
你正在准备 SQL 开发人员面试吗?
那么你来对地方了。
本指南将帮助你提高 SQL 技能、重拾信心并做好工作准备!
在这个SQL常见的面试题和答案合集中,你将找到谷歌、甲骨文、亚马逊和微软等公司提出的一系列真实面试问题。每个问题都附有完美的内嵌答案,节省你的面试准备时间。
它还包括练习题,以帮助你理解 SQL 的基本概念。
我们将本文分为以下几个部分:
- SQL 面试问题
- PostgreSQL 面试题
SQL常见的面试题有哪些
1. 什么是数据库?
数据库是有组织的数据集合,从远程或本地计算机系统以数字方式存储和检索。数据库可能庞大而复杂,而此类数据库是使用固定设计和建模方法开发的。
2. 什么是数据库管理系统?
SQL面试题解析:DBMS 代表数据库管理系统。DBMS是负责数据库的创建、检索、更新和管理的系统软件。它通过充当数据库与其最终用户或应用程序软件之间的接口,确保我们的数据一致、有条理并且易于访问。
3. 什么是关系型数据库?它与 DBMS 有何不同?
RDBMS 代表关系数据库管理系统。与 DBMS 相比,这里的关键区别在于 RDBMS 以表集合的形式存储数据,并且可以在这些表的公共字段之间定义关系。大多数现代数据库管理系统(如 MySQL、Microsoft SQL Server、Oracle、IBM DB2 和 Amazon Redshift)都基于 RDBMS。
4.什么是SQL?
SQL 代表结构化查询语言。它是关系数据库管理系统的标准语言。它在处理由实体(变量)和不同数据实体之间的关系组成的有组织的数据时特别有用。
5. SQL 和 MySQL 有什么区别?
SQL 是一种用于检索和操作结构化数据库的标准语言。相反,MySQL 是一种关系型数据库管理系统,类似于 SQL Server、Oracle 或 IBM DB2,用于管理 SQL 数据库。
6. 什么是表和字段?
表是以行和列的形式存储的有组织的数据集合。列可以归类为垂直,行可以归类为水平。表中的列称为字段,而行可以称为记录。
7. SQL 中的约束是什么?
约束用于指定有关表中数据的规则。它可以在创建表期间或使用 ALTER TABLE 命令创建后应用于 SQL 表中的单个或多个字段。约束条件是:
- NOT NULL - 限制将 NULL 值插入到列中。
- CHECK - 验证字段中的所有值是否满足条件。
- DEFAULT - 如果没有为该字段指定值,则自动分配一个默认值。
- UNIQUE - 确保将唯一值插入到字段中。
- INDEX - 索引一个字段,提供更快的记录检索。
- PRIMARY KEY - 唯一标识表中的每条记录。
- FOREIGN KEY - 确保另一个表中记录的参照完整性。
8. 什么是主键?
PRIMARY KEY 约束唯一标识表中的每一行。它必须包含 UNIQUE 值并具有隐式 NOT NULL 约束。
SQL 中的表严格限制只有一个主键,主键由单个或多个字段(列)组成。
CREATE TABLE Students ( /* Create table with a single field as primary key */
ID INT NOT NULL
Name VARCHAR(255)
PRIMARY KEY (ID)
);
CREATE TABLE Students ( /* Create table with multiple fields as primary key */
ID INT NOT NULL
LastName VARCHAR(255)
FirstName VARCHAR(255) NOT NULL,
CONSTRAINT PK_Student
PRIMARY KEY (ID, FirstName)
);
ALTER TABLE Students /* Set a column as primary key */
ADD PRIMARY KEY (ID);
ALTER TABLE Students /* Set multiple columns as primary key */
ADD CONSTRAINT PK_Student /*Naming a Primary Key*/
PRIMARY KEY (ID, FirstName);编写一条sql语句,将主键't_id'添加到'teachers'表中。
编写一条 SQL 语句,为表 'table_a' 和字段 'col_b, col_c' 添加主键约束 'pk_a'。
9. 什么是 UNIQUE 约束?
UNIQUE 约束确保列中的所有值都不同。这为列提供了唯一性,并有助于唯一地标识每一行。与主键不同,每个表可以定义多个唯一约束。UNIQUE 的代码语法与 PRIMARY KEY 的代码语法非常相似,可以互换使用。
CREATE TABLE Students ( /* Create table with a single field as unique */
ID INT NOT NULL UNIQUE
Name VARCHAR(255)
);
CREATE TABLE Students ( /* Create table with multiple fields as unique */
ID INT NOT NULL
LastName VARCHAR(255)
FirstName VARCHAR(255) NOT NULL
CONSTRAINT PK_Student
UNIQUE (ID, FirstName)
);
ALTER TABLE Students /* Set a column as unique */
ADD UNIQUE (ID);
ALTER TABLE Students /* Set multiple columns as unique */
ADD CONSTRAINT PK_Student /* Naming a unique constraint */
UNIQUE (ID, FirstName);10. 什么是外键?
FOREIGN KEY 由表中的单个字段或字段集合组成,这些字段实质上是指另一个表中的 PRIMARY KEY。外键约束确保两个表之间关系的参照完整性。
带有外键约束的表被标记为子表,包含候选键的表被标记为被引用或父表。
CREATE TABLE Students ( /* Create table with foreign key - Way 1 */
ID INT NOT NULL
Name VARCHAR(255)
LibraryID INT
PRIMARY KEY (ID)
FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID)
);
CREATE TABLE Students ( /* Create table with foreign key - Way 2 */
ID INT NOT NULL PRIMARY KEY
Name VARCHAR(255)
LibraryID INT FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID)
);
ALTER TABLE Students /* Add a new foreign key */
ADD FOREIGN KEY (LibraryID)
REFERENCES Library (LibraryID);外键确保什么类型的完整性约束?
