

自OpenAI的ChatGPT出来以后,普通人再也不能忽视AI的现实存在了,因为这次的ChatGPT超越了之前的AI产品,并且可被大多数普通人用于日常使用,毫无疑问,人工智能将会在未来占据日常生活的方方面面。下面重点介绍神经网络原理分析,主要考虑到目前比较忙,所以重点讨论的是神经网络的原理,本文没什么代码,但是对于你理解和设计神经网络模型会有很大的帮助。
事情得从启蒙运动说起,启蒙运动有两个:法国启蒙运动与英国苏格兰启蒙运动,启蒙运动其中对人是如何认识世界做了详细讨论,苏格兰启蒙运动是最令人惊讶的,其中的哲学这里不作详细说明。关于讨论人是如何认识世界的讨论——这部分又称为认识论或知识论,所谓知识就是:我知道什么?(What do I know?I know that…),我知道等下就会下雨——当然人是不可能知道等一会就下雨的,因为此时我在写文章,即使我看到天阴沉,并且前几天都下雨,但是等一会的那个时间还没到来我就绝不可能知道;这是一个在事实上人能把握到的绝对证明,这就是为什么科学无法保证绝对正确的原因,并不是那些人说的相信牛鬼蛇神也有道理的。但是人还是很想知道等下会不会下雨怎么办?实际上,上面就给出了答案:“看到天阴沉,并且前几天都在下雨”,等下会下雨的概率就会很大——归纳法,使用以前的经验预测未来——实际上,人就是这样认识世界的,这种认识的过程就是学习。从出生到现在看了N次太阳从东边升起来,所以习惯地认为明天太阳也从东边升起来。
人们把这种经常发生的现象总结起来,就是知识了,用我们自己的理性就可以想到:这样好像不是很准确的样子,但是科学其实就是这样,认识到科学为什么有缺陷才是真的懂得什么是科学。目前也没什么数学方法能够把所有事情都解决的了,即使在神经网络中也是如此,数学只是一种工具,它描述的东西不等于事实。
所谓机器学习,其意思就是让机器自动找出那些经常发生的事情,更广泛的来说,是让机器模拟人脑独有的归纳法和演绎法。机器学习按照学习类型有很多种,例如监督学习、无监督学习、强化学习等,从这里开始,开始进入数学和计算机科学,脱离人的大脑和神经,神经网络和人的神经元或神经网络没什么特别的关系,只是给了一个好听的名称。客观的目标是模拟人脑认知,机器学习是一种方法,更细分的看,深度神经网络也只是为了尝试完成目标的其中一种方法,这就意味着不只有这一种,而且这种方法也是不完美的。
不推荐把神经网络理解成模拟人大脑神经元的说法,它不存在显著的仿生,它和基本的线性回归的方向是一致的,其中的一种学习算法类型,不管如何,我就是要把参数捏成差不多符合实际数据的样子,不然搞数学搞的多漂亮都没用。我认为,实际上计算机神经网络甚至一点仿生真实神经元的都没有,欧拉图论要比所谓仿生神经元还早还经典(基本深度神经网络架构图就是一个Graph)。神经网络的基础还是微分、矩阵、图论,最优化,搞来搞去,都是和最小二乘法差不多的。神经网络挺简单的,但是我们真实的神经元哪有这么简单?
Pytorch如何构建神经网络模型?Pytorch是实现神经网络算法的一个python框架,其它常用的还有tensorflow,之前我首先是考虑tensorflow的,不过后来快速转到pytorch了,因为就目前来说pytorch用的人会多一些。框架的考虑因素一般只有一个,就是哪个用的人更多就用它可以了。目前很多一部分人用pytorch来做研究,不过我是基于程序员开发的背景学机器学习的。实际上,我发现程序员背景的人不一定灵活用的了pytorch或tensorflow,程序员不见得有很好的数学基础,甚至很多高数也不懂,而不熟悉编程的研究人员又可能写代码非常鸡肋,因为这需要一定的数学基础和编程基础,不过编程基础问题不大,使用python就如用mathematica或matlab一样,简单的命令式语句,不过python更符合编程习惯。总之数学基础是一定要有的,这就像一般编程需要学算法,不然做这方面的工作会显得发挥空间很小。看到这里是不是觉得这好像挺难学的,等我学完相关数学那得到什么时候,另外,其实作为程序员还可以直接拿别人训练好的模型来用,只是局限性很大就是了。
神经网络原理分析:基本神经网络架构
