
随机森林法是监督的非线性分类和回归算法。分类是将类别或类别的一组数据集分类的过程。作为随机森林方法, 可以根据用户和所需的目标或类别使用分类或回归技术。随机森林是决策树的集合, 这些决策树以更高的概率指定类别。由于决策树缺乏准确性, 并且由于称为过拟合的过程, 决策树在测试阶段也显示出较低的准确性, 因此使用了随机森林方法而非决策树方法。在R编程, randomForest()的功能randomForest软件包用于创建和分析随机森林。在本文中, 我们将讨论随机森林, 学习R编程中用于分类的随机森林方法的语法和实现, 并绘制进一步的图表以进行推断。
随机森林
随机森林是一种机器学习算法, 它使用决策树的集合来提供更大的灵活性, 准确性和易于访问的输出。与随机森林算法相比, 该算法在决策树算法上占优势, 因为决策树提供的准确性较差。简而言之, 随机森林方法可提高决策树的性能。这是最好的算法之一, 因为它可以同时使用分类和回归技术。作为一种有监督的学习算法, 随机森林在决策树中使用装袋法, 从而提高了学习模型的准确性。
随机森林从特征的随机子集中搜索最佳特征, 从而为模型提供更多的随机性, 从而获得更好, 更准确的模型。让我们通过一个例子来学习随机森林方法。假设一个名叫鲍勃的人想从商店买一件T恤。推销员首先问他最喜欢的颜色。这构成了基于颜色特征的决策树。此外, 推销员询问有关T恤的更多信息, 例如尺寸, 面料类型, 衣领类型等等。选择T恤的更多标准将在机器学习中做出更多决策树。所有决策树将共同构成一种随机森林方法, 该方法基于Bob想要从商店购买的许多功能来选择T恤。
分类
分类是一种有监督的学习方法, 其中根据提供的功能对数据进行分类。如以上示例所示, 使用随机森林将数据分类为不同的参数。它有助于创建更多有意义的观察值或分类。简而言之, 分类是将结构化或非结构化数据分类为某些类别或类的一种方式。有8种主要的分类算法:
- 逻辑回归
- 朴素贝叶斯
- K最近邻居
- 决策树
- 随机森林
- 人工神经网络
- 支持向量机
- 随机梯度下降
现实世界中的一些分类示例是:可以将邮件指定为垃圾邮件或非垃圾邮件, 可以将垃圾指定为纸张垃圾, 塑料垃圾, 有机垃圾或电子垃圾, 可以根据许多症状确定疾病, 进行情感分析并确定性别面部表情等
实施随机森林分类法
语法:randomForest(formula, data)参数:公式:表示描述要拟合模型的公式数据:表示包含模型中变量的数据框
例子:
在此示例中, 让我们在虹膜数据集上使用监督学习, 根据函数中传递的参数对虹膜植物进行分类。
第1步:
安装所需的库
# Install the required
# Package for function
install.packages ( "randomForest" )第2步:加载所需的库
# Load the library
library (randomForest)第三步:在中使用虹膜数据集randomForest()函数
# Create random forest
# For classification
iris.rf <- randomForest (Species ~ ., data = iris, importance = TRUE , proximity = TRUE )步骤4:打印以上步骤中构建的分类模型
# Print classification model
print (iris.rf)输出如下:
Call:
randomForest(formula = Species ~ ., data = iris, importance = TRUE, proximity = TRUE)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 2
OOB estimate of error rate: 5.33%
Confusion matrix:
setosa versicolor virginica class.error
setosa 50 0 0 0.00
versicolor 0 47 3 0.06
virginica 0 5 45 0.10步骤5:在误差和树数之间绘制图
# Output to be present
# As PNG file
png (file = "randomForestClassification.png" )
# Plot the error vs
# The number of trees graph
plot (iris.rf)
# Saving the file
dev.off ()输出如下:
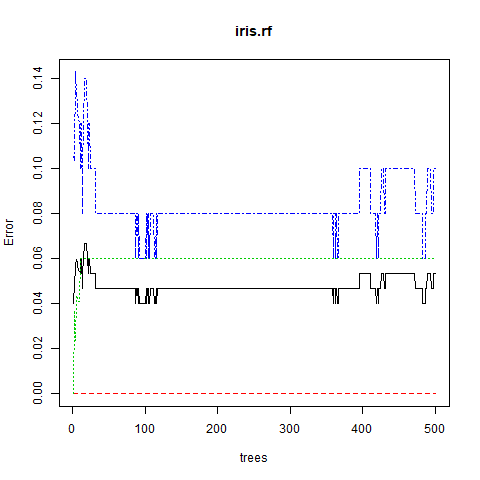
说明:
执行完上述代码后, 将产生输出, 该输出显示使用针对随机森林算法的分类模型开发的决策树的数量, 即500个决策树。混淆矩阵也称为错误矩阵, 它显示了分类模型的性能的可视化。
![从字法上最小长度N的排列,使得对于正好为K个索引,a[i] a[i]+1](https://www.lsbin.com/wp-content/themes/begin%20lts/img/loading.png)