编写一条 SQL 语句,在 'table_y' 中添加一个引用 'table_x' 中的 'col_pk' 的 FOREIGN KEY 'col_fk'。
11. SQL常见的面试题有哪些:什么是join?列出它的不同类型。
SQL Join 子句用于根据两个或多个表之间的相关列组合来自 SQL 数据库中两个或多个表的记录(行)。
SQL 中有四种不同类型的 JOIN:
- (INNER) JOIN:检索在连接涉及的两个表中具有匹配值的记录。这是广泛用于查询的连接。
SELECT *
FROM Table_A
JOIN Table_B;
SELECT *
FROM Table_A
INNER JOIN Table_B;- LEFT (OUTER) JOIN:从左侧检索所有记录/行,从右侧表中检索匹配的记录/行。
SELECT *
FROM Table_A A
LEFT JOIN Table_B B
ON A.col = B.col;- RIGHT (OUTER) JOIN:从右侧检索所有记录/行,从左侧表中检索匹配的记录/行。
SELECT *
FROM Table_A A
RIGHT JOIN Table_B B
ON A.col = B.col;- FULL (OUTER) JOIN:检索左表或右表中存在匹配项的所有记录。
SELECT *
FROM Table_A A
FULL JOIN Table_B B
ON A.col = B.col;12. 什么是自联接?
一个自连接是的情况下,常规连接,其中一台是基于它自己的列(S)之间的一些关系,与其自身连接。自联接使用 INNER JOIN 或 LEFT JOIN 子句,表别名用于为查询中的表分配不同的名称。
SELECT A.emp_id AS "Emp_ID",A.emp_name AS "Employee",
B.emp_id AS "Sup_ID",B.emp_name AS "Supervisor"
FROM employee A, employee B
WHERE A.emp_sup = B.emp_id;13. 什么是交叉连接?
交叉联接可以定义为联接中包含的两个表的笛卡尔积。连接后的表包含的行数与两个表中行数的叉积中的行数相同。如果在交叉联接中使用 WHERE 子句,则查询将像 INNER JOIN 一样工作。
SELECT stu.name, sub.subject
FROM students AS stu
CROSS JOIN subjects AS sub;将 SQL 语句写入 CROSS JOIN 'table_1' 和 'table_2' 并分别从 table_1 和 'col_2' 中获取 'col_1' from table_2。不要使用别名。
编写 SQL 语句,分别在列 'Col_1' 和 'Col_2' 上为别名为 'Table_1' 和 'Table_2' 的 'Table_X' 执行 SELF JOIN。
14. 什么是索引?解释它的不同类型。
数据库索引是一种数据结构,可以快速查找表的一列或多列中的数据。它提高了从数据库表访问数据的操作速度,但需要额外的写入和内存来维护索引数据结构。
CREATE INDEX index_name /* Create Index */
ON table_name (column_1, column_2);
DROP INDEX index_name; /* Drop Index */可以为不同的目的创建不同类型的索引:
- 唯一和非唯一索引:
唯一索引是通过确保表中没有两行数据具有相同键值来帮助维护数据完整性的索引。一旦为表定义了唯一索引,只要在索引中添加或更改键,就会强制执行唯一性。
CREATE UNIQUE INDEX myIndex
ON students (enroll_no);另一方面,非唯一索引不用于对与其关联的表实施约束。相反,非唯一索引仅用于通过维护经常使用的数据值的排序顺序来提高查询性能。
- 聚集和非聚集索引:
聚集索引是数据库中行的顺序与索引中的行的顺序相对应的索引。这就是为什么给定的表中只能存在一个聚集索引,而表中可以存在多个非聚集索引的原因。
聚簇索引和非聚簇索引之间的唯一区别在于,数据库管理器尝试按照相应键出现在聚簇索引中的相同顺序来保存数据库中的数据。
集群索引可以提高大多数查询操作的性能,因为它们提供了对存储在数据库中的数据的线性访问路径。
编写 SQL 语句,在“my_table”上为字段“column_1”和“column_2”创建唯一索引“my_index”。
15. 聚集索引和非聚集索引有什么区别?
如上所述,差异可以分为三个小因素 -
- 聚集索引根据索引列修改记录在数据库中的存储方式。非聚集索引在引用原始表的表中创建一个单独的实体。
- 聚集索引用于从数据库中轻松快速地检索数据,而从非聚集索引中获取记录相对较慢。
- 在 SQL 中,一个表可以有一个聚集索引,而它可以有多个非聚集索引。
16. 什么是数据完整性?
数据完整性是数据在整个生命周期内的准确性和一致性的保证,是任何存储、处理或检索数据的系统的设计、实施和使用的关键方面。它还定义了完整性约束,以便在数据输入应用程序或数据库时对数据实施业务规则。
17. 什么是查询?
查询是对来自数据库表或表组合的数据或信息的请求。数据库查询可以是选择查询或操作查询。
SELECT fname, lname /* select query */
FROM myDb.students
WHERE student_id = 1;UPDATE myDB.students /* action query */
SET fname = 'Captain', lname = 'America'
WHERE student_id = 1;18. SQL常见的面试题和答案合集:什么是子查询?它的种类有哪些?
