
给定一个输入文本和一个包含k个单词的数组arr[],查找输入文本中出现的所有单词。设n为文本长度,m为所有单词中字符总数,即m = length(arr[0]) + length(arr[1]) +…+ length(arr[k-1])。这里k是输入单词的总数。
例子:
Input: text = "ahishers"
arr[] = {"he", "she", "hers", "his"}
Output:
Word his appears from 1 to 3
Word he appears from 4 to 5
Word she appears from 3 to 5
Word hers appears from 4 to 7如果我们使用像KMP这样的线性时间搜索算法,那么我们需要逐个搜索text[]中的所有单词。这使我们的总时间复杂度为O(n + length(word[0]) + O(n + length(word[1]) + O(n + length(word[2]) +…O(n + length(word[k-1]))。这个时间复杂度可以写成O(n*k + m)。
Aho-Corasick算法在O(n + m + z)时间内查找所有单词,其中z是单词在文本中出现的总次数。Aho-Corasick字符串匹配算法构成了原始Unix命令fgrep的基础。
- 处理前:建立一个由arr []中所有单词组成的自动机自动机主要具有三个功能:
Go To : This function simply follows edges
of Trie of all words in arr[]. It is
represented as 2D array g[][] where
we store next state for current state
and character.
Failure : This function stores all edges that are
followed when current character doesn't
have edge in Trie. It is represented as
1D array f[] where we store next state for
current state.
Output : Stores indexes of all words that end at
current state. It is represented as 1D
array o[] where we store indexes
of all matching words as a bitmap for
current state.- 匹配:在内置的自动机上遍历给定的文本以找到所有匹配的单词。
预处理:
- 我们首先建立一个特里(或关键字树)中的所有单词。
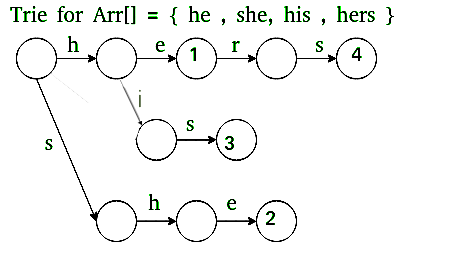
Trie
- 这部分填充goto g [] []中的条目并输出o []。
- 接下来, 我们将Trie扩展为自动机以支持线性时间匹配。
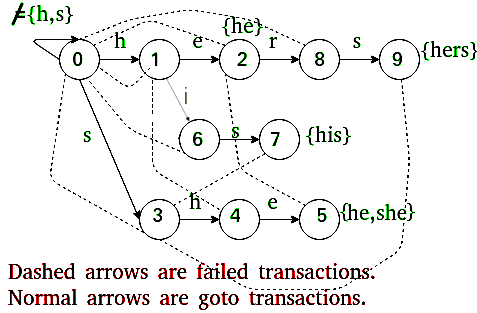
- 这部分填写失败f[]和输出o[]中的条目。
我们建立单词查找树。对于所有没有根边的字符,我们把根边加回去。
失败:
对于状态s, 我们找到最长的适当后缀, 该后缀是某些模式的适当前缀。这是使用Trie的广度优先遍历完成的。
输出:
对于状态s, 存储所有以s结尾的单词的索引。这些索引存储为按位映射(通过对值进行按位或)。这也使用具有故障的广度优先遍历进行计算。
以下是Aho-Corasick算法的C ++实现
C
// C++ program for implementation of Aho Corasick algorithm
// for string matching
using namespace std;
#include <bits/stdc++.h>
// Max number of states in the matching machine.
// Should be equal to the sum of the length of all keywords.
const int MAXS = 500;
// Maximum number of characters in input alphabet
const int MAXC = 26;
// OUTPUT FUNCTION IS IMPLEMENTED USING out[]
// Bit i in this mask is one if the word with index i
// appears when the machine enters this state.
int out[MAXS];
// FAILURE FUNCTION IS IMPLEMENTED USING f[]
int f[MAXS];
// GOTO FUNCTION (OR TRIE) IS IMPLEMENTED USING g[][]
int g[MAXS][MAXC];
// Builds the string matching machine.
// arr - array of words. The index of each keyword is important:
// "out[state] & (1 << i)" is > 0 if we just found word[i]
// in the text.
// Returns the number of states that the built machine has.
