号
- 服务类型值(IP优先级或DSCP)
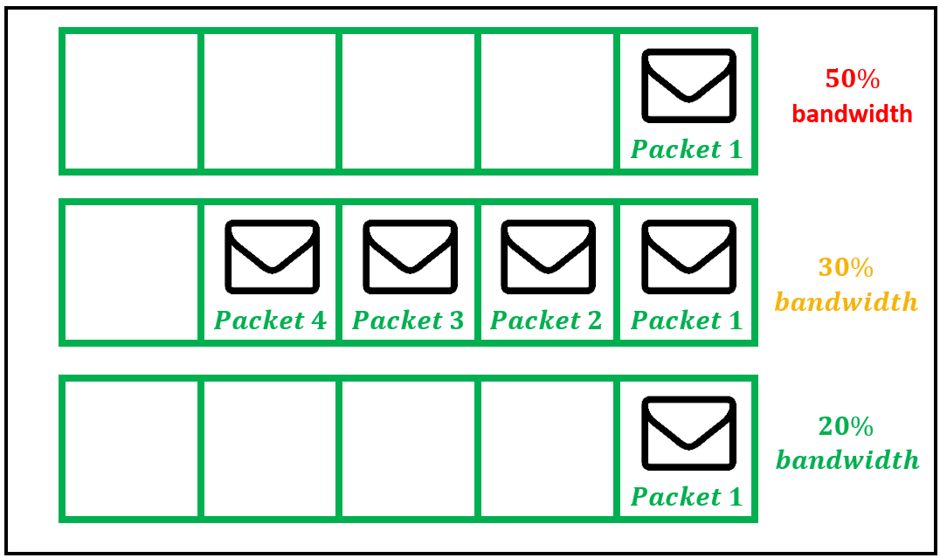
图3:WFQ中为子队列动态分配的带宽
因此, 根据与数据包相对应的流量将数据包分为不同的队列。一旦被识别, 就将属于相同流量的数据包插入专门为此流量创建的队列中。默认情况下, 路由器内最多可以建立256个队列, 但是, 该数目最多可以增加4096个队列。与PQ方案不同, WFQ队列根据其队列优先级分配不同的带宽。优先级较高的数据包会在优先级较低的数据包同时到达之前进行调度。
排队纪律对网络的影响
排队规则的选择就丢包数, 等待时间等方面影响网络性能。在分析选择不同方案的效果时, 我们观察到对各种参数的显着影响。
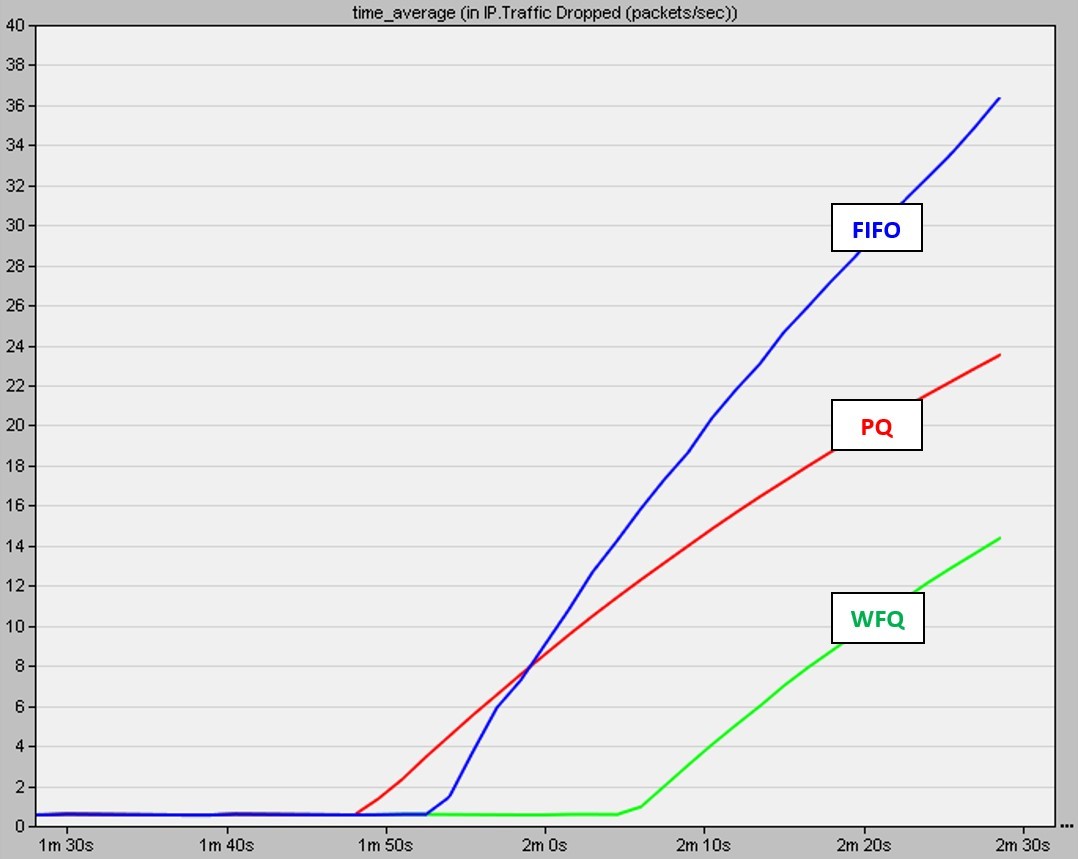
图4:不同排队规则丢弃的数据包数量与时间的关系(在Riverbed Modeler上运行模拟)
测量这三种方案的网络中的总体数据包丢弃量会得出以下结果:
- 在所有机制中, 从开始到特定点都没有丢包。这是因为填满路由器缓冲存储器需要有限的时间。由于数据包丢弃仅在缓冲区已满后发生, 因此有一个初始时间段, 因为尚未达到缓冲区容量, 所以没有丢包.
- 在FIFO方案中, 数据包丢弃在PQ之后但在WFQ之前开始。更重要的是, 在FIFO的情况下, 丢弃的数据包数量最大。这是由于以下事实:一旦拥塞, 所有应用程序的所有传入流量都将被完全丢弃, 不会有任何歧视.
- 在PQ方案中, 数据包丢弃最早开始。由于PQ根据优先级对队列进行划分, 因此将各个队列的总大小进行了划分。假设将内存简单划分为"重要"队列和"不太重要"队列, 队列大小减半。因此, 定向到子队列的数据包将导致队列更早被填充(由于较小的容量), 因此数据包丢弃将更早开始