子查询是另一个查询中的查询,也称为嵌套查询或内部查询。用于限制或增强主查询要查询的数据,从而分别限制或增强主查询的输出。例如,我们在这里获取已注册数学科目的学生的联系信息:
SELECT name, email, mob, address
FROM myDb.contacts
WHERE roll_no IN (
SELECT roll_no
FROM myDb.students
WHERE subject = 'Maths');有两种类型的子查询 - Correlated和Non-Correlated。
- 甲相关子查询不能被认为是一个独立的查询,但它可以指列在从主查询的列表。
- 一个不相关的子查询可以被认为是一个独立的查询,子查询的输出被替换在主查询中。
编写 SQL 查询以将表“applications”中的字段“status”从 0 更新为 1。
编写 SQL 查询以选择表“applications”中“app_id”小于 1000 的字段“app_id”。
编写 SQL 查询以从“apps”中获取字段“app_name”,其中“apps.id”等于上述“app_id”集合。
19.什么是SELECT语句?
SQL 中的 SELECT 运算符用于从数据库中选择数据。返回的数据存储在一个结果表中,称为结果集。
SELECT * FROM myDB.students;20、SQL中SELECT查询常用的子句有哪些?
与 SELECT 查询结合使用的一些常见 SQL 子句如下:
- SQL 中的WHERE子句用于根据特定条件过滤必要的记录。
- SQL 中的ORDER BY子句用于根据某些字段按升序 ( ASC ) 或降序 ( DESC)对记录进行排序。
SELECT *
FROM myDB.students
WHERE graduation_year = 2019
ORDER BY studentID DESC;- SQL 中的GROUP BY子句用于对具有相同数据的记录进行分组,并且可以与一些聚合函数结合使用以从数据库中生成汇总结果。
- SQL 中的HAVING子句结合 GROUP BY 子句用于过滤记录。它与 WHERE 不同,因为 WHERE 子句不能过滤聚合记录。
SELECT COUNT(studentId), country
FROM myDB.students
WHERE country != "INDIA"
GROUP BY country
HAVING COUNT(studentID) > 5;21. 什么是 UNION、MINUS 和 INTERSECT 命令?
的UNION操作者组合并返回结果集由两个或多个SELECT语句检索。SQL 中
的MINUS运算符用于从第一个 SELECT 查询获得的结果集中删除第二个 SELECT 查询获得的结果集中的重复项,然后返回第一个筛选后的结果。SQL 中
的INTERSECT子句组合了两个 SELECT 语句获取的结果集,其中一个的记录与另一个匹配,然后返回这个结果集的交集。
在 SQL 中执行上述任一语句之前需要满足某些条件 -
- 子句中的每个 SELECT 语句必须具有相同的列数
- 列也必须具有相似的数据类型
- 每个 SELECT 语句中的列必须具有相同的顺序
SELECT name FROM Students /* Fetch the union of queries */
UNION
SELECT name FROM Contacts;
SELECT name FROM Students /* Fetch the union of queries with duplicates*/
UNION ALL
SELECT name FROM Contacts;SELECT name FROM Students /* Fetch names from students */
MINUS /* that aren't present in contacts */
SELECT name FROM Contacts;SELECT name FROM Students /* Fetch names from students */
INTERSECT /* that are present in contacts as well */
SELECT name FROM Contacts;编写 SQL 查询以获取存在于表“accounts”或表“registry”中的“名称”。
编写一个 SQL 查询来获取存在于“accounts”但不在表“registry”中的“names”。
编写 SQL 查询以从表“contacts”中获取既不在“accounts.name”中也不在“registry.name”中的“姓名”。
22. 什么是光标?如何使用光标?
数据库游标是一种允许遍历数据库中的记录的控制结构。此外,游标还方便了遍历后的处理,如数据库记录的检索、添加和删除。它们可以被视为指向一组行中一行的指针。
使用 SQL 游标:
- DECLARE任何变量声明之后的光标。游标声明必须始终与 SELECT 语句相关联。
- 打开游标以初始化结果集。该OPEN语句必须从结果集中提取行之前被调用。
- FETCH语句来检索并移动到结果集中的下一行。
- 调用CLOSE语句以停用游标。
- 最后使用DEALLOCATE语句删除游标定义并释放相关资源。
DECLARE @name VARCHAR(50) /* Declare All Required Variables */
DECLARE db_cursor CURSOR FOR /* Declare Cursor Name*/
SELECT name
FROM myDB.students
WHERE parent_name IN ('Sara', 'Ansh')
OPEN db_cursor /* Open cursor and Fetch data into @name */
FETCH next
FROM db_cursor
INTO @name
CLOSE db_cursor /* Close the cursor and deallocate the resources */
DEALLOCATE db_cursor23. 什么是实体和关系?
实体:实体可以是现实世界的对象,可以是有形的或无形的,可以很容易地识别。例如,在大学数据库中,学生、教授、工人、部门和项目都可以称为实体。每个实体都有一些关联的属性,为其提供身份。
关系:实体之间相互关联的关系或联系。例如 - 公司数据库中的员工表可以与同一数据库中的工资表相关联。
24. 列出 SQL 中不同类型的关系。
- 一对一- 这可以定义为两个表之间的关系,其中一个表中的每条记录与另一个表中的最多一条记录相关联。
- 一对多和多对一- 这是最常用的关系,其中一个表中的记录与另一个表中的多个记录相关联。
- 多对多- 这用于需要双方的多个实例来定义关系的情况。
- 自引用关系- 当表需要定义与自身的关系时使用。
25. SQL 中的别名是什么?
SQL面试题解析:别名是大多数(如果不是全部)RDBMS 都支持的 SQL 特性。它是为特定 SQL 查询分配给表或表列的临时名称。此外,别名可以用作一种混淆技术来保护数据库字段的真实名称。表别名也称为相关名。
别名由 AS 关键字显式表示,但在某些情况下,没有它也可以执行相同的操作。尽管如此,使用 AS 关键字始终是一个好习惯。
SELECT A.emp_name AS "Employee" /* Alias using AS keyword */
B.emp_name AS "Supervisor"
FROM employee A, employee B /* Alias without AS keyword */
WHERE A.emp_sup = B.emp_id;编写一条 SQL 语句从表“Limited”中选择所有别名“Ltd”。
26. 什么是视图?
