
在单变量数据分析的情况下, 均值, 中位数, 标准差和方差之类的估计非常有用。但是在双变量分析(比较两个变量)的情况下, 相关性发挥了作用。
列联表是探索两个或更多变量的技术之一。基本上, 它是两个或多个分类变量之间的计数计数。
要获取贷款数据, 请点击这里:https://drive.google.com/open?id=1vZj8S87WtMQkHiRi4a_fA6auzfvqSjt1
加载库
import numpy as np
import pandas as pd
import matplotlib as plt加载数据中
data = pd.read_csv( "loan_status.csv" )
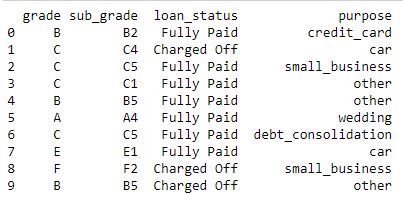
print (data.head( 10 ))输出如下:
描述数据
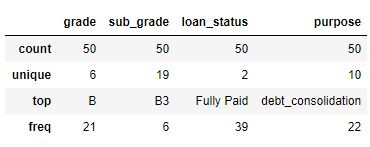
data.describe()输出如下:
数据info
data.info()输出如下:

数据类型
# data types of feature/attributes
# in the data
data.dtypes输出如下:
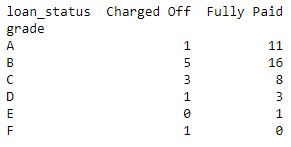
代码1:列联表, 显示等级和贷款状态之间的相关性。
data_crosstab = pd.crosstab(data[ 'grade' ], data[ 'loan_status' ], margins = False )
print (data_crosstab)输出如下:
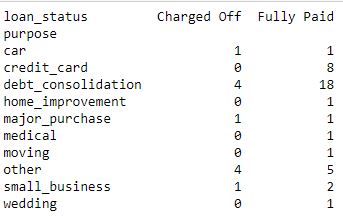
代码2:列联表, 显示目的和贷款状态之间的相关性。
data_crosstab = pd.crosstab(data[ 'purpose' ], data[ 'loan_status' ], margins = False )
print (data_crosstab)输出如下:
代码3:列联表, 显示等级+目的与贷款状态之间的相关性。
data_crosstab = pd.crosstab([data.grade, data.purpose], data.loan_status, margins = False )
print (data_crosstab)输出如下:
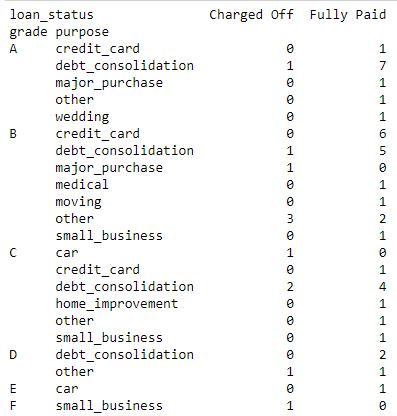
因此, 正如代码中那样, 列联表在两个或更多变量之间给出了明确的相关性值。因此, 了解数据以进行进一步的信息提取将变得更加有用。
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。
![从字法上最小长度N的排列,使得对于正好为K个索引,a[i] a[i]+1](https://www.lsbin.com/wp-content/themes/begin%20lts/img/loading.png)
