
给定一个字符串,找出最长的子字符串是回文。
我们已经讨论了集合1、集合2和Manacher算法中的Naïve [O(n3)]、二次[O(n2)]和线性[O(n)]方法。
在本文中, 我们将讨论另一种基于后缀树的线性时间方法。
如果给定的字符串为S, 则方法如下:
- 反转字符串S(例如, 反转的字符串为R)
- 得到最长的公共子串S和R假设S和R中的LCS必须位于S中的相同位置
你能明白为什么我们这么说吗R和S中的LCS必须位于S中的相同位置?
我们来看以下示例:
- 对于S = Xababayz和R = zyababax, LCS和LPS都是ababa(相同)
- 对于S = abacdfgdcaba和R = abacdgfdcaba, LCS是abacd,LPS是aba(不同)
- 对于S = pqrqpabcdfgdcba和R =abcdgfdcbapqrqp, LCS和LPS都是pqrqp(相同)
- 对于S = pqqpabcdfghfdcba和R =abcdfhgfdcbapqqp, LCS是abcdf,LPS是pqqp(不同)
我们可以看到LCS和LPS并不总是相同的。当它们不同时?
如果S中具有一个非回文子串的反向副本, 且其长度与S中的LPS相同或更长, 则LCS和LPS将不同
在上面的第二个例子(S = abacdfgdcaba)中,子串abacd在S中存在一个反向复制dcaba,它的长度比LPS aba长,所以这里LPS和LCS是不同的。第4个示例中的场景也是如此。
为了处理这种情况,我们说S中的LPS与S中的LCS和R中的LCS相同,前提是R和S中的LCS必须来自S中的相同位置。
如果我们再看第二个例子,R中的子字符串aba和S中的子字符串aba来自相同的位置,也就是0(第0个索引)这就是LPS。
位置约束:

我们将字符串S索引称为正向索引(Si),字符串R索引称为反向索引(Ri)。
根据上图, 长度为N的字符串S中具有索引i(正向索引)的字符将在其反向字符串R中位于索引N-1-i(反向索引)。
如果我们在字符串S中采用长度为L的子字符串, 以开始索引i和结束索引j(j = i + L-1), 则在它的反向字符串R中, 相同的反向子字符串将从索引N-1-开始j并将在索引N-1-i处结束。
如果在S和R的索引Si(正向索引)和Ri(反向索引)处有一个长度为L的公共子串,那么如果Ri = (N - 1) - (Si + L - 1),其中N为字符串长度,那么这两个子串将来自S的相同位置。
因此要找到字符串S的LPS, 我们找到S和R的最长公共字符串, 其中两个子字符串均满足上述约束, 即如果S中的子串在索引Si处, 然后相同的子串应该在R的索引(N - 1) - (Si + L - 1)。如果不是这种情况, 则此子字符串不是LPS候选对象。
本文讨论了寻找两个字符串的LCS的朴素[O(N*M2)]和动态规划[O(N*M)]方法,这些方法可以扩展为添加位置约束来给出给定字符串的lp。
现在我们将讨论后缀树方法, 它只是对后缀树LCS方法我们将在其中添加位置约束。
在找到两个字符串X和Y的LCS时, 我们只取标记为XY的最深节点(即, 这两个节点的子节点都带有后缀的节点)。