SQL 中的视图是基于 SQL 语句结果集的虚拟表。视图包含行和列,就像真正的表一样。视图中的字段是来自数据库中一个或多个真实表的字段。
27.什么是归一化?
规范化代表了在数据库中有效组织结构化数据的方式。它包括创建表、建立它们之间的关系以及为这些关系定义规则。可以根据这些规则检查不一致和冗余,从而增加数据库的灵活性。
28.什么是非规范化?
反规范化是规范化的逆过程,将规范化的模式转换为具有冗余信息的模式。通过使用冗余并保持冗余数据一致来提高性能。执行非规范化的原因是过度规范化结构在查询处理器中产生的开销。
29. SQL常见的面试题有哪些:归一化的各种形式有哪些?
范式用于消除或减少数据库表中的冗余。不同的形式如下:
- 第一范式:
如果该关系中的每个属性都是单值属性,则该关系是第一范式。如果关系包含复合或多值属性,则违反第一范式。让我们考虑以下学生表。桌子上的每个学生都有一个名字,他/她的地址,以及他们从公共图书馆发行的书籍——
Students Table
| Student | Address | Books Issued | Salutation |
|---|---|---|---|
| Sara | Amanora Park Town 94 | Until the Day I Die (Emily Carpenter), Inception (Christopher Nolan) | Ms. |
| Ansh | 62nd Sector A-10 | The Alchemist (Paulo Coelho), Inferno (Dan Brown) | Mr. |
| Sara | 24th Street Park Avenue | Beautiful Bad (Annie Ward), Woman 99 (Greer Macallister) | Mrs. |
| Ansh | Windsor Street 777 | Dracula (Bram Stoker) | Mr. |
正如我们所观察到的,Books Issued 字段的每条记录有多个值,要将其转换为 1NF,必须将其解析为每个已发行图书的单独记录。以 1NF 形式检查下表 -
学生表(第一范式)
| Student | Address | Books Issued | Salutation |
|---|---|---|---|
| Sara | Amanora Park Town 94 | Until the Day I Die (Emily Carpenter) | Ms. |
| Sara | Amanora Park Town 94 | Inception (Christopher Nolan) | Ms. |
| Ansh | 62nd Sector A-10 | The Alchemist (Paulo Coelho) | Mr. |
| Ansh | 62nd Sector A-10 | Inferno (Dan Brown) | Mr. |
| Sara | 24th Street Park Avenue | Beautiful Bad (Annie Ward) | Mrs. |
| Sara | 24th Street Park Avenue | Woman 99 (Greer Macallister) | Mrs. |
| Ansh | Windsor Street 777 | Dracula (Bram Stoker) | Mr. |
- 第二范式:
如果一个关系满足第一范式的条件并且不包含任何部分依赖,则该关系是第二范式。2NF 中的关系没有部分依赖,即它没有依赖于表的任何候选键的任何适当子集的非主要属性。通常,指定单列主键是解决问题的方法。例子 -
示例 1 - 考虑上面的示例。我们可以观察到,1NF形式的Students表有一个[Student, Address]形式的候选键,可以唯一标识表中的所有记录。字段 Books Issued(非主要属性)部分取决于 Student 字段。因此,该表不在 2NF 中。为了将其转换为第二范式,我们将表分为两个,同时指定一个新的主键属性来标识学生表中的各个记录。该外键约束将在另一台被设置为确保引用完整性。
学生表(第二范式)
| Student_ID | Student | Address | Salutation |
|---|---|---|---|
| 1 | Sara | Amanora Park Town 94 | Ms. |
| 2 | Ansh | 62nd Sector A-10 | Mr. |
| 3 | Sara | 24th Street Park Avenue | Mrs. |
| 4 | Ansh | Windsor Street 777 | Mr. |
书籍表(第二范式)
| Student_ID | Book Issued |
|---|---|
| 1 | Until the Day I Die (Emily Carpenter) |
| 1 | Inception (Christopher Nolan) |
| 2 | The Alchemist (Paulo Coelho) |
| 2 | Inferno (Dan Brown) |
| 3 | Beautiful Bad (Annie Ward) |
| 3 | Woman 99 (Greer Macallister) |
| 4 | Dracula (Bram Stoker) |
示例 2 - 考虑以下与 R(W,X,Y,Z) 相关的依赖关系
WX -> Y [W and X together determine Y]
XY -> Z [X and Y together determine Z] 这里,WX 是唯一的候选键,不存在部分依赖,即 WX 的任何真子集不决定关系中的任何非主要属性。
- 第三范式
如果一个关系满足第二范式的条件,并且非主属性之间不存在传递依赖,即所有非主属性仅由关系而不是任何其他非主要属性。
