随机森林法是一个监督学习算法。它构建了称为森林的多个决策树, 并将它们粘合在一起以促成更准确和稳定的预测。随机森林方法类似于称为Bagging的集成技术。在这种方法中, 通过从训练数据中引导样本生成多个树, 然后我们简单地减少树之间的相关性。执行此方法可提高决策树的性能, 并有助于避免覆盖。在本文中, 我们将学习使用随机森林方法进行回归R编程.
随机森林的特征
- 聚集许多决策树:随机森林是决策树的集合, 因此不依赖于单个功能, 而是将来自每个决策树的多个预测组合在一起。
- 防止过度拟合:在有多个决策树的情况下, 每棵树都抽取一个样本随机数据, 从而使随机森林具有比决策树更好的准确性。
随机森林的优势
- 高效:在大型数据库上执行时, 随机森林比决策树更有效率。
- 高度准确:随机森林具有很高的准确性, 因为它们是决策树的集合, 并且每个决策树都抽取样本随机数据, 结果, 随机森林在预测方面产生了更高的准确性。
- 有效的测试错误估计:即使数据丢失, 它也可以有效利用所有预测功能并保持准确性。
随机森林的缺点
- 需要不同级别的数量:作为决策树的集合, 随机森林需要不同数量的级别才能对训练模型进行更加准确和有偏见的预测。
- 需要大量内存:训练大量树可能需要更高的内存或并行内存。
R中回归的随机森林方法的实现
包装randomForest在R语言中, 编程用于创建随机森林。它构建的森林是决策树的集合。功能randomForest()用于创建和分析随机森林。
语法:
randomForest(公式, 数据)
参数:
公式:表示描述要拟合的模型的公式
数据:表示包含模型中变量的数据框
要了解更多可选参数, 请使用命令help(" randomForest")
例子:
第1步:安装所需的软件包。
# Install the required package for function
install.packages ( "randomForest" )第2步:加载所需的程序包。
# Load the library
library (randomForest)第三步:在这个例子中,让我们使用R中显示的空气质量数据集。
# Print the dataset
print ( head (airquality))输出如下:
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6步骤4:创建随机森林进行回归
# Create random forest for regression
ozone.rf <- randomForest (Ozone ~ ., data = airquality, mtry = 3, importance = TRUE , na.action = na.omit)步骤5:打印回归模型
# Print regression model
print (ozone.rf)输出如下:
Call:
randomForest(formula = Ozone ~ ., data = airquality, mtry = 3, importance = TRUE, na.action = na.omit)
Type of random forest: regression
Number of trees: 500
No. of variables tried at each split: 3
Mean of squared residuals: 296.4822
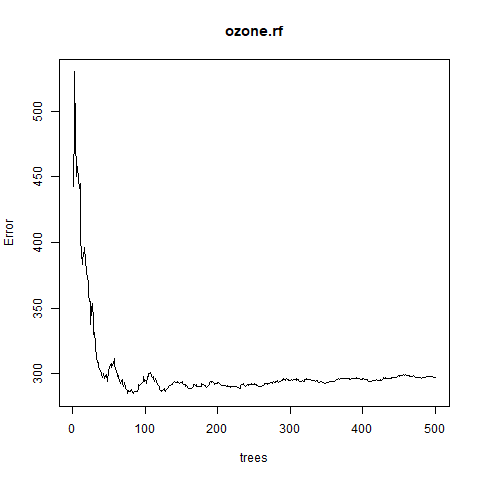
% Var explained: 72.98步骤6:在误差与树数之间绘制图
# Output to be present as PNG file
png (file = "randomForestRegression.png" )
# Plot the error vs the number of trees graph
plot (ozone.rf)
# Saving the file
dev.off ()输出如下: