
一种数据仓库是在统一模式下组织的不同数据源的异构集合。有两种构建数据仓库的方法:下面解释自顶向下方法和自底向上方法。
1.自上而下的方法:
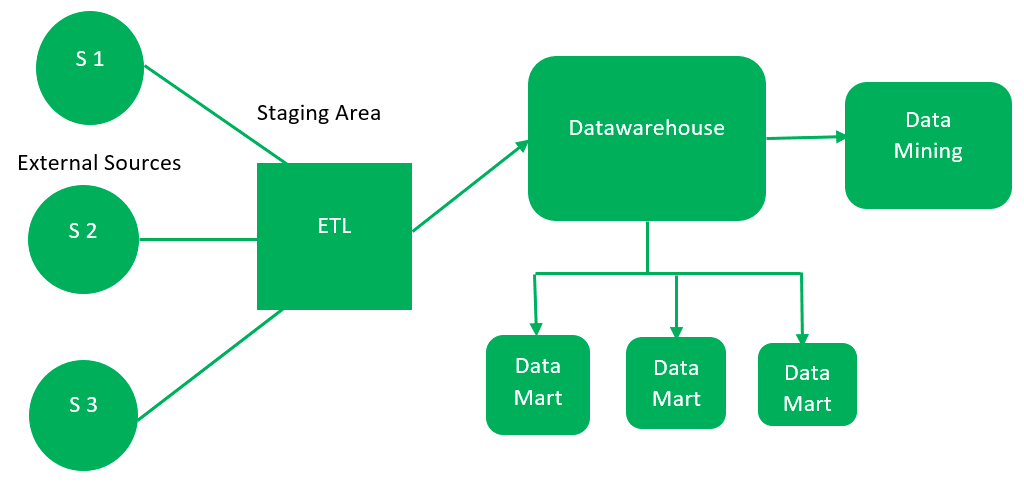
基本组件讨论如下:
外部资源–
外部源是指无论数据类型如何都从中收集数据的源。数据也可以是结构化, 半结构化和非结构化的。
舞台区–
由于从外部源提取的数据没有遵循特定的格式, 因此需要验证此数据以加载到数据仓库中。为此, 建议使用ETL工具
- E(提取):数据是从外部数据源中提取的。
- T(转换):数据被转换为标准格式。
- L(负荷)将数据转换为标准格式后, 将其加载到数据仓库中。
数据仓库 -
清除数据后, 将其作为中央存储库存储在数据仓库中。它实际上存储元数据, 而实际数据存储在数据集市中。
注意
该数据仓库采用这种自顶向下的方法以最纯粹的形式存储数据。
数据集市–
数据集市也是存储组件的一部分。它存储由单个权限处理的组织特定功能的信息。一个组织中的功能取决于其数据集市的数量。我们也可以说数据集市包含存储在数据仓库中的数据的子集。
数据挖掘 -
分析数据仓库中存在的大数据的实践是数据挖掘。它用于借助数据挖掘算法查找数据库或数据仓库中存在的隐藏模式。
此方法定义为因门as –数据仓库作为完整组织的中央存储库, 并在创建完整数据仓库之后从中创建数据集市。
自上而下方法的优势–
- 由于数据集市是从数据仓库创建的, 因此提供了数据集市的一致尺寸视图。
- 此外, 此模型被认为是业务变更的最强模型。因此, 大型组织更喜欢采用这种方法。
- 从数据仓库创建数据集市很容易。
自上而下方法的缺点–
- 设计的成本, 时间及其维护成本很高。
2.自下而上的方法:
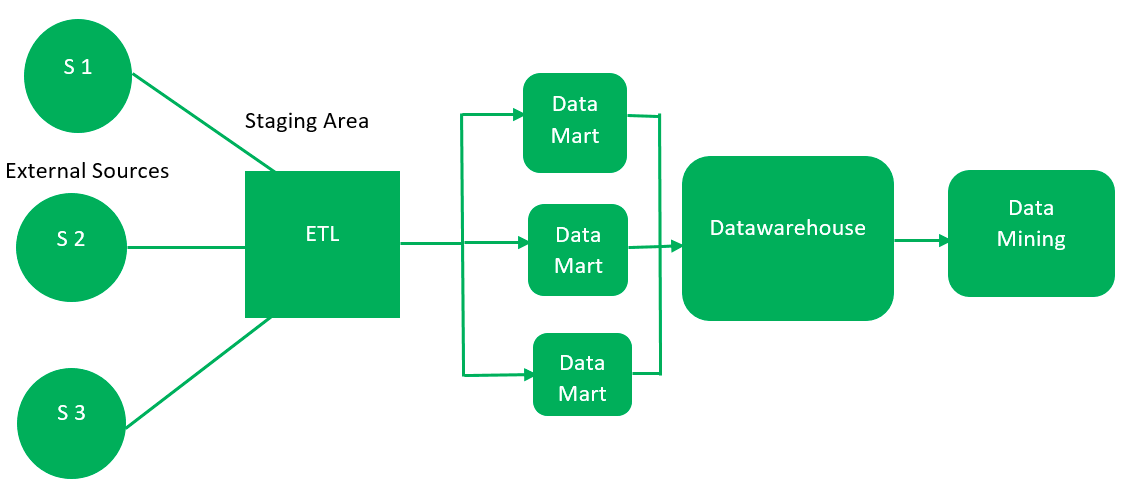
- 首先, 从外部来源提取数据(与自顶向下方法相同)。
- 然后, 数据通过暂存区域(如上所述)并装入数据集市而不是数据仓库。首先创建数据集市并提供报告功能。它涉及单个业务领域。
- 然后将这些数据集市集成到数据仓库中。
该方法由金球as –首先创建数据集市, 并在创建完整的数据集市后为分析和数据仓库创建一个精简视图。
自下而上方法的优势–
- 由于首先创建了数据集市, 因此可以快速生成报告。
- 我们可以在此处容纳更多数量的数据集市, 这样就可以扩展数据仓库。
- 而且, 设计该模型所需的成本和时间相对较低。
自下而上方法的缺点–
- 这种模型不像自上而下的方法那样强大, 因为数据集市的维度视图与上述方法不一致。