示例 1 - 考虑上面示例中的学生表。正如我们所观察到的,2NF 形式的 Students 表具有单个候选键 Student_ID(主键),可以唯一标识表中的所有记录。然而,字段称呼(非主要属性)取决于学生字段而不是候选键。因此,该表不在 3NF 中。为了将其转换为第三范式,我们将再次将表分成两部分,同时指定一个新的外键约束来标识学生表中各个记录的称呼。将在 Salutations 表上设置相同的主键约束以唯一标识每条记录。
学生表(第三范式)
| Student_ID | Student | Address | Salutation_ID |
|---|---|---|---|
| 1 | Sara | Amanora Park Town 94 | 1 |
| 2 | Ansh | 62nd Sector A-10 | 2 |
| 3 | Sara | 24th Street Park Avenue | 3 |
| 4 | Ansh | Windsor Street 777 | 1 |
书籍表(第三范式)
| Student_ID | Book Issued |
|---|---|
| 1 | Until the Day I Die (Emily Carpenter) |
| 1 | Inception (Christopher Nolan) |
| 2 | The Alchemist (Paulo Coelho) |
| 2 | Inferno (Dan Brown) |
| 3 | Beautiful Bad (Annie Ward) |
| 3 | Woman 99 (Greer Macallister) |
| 4 | Dracula (Bram Stoker) |
称呼表(第三范式)
| Salutation_ID | Salutation |
|---|---|
| 1 | Ms. |
| 2 | Mr. |
| 3 | Mrs. |
示例 2 - 考虑以下与 R(P,Q,R,S,T) 相关的依赖关系
P -> QR [P together determine C]
RS -> T [B and C together determine D]
Q -> S
T -> P 对于存在于 3NF 中的上述关系,上述关系中所有可能的候选键应该是 {P, RS, QR, T}。
- Boyce-Codd范式
如果满足第三范式和每个函数依赖的条件,则关系是 Boyce-Codd 范式,Left-Hand-Side 是超级关键。换句话说,BCNF 中的关系具有形式为 X –> Y 的非平凡函数依赖关系,因此 X 始终是超级键。例如 - 在上面的例子中,Student_ID 作为学生表的唯一唯一标识符,Salutations 表的 Salutation_ID,因此这些表存在于 BCNF 中。对于 Books 表则不能这样说,并且可以有几本书具有相同的书名和相同的 Student_ID。
30. 什么是 TRUNCATE、DELETE 和 DROP 语句?
DELETE语句用于从表中删除行。
DELETE FROM Candidates
WHERE CandidateId > 1000;TRUNCATE命令用于删除表中的所有行并释放包含该表的空间。
TRUNCATE TABLE Candidates;DROP命令用于从数据库中删除一个对象。如果删除一个表,该表中的所有行都将被删除,并且该表结构将从数据库中删除。
DROP TABLE Candidates;编写 SQL 语句以从内存中擦除表“临时”。
编写 SQL 查询以根据 'id' 从表 'Temporary' 中删除前 1000 条记录。
编写一条 SQL 语句来删除表 'Temporary',同时保持其关系完好无损。
31. DROP 和 TRUNCATE 语句有什么区别?
如果一个表被删除,所有与该表相关的东西也会被删除。这包括 - 在表上定义的与其他表的关系、完整性检查和约束、访问权限以及该表具有的其他授权。要以原始形式再次创建和使用该表,需要重新定义所有这些关系、检查、约束、特权和关系。但是,如果表被截断,则上述问题都不存在,并且表保留其原始结构。
32. DELETE 和 TRUNCATE 语句有什么区别?
的TRUNCATE命令用于删除所有从表中的行和含游离表中的空间。
的DELETE命令基于WHERE子句中给出的条件从表中仅删除的行或如果未指定条件从表中删除所有行。但它不会释放包含表的空间。
33. SQL常见的面试题和答案合集:什么是聚合函数和标量函数?
聚合函数对一组值执行操作以返回单个标量值。聚合函数通常与 SELECT 语句的 GROUP BY 和 HAVING 子句一起使用。以下是广泛使用的 SQL 聚合函数:
- AVG() - 计算一组值的平均值。
- COUNT() - 计算特定表或视图中的记录总数。
- MIN() - 计算一组值的最小值。
- MAX() - 计算一组值的最大值。
- SUM() - 计算一组值的总和。
- FIRST() - 获取值集合中的第一个元素。
- LAST() - 获取值集合中的最后一个元素。
注意:除 COUNT 函数外,上述所有聚合函数都忽略 NULL 值。
标量函数根据输入值返回单个值。以下是广泛使用的 SQL 标量函数:
- LEN() - 计算给定字段(列)的总长度。
- UCASE() - 将字符串值的集合转换为大写字符。
- LCASE() - 将字符串值的集合转换为小写字符。
- MID() - 从表中的字符串值集合中提取子字符串。
- CONCAT() - 连接两个或多个字符串。
- RAND() - 生成给定长度的随机数字集合。
- ROUND() - 计算数字字段(或小数点值)的舍入整数值。
- NOW() - 返回当前日期和时间。
- FORMAT() - 设置显示值集合的格式。
34. 什么是自定义函数?它的种类有哪些?
SQL 中的用户定义函数与任何其他编程语言中的函数一样,可以接受参数、执行复杂计算并返回值。它们被编写为在需要时重复使用逻辑。有两种类型的 SQL 用户定义函数:
- 标量函数:如前所述,用户定义的标量函数返回单个标量值。
- 表值函数:用户定义的表值函数返回一个表作为输出。
- 内联:基于单个 SELECT 语句返回表数据类型。
- 多语句:返回一个表格结果集,但与内联不同的是,可以在函数体内使用多个 SELECT 语句。
35.什么是OLTP?