// States are numbered 0 up to the return value - 1, inclusive.
int buildMatchingMachine(string arr[], int k)
{
// Initialize all values in output function as 0.
memset (out, 0, sizeof out);
// Initialize all values in goto function as -1.
memset (g, -1, sizeof g);
// Initially, we just have the 0 state
int states = 1;
// Construct values for goto function, i.e., fill g[][]
// This is same as building a Trie for arr[]
for ( int i = 0; i < k; ++i)
{
const string &word = arr[i];
int currentState = 0;
// Insert all characters of current word in arr[]
for ( int j = 0; j < word.size(); ++j)
{
int ch = word[j] - 'a' ;
// Allocate a new node (create a new state) if a
// node for ch doesn't exist.
if (g[currentState][ch] == -1)
g[currentState][ch] = states++;
currentState = g[currentState][ch];
}
// Add current word in output function
out[currentState] |= (1 << i);
}
// For all characters which don't have an edge from
// root (or state 0) in Trie, add a goto edge to state
// 0 itself
for ( int ch = 0; ch < MAXC; ++ch)
if (g[0][ch] == -1)
g[0][ch] = 0;
// Now, let's build the failure function
// Initialize values in fail function
memset (f, -1, sizeof f);
// Failure function is computed in breadth first order
// using a queue
queue< int > q;
// Iterate over every possible input
for ( int ch = 0; ch < MAXC; ++ch)
{
// All nodes of depth 1 have failure function value
// as 0. For example, in above diagram we move to 0
// from states 1 and 3.
if (g[0][ch] != 0)
{
f[g[0][ch]] = 0;
q.push(g[0][ch]);
}
}
// Now queue has states 1 and 3
while (q.size())
{
// Remove the front state from queue
int state = q.front();
q.pop();
// For the removed state, find failure function for
// all those characters for which goto function is
// not defined.
for ( int ch = 0; ch <= MAXC; ++ch)
{
// If goto function is defined for character 'ch'
// and 'state'
if (g[state][ch] != -1)
{
// Find failure state of removed state
int failure = f[state];
// Find the deepest node labeled by proper
// suffix of string from root to current
// state.
while (g[failure][ch] == -1)
failure = f[failure];
failure = g[failure][ch];
f[g[state][ch]] = failure;
// Merge output values
out[g[state][ch]] |= out[failure];
// Insert the next level node (of Trie) in Queue
q.push(g[state][ch]);
}
}
}
return states;
}
// Returns the next state the machine will transition to using goto
// and failure functions.
// currentState - The current state of the machine. Must be between
// 0 and the number of states - 1, inclusive.
// nextInput - The next character that enters into the machine.
int findNextState( int currentState, char nextInput)
{
int answer = currentState;
int ch = nextInput - 'a' ;
// If goto is not defined, use failure function
while (g[answer][ch] == -1)
answer = f[answer];
return g[answer][ch];
}
// This function finds all occurrences of all array words
// in text.
void searchWords(string arr[], int k, string text)
{
// Preprocess patterns.
// Build machine with goto, failure and output functions
buildMatchingMachine(arr, k);
// Initialize current state
int currentState = 0;
// Traverse the text through the nuilt machine to find
// all occurrences of words in arr[]
for ( int i = 0; i < text.size(); ++i)
{
currentState = findNextState(currentState, text[i]);
// If match not found, move to next state
if (out[currentState] == 0)
continue ;
// Match found, print all matching words of arr[]
// using output function.
for ( int j = 0; j < k; ++j)
{
if (out[currentState] & (1 << j))
{
cout << "Word " << arr[j] << " appears from "
<< i - arr[j].size() + 1 << " to " << i << endl;
}
}
}
}
// Driver program to test above
int main()
{
string arr[] = { "he" , "she" , "hers" , "his" };
string text = "ahishers" ;
int k = sizeof (arr)/ sizeof (arr[0]);
searchWords(arr, k, text);
return 0;
}输出如下:
Word his appears from 1 to 3
Word he appears from 4 to 5
Word she appears from 3 to 5
Word hers appears from 4 to 7资源:
http://www.cs.uku.fi/~kilpelai/BSA05/lectures/slides04.pdf
如果发现任何不正确的地方, 或者想分享有关上述主题的更多信息, 请发表评论。
![从字法上最小长度N的排列,使得对于正好为K个索引,a[i] a[i]+1](https://www.lsbin.com/wp-content/themes/begin%20lts/img/loading.png)