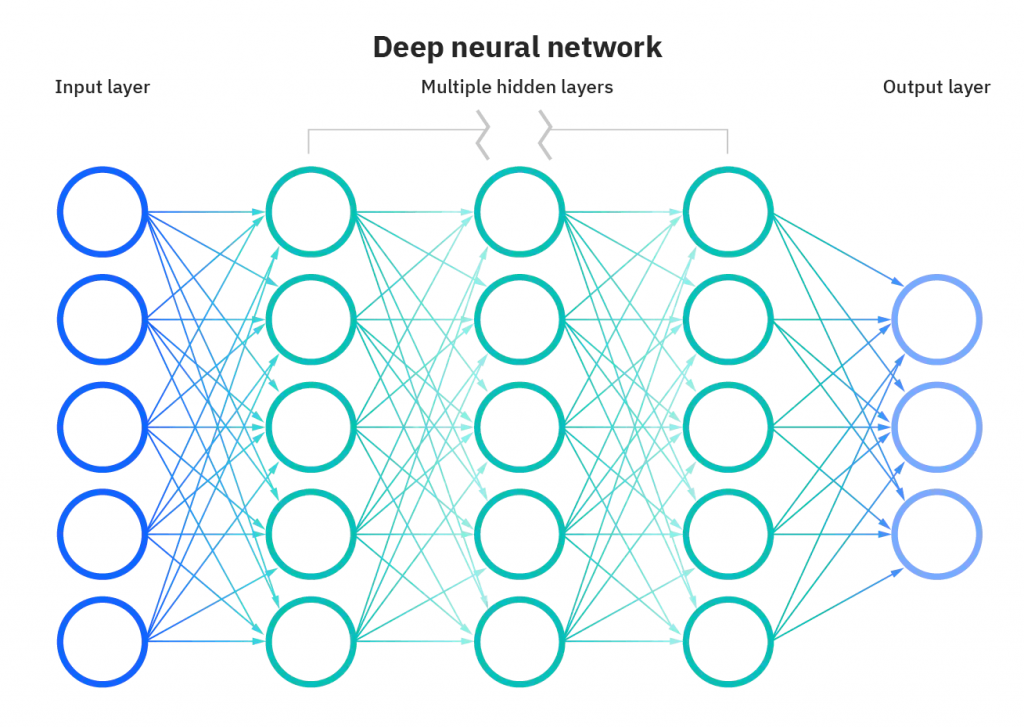
上图就是基本的神经网络形式,这是一个逻辑形式图,但是这个图也没有描述清楚基本的神经网络算法元素,实际的算法不会基于这个图来实现,在详细说神经网络的架构之前,先说一下这个算法的方向和目标。
参考基本的使用最小二乘法实现线性拟合,就是有一组(x1, y1)的数据,找一个y=ax+b来描述这些数据,当然是找不到一条直线刚刚好通过这些不规则的数据点的,我们是需要找到一条差不多在这些点附近的直线L(找一条最优的直线),计算出这样的a和b,这样的L就可以用来描述这些数据并且进行预测。具体来说,就是使得所有数据点的((a * x1 + b) - y1)最小,其中(a * x1 + b)是预测值,y1是真实值,这种描述真实值和预测值偏差的函数又称为代价函数或损失函数。而我们机器学习训练得到的就是类似a、b这样的参数,参数和预测使用的方法统称一个预测模型,模型可以保存到本地二次分发使用,只需要往模型传入一个样本数据就可以获取到预测值了。
Pytorch如何构建神经网络模型?而我们的神经网络不管多么复杂,其实目的也就是获取这样的参数,获取的过程也就是学习,其实这和真实的学习行为差别太大了,具体来说,就是求损失函数的最小值的过程,数学里求微分或偏导数就可以得到了,那为什么不直接使用偏导数求极小值就行了?直接求导在计算机资源和数学上都有问题,总之一般都是使用梯度下降算法,是直接求偏导的一种替代的算术方法,任意取一点x0,求这点的导数f`(x0),寻找最小的f(x0-λf`(x0)),导数表示函数的变化率,导数的符号表示上升下降的方向,(x0-λf`(x0))表示沿着下降方向前进,λ用于限制前进的步长,又称为学习率(又是一个很跳跃的名称)。
所以,基本神经网络算法用数学描述就很简单,使用梯度下降算法计算损失函数的最小值,在其它情况也是如此,很多时候都是围绕损失函数进行的,而伴随着的梯度下降算法就是计算极小值的方法。pytorch创建计算图是很灵活的,也就是动态计算图(图的图),这也要求我们自己要抓住学习算法的核心和方向。
现在来看一下上面的神经网络基本架构图,首先是输入层,对应上图最左边蓝色的所有节点。图中的所有圆圈在图论中称为节点(Node),又称为神经元(这名称意义不大),边(Edge)为有方向的边,也就是有向图。对于输入层的节点,这些节点保存着输入一个样本x的所有单个特征值;对于边,边表示起始节点对下一个节点的数值贡献程度,使用权重w描述。
中间绿色的节点表示中间层、隐藏层或计算层,最后浅蓝色的节点表示输出层。对于中间层的节点,节点除了保存计算结果,还负责计算操作,包括线性变换(包含偏置b)和非线性变换。
输出层保存最终的计算结果,一般而言有两种情况:分类和回归任务,对于分类任务,输出层的每个节点表示一个类别,一般需要使用多个节点(二元分类一个就行),前面一般带有一个softmax分类器,计算每个输入到达输出分类对应的概率;对于回归任务,使用一个节点就行,因为回归的结果一般是一个连续值。在训练过程中,这里的计算结果将会和正确值进行比较以构建一个损失函数。在预测过程中,这里得到的就是预测结果了。
神经网络原理分析:前向传播(Forward Propagation)
我认为很多人解释这部分是非常有问题的,越说越复杂。我们可以把整个神经网络模型当做一个黑盒子,也就是f(x),x作为输入数据,学习无非就是求出f(x)的最优参数。还记得上面说的最小二乘法吗?它的形式就是使用已存在的数据计算出参数,也就是把当前数据代入到预设的函数中,然后构建一个损失函数。而神经网络的前向传播就等同于最小二乘法中“把已有数据代入到预设函数中”的步骤。例如对于y=ax+b,也就是代入点(x1, y1)得到(w * x1 + b),这个表示预测值,后面你会看到Pytorch中使用pred = model(x)获取预测值,然后把pred和y传入到损失函数中开始计算参数最优解,也就是这个形式。其中w、b这样的参数一开始是随机生成的,每经过一层网络执行一种计算。