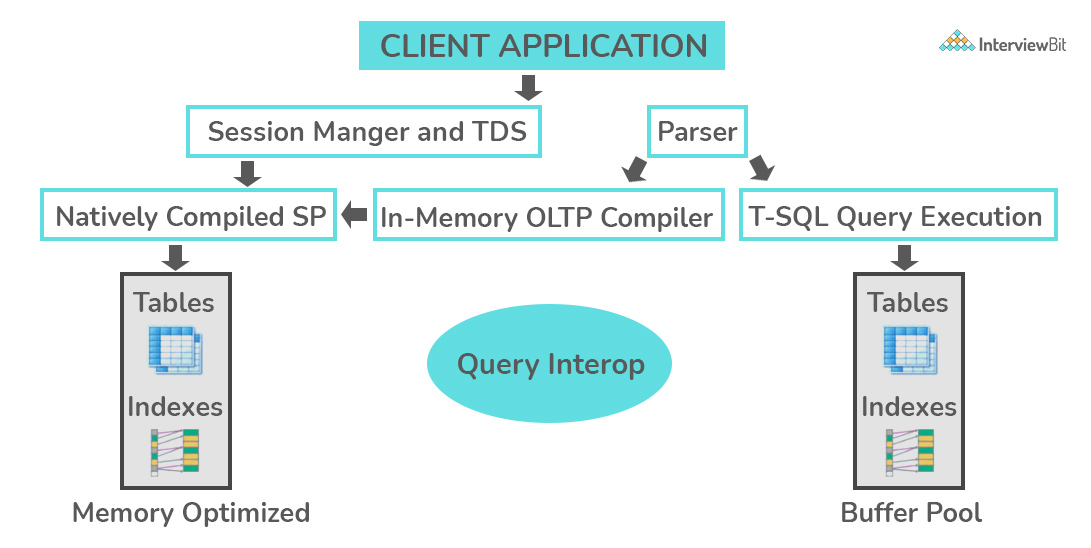
SQL面试题解析:OLTP代表在线事务处理,是一类能够支持面向事务的程序的软件应用程序。OLTP 系统的一个基本属性是其保持并发的能力。为了避免单点故障,OLTP 系统通常是分散的。这些系统通常是为进行短期交易的大量用户设计的。数据库查询通常很简单,需要亚秒级的响应时间,并且返回的记录相对较少。这是对 OLTP 系统工作的深入了解[注意 - 该数字对于面试并不重要] -
36、OLTP和OLAP有什么区别?
OLTP代表在线事务处理,是一类能够支持面向事务的程序的软件应用程序。OLTP 系统的一个重要属性是其保持并发的能力。OLTP 系统通常遵循分散式架构以避免单点故障。这些系统通常是为大量进行短期交易的最终用户设计的。此类数据库中涉及的查询一般比较简单,需要快速的响应时间,并且返回的记录相对较少。每秒的交易数量是此类系统的有效衡量标准。
OLAP代表Online Analytical Processing,是一类软件程序,其特点是在线交易的频率相对较低。查询通常太复杂并且涉及一堆聚合。对于 OLAP 系统,有效性度量高度依赖于响应时间。此类系统广泛用于数据挖掘或维护聚合的历史数据,通常采用多维模式。
37.什么是整理?有哪些不同类型的校对敏感度?
排序规则是指确定如何对数据进行排序和比较的一组规则。定义正确字符序列的规则用于对字符数据进行排序。它包含用于指定区分大小写、重音符号、假名字符类型和字符宽度的选项。以下是不同类型的整理敏感度:
- 区分大小写: A和a的处理方式不同。
- 口音敏感度: a和á的处理方式不同。
- 假名敏感性:日本假名字符平假名和片假名被区别对待。
- 宽度敏感性:以单字节(半角)和双字节(全角)表示的相同字符的处理方式不同。
38. 什么是存储过程?
存储过程是可供访问关系数据库管理系统 (RDBMS) 的应用程序使用的子例程。此类程序存储在数据库数据字典中。存储过程唯一的缺点是它只能在数据库中执行,并且在数据库服务器中占用更多的内存。它还提供了一种安全感和功能性,因为无法直接访问数据的用户可以通过存储过程获得访问权限。
DELIMITER $$
CREATE PROCEDURE FetchAllStudents()
BEGIN
SELECT * FROM myDB.students;
END $$
DELIMITER ;39. 什么是递归存储过程?
在达到边界条件之前调用自身的存储过程称为递归存储过程。此递归函数可帮助程序员在需要时多次部署同一组代码。一些SQL编程语言限制递归深度,以防止过程调用的无限循环导致堆栈溢出,从而减慢系统并可能导致系统崩溃。
DELIMITER $$ /* Set a new delimiter => $$ */
CREATE PROCEDURE calctotal( /* Create the procedure */
IN number INT, /* Set Input and Ouput variables */
OUT total INT
) BEGIN
DECLARE score INT DEFAULT NULL; /* Set the default value => "score" */
SELECT awards FROM achievements /* Update "score" via SELECT query */
WHERE id = number INTO score;
IF score IS NULL THEN SET total = 0; /* Termination condition */
ELSE
CALL calctotal(number+1); /* Recursive call */
SET total = total + score; /* Action after recursion */
END IF;
END $$ /* End of procedure */
DELIMITER ; /* Reset the delimiter */40.如何创建与另一个表结构相同的空表?