在查找字符串S的LPS时, 我们将再次找到S和R的LCS, 条件是公共子字符串应满足位置约束(公共子字符串应来自S中的相同位置)。为了验证位置约束, 我们需要知道每个内部节点上的所有正向和反向索引(即内部节点下所有叶子子代的后缀索引)。
在s# R$的广义后缀树中,路径上的子串从根到内部节点是一种常见的子串,如果内部节点后缀字符串S和R .常见的子字符串的索引和R可以通过观察找到后缀索引在各自的叶节点。
如果字符串s#的长度是N,那么:
- 如果叶子的后缀索引小于N, 则该后缀属于S, 并且相同的后缀索引将成为所有祖先节点的前向索引
- 如果叶子的后缀索引大于N, 则该后缀属于R, 所有祖先节点的反向索引将为N–后缀索引
我们取字符串S = cabbaabb。下图是cabbaabb#bbaabbac$的通用后缀树,其中我们显示了所有内部节点上所有子后缀的正向和反向索引(根节点除外)。
正向索引在括号()中, 反向索引在方括号[]中。
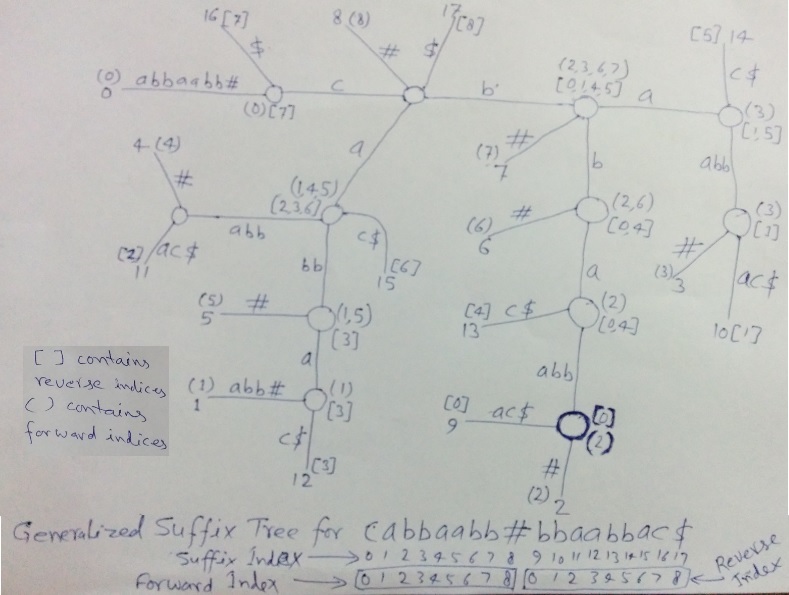
在上图中, 所有叶节点将具有一个正向或反向索引, 具体取决于它们属于哪个字符串(S或R)。然后, 孩子的前进或后退索引会传播给父母。
查看该图以了解具有给定后缀索引的叶子上的正向或反向索引。在图的底部, 显示后缀索引为0到8的叶子将获得与它们在S中的前向索引相同的值(0到8), 后缀索引为9到17的叶子将在R中从0到反向索引得到反向索引。 8。
例如, 突出显示的内部节点有两个后缀索引为2和9的子节点。后缀索引为2的叶子来自S中的位置2, 因此其前向索引为2, 并在()中显示。后缀索引为9的叶子从R中的位置0开始, 因此其反向索引为0, 并显示在[]中。这些索引传播到父级, 并且父级具有一个后缀索引为14的叶子, 其反向索引为4。因此, 在此父节点上, 正向索引为(2), 反向索引为[0, 4]。同样, 我们应该能够理解如何在所有节点上计算正向和反向索引。
在上图中, 所有内部节点都具有来自字符串S和R的后缀, 即它们都代表从根到自身的路径上的公共子字符串。现在我们需要找到满足位置约束的最深节点。为此, 我们需要检查是否存在前向索引Si在一个节点上, 那么必须有一个反向索引Ri值(N – 2)–(Si+ L – 1)其中N是字符串的长度S#L是节点深度(或子串长度)。如果是, 则将该节点视为LPS候选者, 否则将其忽略。在上图中, 突出显示了最深节点, 它表示LPS为bbaabb。
我们没有在图中显示根节点上的正向和反向索引。由于根节点本身不代表任何公共子字符串(在代码实现中, 也不会在根节点上计算正向和反向索引)
如何实施这种方法来查找LPS?这是我们需要的东西:
- 我们需要知道每个节点上的正向和反向索引。
- 对于给定的前向索引Si在内部节点上, 我们需要知道反向索引[Ri=(N – 2)–(Si+ L – 1)也存在于同一节点上。
- 跟踪满足上述条件的最深内部节点。
上述方法之一是:
在后缀树上使用DFS时, 我们可以以某种方式在每个节点上存储正向和反向索引(当我们需要知道节点上的正向和反向索引时, 存储将有助于避免在树上重复遍历)。稍后, 我们可以执行另一个DFS查找满足位置约束的节点。对于位置约束检查, 我们需要在索引列表中进行搜索。
什么数据结构适合于以最快的方式完成所有这些工作?