前向传播的目的是为了生成神经网络的计算图,这个图才是真实存在的神经网络图,这个计算图的节点表示一种操作或函数Function,它对应pytorch中的一个Function对象,叶子节点是输入节点,输出节点是根节点,计算图的边表示数据流向。
那为什么要生成计算图?其实就是为了构造一个预测值,用于构建一个损失函数。
pytorch的基本数据类型是Tensor,而我们使用Tensor就可以构建一个计算图了,给tensor设置requires_grad=True,当我们使用tensor进行运算的时候,pytorch就会为我们自动创建计算图,那些指定为requires_grad=True的Tensor将可以视为参数或变量,反向传播对其进行求偏导的对象。有一个误区是,w和b不是随机生成的吗?也就是前向传播的时候是有具体值的,是的,但是后向传播就会当成参数变量了,就requires_grad=True的作用,你可以使用w1.grad获取当前w1的偏导值,表示w1的变化率,可以使用w1.grad_fn获取操作函数。
反向传播(Backward Propagation)
上面说到,前向传播的目的就是为了代入参数获取预测值,而后向传播包含两部分:求参数的偏导数、使用梯度下降算法调整参数。
执行前向传播我们可以得到预测值pred,而当前数据集中正确的值为y,接着我们使用一个损失函数loss(pred, y),对这个函数loss(pred, y)进行链式求导,得到每个参数的偏导数,最后使用梯度下降算法进行调整参数。而pytorch中的实现也是符合这个过程,其中损失函数有很多种,这里不详细讨论。Tensor.backward()方法就是用于求参数的偏导数,当计算到w1的偏导数,我们就可以结合学习率λ移动来调整参数了。这里不会详细介绍每种算法的执行原理,不过大致就是这样,损失函数有很多种,而梯度下降算法也有很多种。
Pytorch如何构建神经网络模型?神经网络架构设计
有人说神经网络训练模型关键或全部工作在特征工程上,我认为这个程度要减一半,数据特征工程当然非常重要,但是我们不可能依靠一个简单的hello world网络和大量的数据就完成一个面向一般用户的产品,一个常见的图片标签训练还不足以完成一个现代的智能系统,这还远远比不上一个简单的博客网站。
因为识别图片其实非常简单,倒不是说使用的技术或算法简单,而是针对一般用户这样的功能未免太简单无用了,而ChatGPT这样的产品才是真的功能完整可用的,起码从GPT3模型开始。当然,如果仅仅是用于研究统计或是写下论文则不一样,而面向一般用户的AI产品才是主要的方向。
基于以上原因,设计一个神经网络模型,需要有针对性的对计算图进行设计,这个在技术上是一个难点。这里简单说下一般常用的计算层,本来还想完整针对一些经典模型使用pytorch进行实现的,应该没时间了,需要赶工作了。
pytorch的计算层相关api在torch.nn中,以下是一些pytorch常用的计算层:
- 全连接层:如nn.Linear,最常用的计算层,提供线性转换,形如y=wx+b的线性函数;
- 非线性层或激活函数层:如nn.ReLU,这其实不算一个层,因为像ReLU这样的激活函数的非线性输入输出不涉及需要优化的参数,不过基本上这是每一层网络必备的函数,又称为激活函数;
- 其它非线性函数:如nn.Softmax,这种函数一般用于连接输出层,用于计算目标结果;
- 卷积层:如nn.Conv2d,用于结构化提取样本特征,要注意的是,卷积并非只是针对图像的,基本上任何类型的数据都可以使用;
- 池化层:如nn.MaxPool2d,用于压缩特征,一般跟在卷积层后面,顺便说下,计算图是一个有向无环图,一个计算层到下一个计算层节点是有顺序有方向的,就是先如何处理数据,然后再怎么处理数据;
- 归一化层:如nn.BatchNorm1d,用于统一特征尺度,避免特征权重过大;
- Dropout层:如nn.Dropout,用于在计算过程中随机地去除一些神经元节点,避免过拟合或计算量过大;
- 循环神经网络层:如nn.LSTM,相比于上面的计算层这个是一种复合的计算层,用于处理序列数据。