通过使用 INTO 运算符将一个表的记录提取到新表中,同时将 WHERE 子句对所有记录固定为 false,可以巧妙地创建具有相同结构的空表。因此,SQL 准备具有重复结构的新表以接受获取的记录,但由于 WHERE 子句在起作用,因此没有获取任何记录,因此不会向新表中插入任何内容。
SELECT * INTO Students_copy
FROM Students WHERE 1 = 2;41. SQL 中的模式匹配是什么?
如果你不知道该词应该是什么,则 SQL 模式匹配提供了数据中的模式搜索。这种 SQL 查询使用通配符来匹配字符串模式,而不是写出确切的单词。LIKE 运算符与SQL 通配符结合使用以获取所需信息。
- 使用 % 通配符执行简单搜索
% 通配符匹配零个或多个任何类型的字符,可用于定义模式前后的通配符。在你的数据库中搜索名字以字母 K 开头的学生:
SELECT *
FROM students
WHERE first_name LIKE 'K%'- 使用 NOT 关键字省略模式
使用 NOT 关键字选择与模式不匹配的记录。此查询返回名字不以 K 开头的所有学生。
SELECT *
FROM students
WHERE first_name NOT LIKE 'K%'- 在任何地方使用 % 通配符匹配模式两次
在数据库中搜索名字中带有 K 的学生。
SELECT *
FROM students
WHERE first_name LIKE '%Q%'- 使用 _ 通配符匹配特定位置的模式
_ 通配符正好匹配任何类型的一个字符。它可以与 % 通配符结合使用。此查询获取名字中第三个位置带有字母 K 的所有学生。
SELECT *
FROM students
WHERE first_name LIKE '__K%'- 匹配特定长度的模式
_ 通配符在精确匹配一个字符时作为一种限制作用发挥着重要作用。它限制了匹配结果的长度和位置。例如 -
SELECT * /* Matches first names with three or more letters */
FROM students
WHERE first_name LIKE '___%'
SELECT * /* Matches first names with exactly four characters */
FROM students
WHERE first_name LIKE '____'PostgreSQL 面试题
42.什么是PostgreSQL?
PostgreSQL 最初被称为 Postgres,由计算机科学教授 Michael Stonebraker 领导的团队于 1986 年开发。它旨在通过使系统容错来维护数据完整性来帮助开发人员构建企业级应用程序。因此,PostgreSQL 是一种企业级、灵活、健壮、开源和对象关系的 DBMS,支持灵活的工作负载以及处理并发用户。它一直得到全球开发者社区的支持。由于其容错性,PostgreSQL 在开发人员中广受欢迎。
43. PostgreSQL 中如何定义索引?
索引是 PostgreSQL 中的内置函数,查询使用它来更有效地对数据库中的表执行搜索。考虑到你有一个包含数千条记录的表,并且你有以下查询,只有少数记录可以满足条件,那么搜索并返回那些符合此条件的行将花费大量时间,因为引擎必须这样做对每个单独执行搜索操作以检查此条件。这对于处理海量数据的系统来说无疑是低效的。现在,如果这个系统在我们应用搜索的列上有一个索引,它可以使用一种有效的方法来识别匹配的行,只需遍历几个级别。这称为索引。
Select * from some_table where table_col=12044. 你将如何改变列的数据类型?
这可以通过使用 ALTER TABLE 语句来完成,如下所示:
句法:
ALTER TABLE tname
ALTER COLUMN col_name [SET DATA] TYPE new_data_type;45、PostgreSQL中创建数据库的命令是什么?
使用 PostgreSQL 的第一步是创建数据库。这是通过使用 createdb 命令完成的,如下所示:createdb db_name
运行上述命令后,如果数据库创建成功,则会显示以下消息:
CREATE DATABASE46.如何启动、重启和停止PostgreSQL服务器?
- 要启动PostgreSQL 服务器,我们运行:
service postgresql start- 一旦服务器启动成功,我们得到以下信息:
Starting PostgreSQL: ok- 要重新启动PostgreSQL 服务器,我们运行:
service postgresql restart服务器成功重启后,我们会收到以下消息:
Restarting PostgreSQL: server stopped
ok- 要停止服务器,我们运行以下命令:
service postgresql stop成功停止后,我们会收到消息:
Stopping PostgreSQL: server stopped
ok47. 什么是PostgreSQL中的分区表?
分区表是用于将大表划分为称为分区的较小结构的逻辑结构。这种方法用于在处理大型数据库表时有效提高查询性能。要创建分区,需要定义一个称为分区键的键,通常是一个表列或一个表达式,并需要定义分区方法。Postgres 提供了三种内置的分区方法:
- 范围分区:此方法是通过基于一系列值进行分区来完成的。此方法最常用于日期字段以获取每月、每周或每年的数据。在像值属于范围末尾的极端情况的情况下,例如:如果分区 1 的范围是 10-20,分区 2 的范围是 20-30,并且给定的值是 10,那么 10 属于到第二个分区而不是第一个分区。
- 列表分区:此方法用于根据已知值列表进行分区。当我们有一个带有分类值的键时最常用。例如,根据区域划分为国家、城市或州来获取销售数据。
- 散列分区:此方法在分区键上使用散列函数。这是在对数据划分没有特定要求的情况下完成的,用于单独访问数据。例如,你要访问基于特定产品的数据,然后使用哈希分区将导致我们需要的数据集。
分区键的类型和用于分区的方法类型决定了分区表的性能和可管理性水平的积极程度。
48.在PostgreSQL中定义token?