- 如果我们将索引存储在数组中, 则将需要线性搜索, 这将使整体方法在时间上呈非线性。
- 如果我们将索引存储在树中(在C ++中设置, 在Java中使用TreeSet设置), 则可以使用二进制搜索, 但是总体方法在时间上仍然是非线性的。
- 如果我们将索引存储在基于哈希函数的集合中(在C ++中为unordered_set, 在Java中为HashSet), 则它将平均提供恒定的搜索, 这将使整体方法在时间上线性。基于哈希函数的集合可能会占用更多空间, 具体取决于要存储的值。
在实现中, 我们将使用两个unordered_set(一个用于前向索引, 另一个用于反向索引), 并作为成员变量添加到SuffixTreeNode结构中。
// A C++ program to implement Ukkonen's Suffix Tree Construction
// Here we build generalized suffix tree for given string S
// and it's reverse R, then we find
// longest palindromic substring of given string S
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <iostream>
#include <unordered_set>
#define MAX_CHAR 256
using namespace std;
struct SuffixTreeNode {
struct SuffixTreeNode *children[MAX_CHAR];
//pointer to other node via suffix link
struct SuffixTreeNode *suffixLink;
/*(start, end) interval specifies the edge, by which the
node is connected to its parent node. Each edge will
connect two nodes, one parent and one child, and
(start, end) interval of a given edge will be stored
in the child node. Lets say there are two nods A and B
connected by an edge with indices (5, 8) then this
indices (5, 8) will be stored in node B. */
int start;
int *end;
/*for leaf nodes, it stores the index of suffix for
the path from root to leaf*/
int suffixIndex;
//To store indices of children suffixes in given string
unordered_set< int > *forwardIndices;
//To store indices of children suffixes in reversed string
unordered_set< int > *reverseIndices;
};
typedef struct SuffixTreeNode Node;
char text[100]; //Input string
Node *root = NULL; //Pointer to root node
/*lastNewNode will point to newly created internal node, waiting for it's suffix link to be set, which might get
a new suffix link (other than root) in next extension of
same phase. lastNewNode will be set to NULL when last
newly created internal node (if there is any) got it's
suffix link reset to new internal node created in next
extension of same phase. */
Node *lastNewNode = NULL;
Node *activeNode = NULL;
/*activeEdge is represeted as input string character
index (not the character itself)*/
int activeEdge = -1;
int activeLength = 0;
// remainingSuffixCount tells how many suffixes yet to
// be added in tree
int remainingSuffixCount = 0;
int leafEnd = -1;
int *rootEnd = NULL;
int *splitEnd = NULL;
int size = -1; //Length of input string
int size1 = 0; //Size of 1st string
int reverseIndex; //Index of a suffix in reversed string
unordered_set< int >::iterator forwardIndex;
Node *newNode( int start, int *end)
{
Node *node =(Node*) malloc ( sizeof (Node));
int i;
for (i = 0; i < MAX_CHAR; i++)
node->children[i] = NULL;
/*For root node, suffixLink will be set to NULL
For internal nodes, suffixLink will be set to root
by default in current extension and may change in
next extension*/
node->suffixLink = root;
node->start = start;
node->end = end;
/*suffixIndex will be set to -1 by default and
actual suffix index will be set later for leaves
at the end of all phases*/
node->suffixIndex = -1;
node->forwardIndices = new unordered_set< int >;
node->reverseIndices = new unordered_set< int >;
return node;
}
int edgeLength(Node *n) {
if (n == root)
return 0;
return *(n->end) - (n->start) + 1;
}
int walkDown(Node *currNode)
{
/*activePoint change for walk down (APCFWD) using
Skip/Count Trick (Trick 1). If activeLength is greater
than current edge length, set next internal node as
activeNode and adjust activeEdge and activeLength
accordingly to represent same activePoint*/
if (activeLength >= edgeLength(currNode))
{
activeEdge += edgeLength(currNode);
activeLength -= edgeLength(currNode);
activeNode = currNode;
return 1;
}
return 0;
}
void extendSuffixTree( int pos)
{
/*Extension Rule 1, this takes care of extending all
leaves created so far in tree*/
leafEnd = pos;
/*Increment remainingSuffixCount indicating that a
new suffix added to the list of suffixes yet to be
added in tree*/
remainingSuffixCount++;
