
随机森林
基本上是套袋技术。从名称可以清楚地了解到, 该算法基本上创建了具有许多树木的森林。它是一种监督分类算法。
在一般情况下, 如果我们在森林中有更多的树木, 则它对所有人都具有最佳的美学吸引力, 被视为最佳森林。随机森林分类器中的情况也是如此, 树的数量越多, 准确度越好, 因此它是一个更好的模型。在随机森林中, 将不会使用你在决策树中使用的相同方法, 即熵和信息增益。在随机森林中, 我们从训练集中绘制随机引导样本。
随机森林的优势:
- 非常适合处理大型数据集。
- 学习速度快, 准确性高。
- 可以一次处理大量变量。
- 过度拟合在该算法中不是问题。
随机森林的缺点:
- 复杂性是一个主要问题。由于该算法创建了许多树并将其输出合并以产生最佳输出, 因此需要更多的计算时间和资源。
- 通常, 训练随机森林模型的时间段较长, 因为它会生成大量树木。
并行运算
并行计算基本上是指在同一实例中使用两个或多个内核(或处理器)来解决一个存在的问题。这里的主要目标是将任务分解为较小的子任务, 并同时完成它们。
一个简单的数学示例将清除并行计算背后的基本思想:
假设我们有以下表达式来求值:
Z= 7a + 8b + 2c + 3d其中a = 1, b = 2, c = 9, d = 5
没有并行计算的正常过程将是:
第1步:输入变量的值。
Z = (7*1) + (8*2) + (2*9) + (3*5)第2步:计算表达式:
Z = 7 + (8*2) + (2*9) + (3*5)第三步:
Z = 7 + 16 + (2*9) + (3*5)步骤4:
Z = 7 + 16 + 18 + (3*5)步骤5:
Z = 7 + 16 + 18 + 15步骤6:
Z = 56在并行计算的情况下, 相同的表达式评估如下:
第1步:输入变量的值。
Z = (7*1) + (8*2) + (2*9) + (3*5)第2步:计算表达式:
Z = 7 + 16 + 18 + 15第三步:
Z = 56因此, 我们可以看到上面的区别, 在第二种情况下, 表达式的计算要快得多。
因此, 我已经获取了雷达数据的数据集。它总共包含35个属性。第35个属性是目标变量" g"或" b"。该目标变量主要表示电离层中的自由电子。 " g"代表良好, "雷达"返回是指电离层中某种类型的结构的证据, " b"代表"不良", 是指没有返回的。它们的信号通过电离层。因此, 基本上, 这是一个二进制分类任务。让我们从编码部分开始。
加载所需的库:
library (caret)
library (randomForest)
library (doParallel)读取数据集:
datafile<- read.csv ( "C:/Users/prana/Downloads/lsbinphere.data.csv" )
datafile将目标变量转换为标签为0和1的因子变量。还请检查是否缺少值。
datafile$target0]
set.seed (100)由于没有缺失值, 因此我们有一个干净的数据集。因此, 转到模型构建部分。将数据集分成80:20的比例, 分别是训练集和测试集。
Trainingindex<- createDataPartition (datafile$target, p=0.8, list= FALSE )
trainingset<-datafile[Trainingindex, ]
testingset<-datafile[-Trainingindex, ]无需并行计算即可实现随机森林
现在, 我们将正常构建模型并记录相同的时间:
start.time<- proc.time ()
model<- train (target~., data=trainingset, method= 'rf' )
stop.time<- proc.time ()
run.time<-stop.time -start.time
print (run.time)输出如下:
user system elapsed
13.05 0.20 13.62并行计算实现随机森林
现在使用并行计算概念构建模型, 将do Parallel库加载到R中(此处我们已经在开始时加载了它, 因此无需再次加载)。我们可以看到功能makePSOCKcluster()它创建一组并行运行并通过套接字通信的R副本。的stopCluster()在cl中停止集群中的引擎节点。我们还将记录通过这种方法建立模型所花费的时间。
cl<- makePSOCKcluster (5)
registerDoParallel (cl)
start.time<- proc.time ()
model<- train (target~., data=trainingset, method= 'rf' )
stop.time<- proc.time ()
run.time<-stop.time -start.time
print (run.time)
stopCluster (cl)输出如下:
user system elapsed
0.56 0.02 6.19时差比较表
因此, 现在制定一张表格, 向我们展示这两种方法的时间。
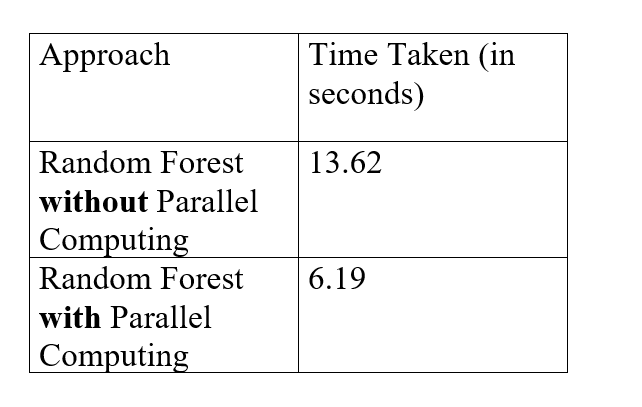
因此, 从上表可以得出结论, 使用并行计算, 建模过程为2.200323(= 13.62 / 6.19)比普通方法快十倍。
![从字法上最小长度N的排列,使得对于正好为K个索引,a[i] a[i]+1](https://www.lsbin.com/wp-content/themes/begin%20lts/img/loading.png)