/*set lastNewNode to NULL while starting a new phase, indicating there is no internal node waiting for
it's suffix link reset in current phase*/
lastNewNode = NULL;
//Add all suffixes (yet to be added) one by one in tree
while (remainingSuffixCount > 0) {
if (activeLength == 0)
activeEdge = pos; //APCFALZ
// There is no outgoing edge starting with
// activeEdge from activeNode
if (activeNode->children] == NULL)
{
//Extension Rule 2 (A new leaf edge gets created)
activeNode->children] =
newNode(pos, &leafEnd);
/*A new leaf edge is created in above line starting
from an existng node (the current activeNode), and
if there is any internal node waiting for it's suffix
link get reset, point the suffix link from that last
internal node to current activeNode. Then set lastNewNode
to NULL indicating no more node waiting for suffix link
reset.*/
if (lastNewNode != NULL)
{
lastNewNode->suffixLink = activeNode;
lastNewNode = NULL;
}
}
// There is an outgoing edge starting with activeEdge
// from activeNode
else
{
// Get the next node at the end of edge starting
// with activeEdge
Node *next = activeNode->children] ;
if (walkDown(next)) //Do walkdown
{
//Start from next node (the new activeNode)
continue ;
}
/*Extension Rule 3 (current character being processed
is already on the edge)*/
if (text[next->start + activeLength] == text[pos])
{
//APCFER3
activeLength++;
/*STOP all further processing in this phase
and move on to next phase*/
break ;
}
/*We will be here when activePoint is in middle of
the edge being traversed and current character
being processed is not on the edge (we fall off
the tree). In this case, we add a new internal node
and a new leaf edge going out of that new node. This
is Extension Rule 2, where a new leaf edge and a new
internal node get created*/
splitEnd = ( int *) malloc ( sizeof ( int ));
*splitEnd = next->start + activeLength - 1;
//New internal node
Node *split = newNode(next->start, splitEnd);
activeNode->children] = split;
//New leaf coming out of new internal node
split->children] = newNode(pos, &leafEnd);
next->start += activeLength;
split->children] = next;
/*We got a new internal node here. If there is any
internal node created in last extensions of same
phase which is still waiting for it's suffix link
reset, do it now.*/
if (lastNewNode != NULL)
{
/*suffixLink of lastNewNode points to current newly
created internal node*/
lastNewNode->suffixLink = split;
}
/*Make the current newly created internal node waiting
for it's suffix link reset (which is pointing to root
at present). If we come across any other internal node
(existing or newly created) in next extension of same
phase, when a new leaf edge gets added (i.e. when
Extension Rule 2 applies is any of the next extension
of same phase) at that point, suffixLink of this node
will point to that internal node.*/
lastNewNode = split;
}
/* One suffix got added in tree, decrement the count of
suffixes yet to be added.*/
remainingSuffixCount--;
if (activeNode == root && activeLength > 0) //APCFER2C1
{
activeLength--;
activeEdge = pos - remainingSuffixCount + 1;
}
else if (activeNode != root) //APCFER2C2
{
activeNode = activeNode->suffixLink;
}
}
}
void print( int i, int j)
{
int k;
for (k=i; k<=j && text[k] != '#' ; k++)
printf ( "%c" , text[k]);
if (k<=j)
printf ( "#" );
}
//Print the suffix tree as well along with setting suffix index
//So tree will be printed in DFS manner
//Each edge along with it's suffix index will be printed
void setSuffixIndexByDFS(Node *n, int labelHeight)
{
if (n == NULL) return ;
if (n->start != -1) //A non-root node
{
//Print the label on edge from parent to current node
//Uncomment below line to print suffix tree
//print(n->start, *(n->end));
}
int leaf = 1;
int i;
for (i = 0; i < MAX_CHAR; i++)
{
if (n->children[i] != NULL)
{
//Uncomment below two lines to print suffix index
// if (leaf == 1 && n->start != -1)
// printf(" [%d]\n", n->suffixIndex);
//Current node is not a leaf as it has outgoing
//edges from it.
leaf = 0;
setSuffixIndexByDFS(n->children[i], labelHeight +
edgeLength(n->children[i]));
if (n != root)
{
//Add chldren's suffix indices in parent
n->forwardIndices->insert(
n->children[i]->forwardIndices->begin(), n->children[i]->forwardIndices->end());
n->reverseIndices->insert(
n->children[i]->reverseIndices->begin(), n->children[i]->reverseIndices->end());
}
}
}
if (leaf == 1)
{
for (i= n->start; i<= *(n->end); i++)
{
if (text[i] == '#' )
{
n->end = ( int *) malloc ( sizeof ( int ));
*(n->end) = i;
}
}
n->suffixIndex = size - labelHeight;
if (n->suffixIndex < size1) //Suffix of Given String
n->forwardIndices->insert(n->suffixIndex);
else //Suffix of Reversed String
n->reverseIndices->insert(n->suffixIndex - size1);
//Uncomment below line to print suffix index
// printf(" [%d]\n", n->suffixIndex);
}
}
void freeSuffixTreeByPostOrder(Node *n)
{
if (n == NULL)
return ;
int i;
for (i = 0; i < MAX_CHAR; i++)
{
if (n->children[i] != NULL)
{
freeSuffixTreeByPostOrder(n->children[i]);
}
}
if (n->suffixIndex == -1)
free (n->end);
free (n);
}
/*Build the suffix tree and print the edge labels along with
suffixIndex. suffixIndex for leaf edges will be >= 0 and
for non-leaf edges will be -1*/
void buildSuffixTree()
{
size = strlen (text);
int i;
rootEnd = ( int *) malloc ( sizeof ( int ));
*rootEnd = - 1;
/*Root is a special node with start and end indices as -1, as it has no parent from where an edge comes to root*/
root = newNode(-1, rootEnd);
activeNode = root; //First activeNode will be root
for (i=0; i<size; i++)
extendSuffixTree(i);
int labelHeight = 0;
setSuffixIndexByDFS(root, labelHeight);
}
void doTraversal(Node *n, int labelHeight, int * maxHeight, int * substringStartIndex)
{
if (n == NULL)
{
return ;
}
int i=0;
int ret = -1;
if (n->suffixIndex < 0) //If it is internal node
{
for (i = 0; i < MAX_CHAR; i++)
{
if (n->children[i] != NULL)
{
doTraversal(n->children[i], labelHeight +
edgeLength(n->children[i]), maxHeight, substringStartIndex);
if (*maxHeight < labelHeight
&& n->forwardIndices->size() > 0 &&
n->reverseIndices->size() > 0)
{
for (forwardIndex=n->forwardIndices->begin();
forwardIndex!=n->forwardIndices->end();
++forwardIndex)
{
reverseIndex = (size1 - 2) -
(*forwardIndex + labelHeight - 1);
//If reverse suffix comes from
//SAME position in given string
//Keep track of deepest node
if (n->reverseIndices->find(reverseIndex) !=
n->reverseIndices->end())
{
*maxHeight = labelHeight;
*substringStartIndex = *(n->end) -
labelHeight + 1;
break ;
}
}
}
}
}
}
}
void getLongestPalindromicSubstring()
{
int maxHeight = 0;
int substringStartIndex = 0;
doTraversal(root, 0, &maxHeight, &substringStartIndex);
int k;
for (k=0; k<maxHeight; k++)
printf ( "%c" , text[k + substringStartIndex]);
if (k == 0)
printf ( "No palindromic substring" );
else
printf ( ", of length: %d" , maxHeight);
printf ( "\n" );
}
// driver program to test above functions
int main( int argc, char *argv[])
{
size1 = 9;
printf ( "Longest Palindromic Substring in cabbaabb is: " );
strcpy (text, "cabbaabb#bbaabbac$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 17;
printf ( "Longest Palindromic Substring in forgeeksskeegfor is: " );
strcpy (text, "forgeeksskeegfor#rofgeeksskeegrof$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 6;
printf ( "Longest Palindromic Substring in abcde is: " );
strcpy (text, "abcde#edcba$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 7;
printf ( "Longest Palindromic Substring in abcdae is: " );
strcpy (text, "abcdae#eadcba$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 6;
printf ( "Longest Palindromic Substring in abacd is: " );
strcpy (text, "abacd#dcaba$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 6;
printf ( "Longest Palindromic Substring in abcdc is: " );
strcpy (text, "abcdc#cdcba$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 13;
printf ( "Longest Palindromic Substring in abacdfgdcaba is: " );
strcpy (text, "abacdfgdcaba#abacdgfdcaba$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 15;
printf ( "Longest Palindromic Substring in xyabacdfgdcaba is: " );
strcpy (text, "xyabacdfgdcaba#abacdgfdcabayx$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 9;
printf ( "Longest Palindromic Substring in xababayz is: " );
strcpy (text, "xababayz#zyababax$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 6;
printf ( "Longest Palindromic Substring in xabax is: " );
strcpy (text, "xabax#xabax$" ); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
return 0;
}输出如下:
Longest Palindromic Substring in cabbaabb is: bbaabb, of length: 6
Longest Palindromic Substring in forgeeksskeegfor is: geeksskeeg, of length: 10
Longest Palindromic Substring in abcde is: a, of length: 1
Longest Palindromic Substring in abcdae is: a, of length: 1
Longest Palindromic Substring in abacd is: aba, of length: 3
Longest Palindromic Substring in abcdc is: cdc, of length: 3
Longest Palindromic Substring in abacdfgdcaba is: aba, of length: 3
Longest Palindromic Substring in xyabacdfgdcaba is: aba, of length: 3
Longest Palindromic Substring in xababayz is: ababa, of length: 5
Longest Palindromic Substring in xabax is: xabax, of length: 5跟进:
在给定的字符串中检测所有回文。
例如对于字符串abcddcbefgf, 所有可能的回文均是a, b, c, d, e, f, g, dd, fgf, cddc, bcddcb。
我们已经发布了更多关于后缀树应用程序的文章:
- 后缀树应用程序1 –子字符串检查
- 后缀树应用程序2 –搜索所有模式
- 后缀树应用3 –最长重复子串
- 后缀树应用程序4 –构建线性时间后缀数组
- 后缀树应用程序5 –最长公共子串
- 广义后缀树1
本文作者:阿努拉格·辛格(Anurag Singh)。如果发现任何不正确的地方, 或者你想分享有关上述主题的更多信息, 请发表评论
![从字法上最小长度N的排列,使得对于正好为K个索引,a[i] a[i]+1](https://www.lsbin.com/wp-content/themes/begin%20lts/img/loading.png)