PostgreSQL 中的标记可以是关键字、标识符、文字、常量、引号标识符或任何具有独特个性的符号。它们可能会或可能不会使用空格、换行符或制表符分隔。如果标记是关键字,它们通常是具有有用含义的命令。令牌被称为任何 PostgreSQL 代码的构建块。
49. TRUNCATE 语句的重要性是什么?
TRUNCATE TABLE name_of_table语句有效且快速地从表中删除数据。
truncate 语句还可用于重置标识列的值以及数据清理,如下所示:
TRUNCATE TABLE name_of_table
RESTART IDENTITY;我们还可以通过提及以逗号分隔的表名来一次从多个表中删除数据的语句,如下所示:
TRUNCATE TABLE
table_1,
table_2,
table_3;50. PostgreSQL中一张表的容量是多少?
PostgreSQL 的最大大小为 32TB。
51. 定义序列。
序列是模式绑定的、用户定义的对象,它有助于生成整数序列。这最常用于为表中的标识列生成值。我们可以使用CREATE SEQUENCE 如下所示的语句创建一个序列:
CREATE SEQUENCE serial_num START 100;要从序列中获取下一个数字 101,我们使用 nextval() 方法,如下所示:
SELECT nextval('serial_num');我们也可以在使用 INSERT 命令插入新记录时使用这个序列:
INSERT INTO ib_table_name VALUES (nextval('serial_num'), 'interviewbit');52. PostgreSQL 中的字符串常量是什么?
它们是绑定在单引号内的字符序列。这些在数据插入或更新数据库中的字符期间使用。
有以美元引用的特殊字符串常量。语法:$tag$<string_constant>$tag$常量中的标签是可选的,当我们不指定标签时,常量被称为双元字符串文字。
53. 如何获得PostgreSQL中所有数据库的列表?
这可以通过使用命令\l-> 反斜杠后跟小写字母 L 来完成。
54. 如何删除PostgreSQL中的数据库?
这可以通过使用 DROP DATABASE 命令来完成,如下面的语法所示:
DROP DATABASE database_name;如果数据库已成功删除,则会显示以下消息:
DROP DATABASE55. 什么是 ACID 属性?PostgreSQL 是否符合 ACID?
SQL面试题解析:ACID 代表原子性、一致性、隔离性、持久性。它们是数据库事务属性,用于在出现错误和故障时保证数据有效性。
- 原子性:此属性确保事务以全有或全无的方式完成。
- 一致性:这可确保对数据库所做的更新有效并遵循规则和限制。
- 隔离:此属性可确保对所有其他事务可见的事务的完整性。
- 持久性:此属性确保已提交的事务永久存储在数据库中。
PostgreSQL 符合 ACID 属性。
56. 你能解释一下PostgreSQL的架构吗?
- PostgreSQL 的架构遵循客户端-服务器模型。
- 服务器端由后台进程管理器、查询处理器、实用程序和共享内存空间组成,它们共同构建可以访问数据的 PostgreSQL 实例。客户端应用程序执行连接到此实例的任务并向服务请求数据处理。客户端可以是 GUI(图形用户界面)或 Web 应用程序。PostgreSQL 最常用的客户端是 pgAdmin。
57、多版本并发控制怎么理解?
MVCC 或多版本并发控制用于避免当 2 个或多个请求同时尝试访问或修改数据时不必要的数据库锁。这样可以确保避免用户登录数据库的时间延迟。当任何人试图访问内容时,交易就会被记录下来。
有关这方面的更多信息,你可以参考此处。
58、你对enable-debug命令的理解是什么?
命令 enable-debug 用于启用所有库和应用程序的编译。启用此功能后,系统进程会受到阻碍,并且通常还会增加二进制文件的大小。因此,不建议在生产环境中开启此功能。这最常被开发人员用来调试脚本中的错误并帮助他们发现问题。有关如何调试的更多信息,你可以参考此处。
59. 你如何检查作为先前事务的一部分而受影响的行?
SQL 标准规定,并发事务时应防止以下三种现象。SQL 标准定义了 4 个级别的事务隔离来处理这些现象。
- 脏读:如果一个事务读取了由于并发未提交事务而写入的数据,则这些读取称为脏读。
- 幻读:当两个相同的查询分别执行时返回不同的行时,就会发生这种情况。例如,如果事务 A 检索匹配搜索条件的某些行集。假设另一个事务 B 除了先前针对相同搜索条件获得的行之外,还检索新行。结果是不同的。
- 不可重复读取:当事务尝试多次读取同一行并由于并发而每次获得不同的值时会发生这种情况。当另一个事务更新该数据并且我们当前的事务获取该更新的数据时会发生这种情况,从而导致不同的值。
为了解决这些问题,SQL 标准定义了 4 个标准隔离级别。它们如下:
- Read Uncommitted – 最低级别的隔离。在这里,事务不是孤立的,可以读取其他事务未提交的数据,从而导致脏读。
- Read Committed – 此级别可确保在读取时间的任何瞬间提交读取的数据。因此,这里避免了脏读。此级别使用当前行上的读/写锁,以防止在操作当前事务时对该行进行读/写/更新/删除。
- Repeatable Read– 最严格的隔离级别。这为其操作的所有行持有读和写锁。因此,避免了不可重复读取,因为其他事务无法读取、写入、更新或删除行。
- Serializable – 所有隔离级别中最高的。这保证了执行是可序列化的,其中任何并发操作的执行都保证显示为串行执行。
下表清楚地说明了级别避免的不需要的读取类型:
| 隔离级别 | 脏读 | 幻读 | 不可重复读取 |
|---|---|---|---|
| 读未提交 | 可能发生 | 可能发生 | 可能发生 |
| 读已提交 | 不会发生 | 可能发生 | 可能发生 |
| 可重复读取 | 不会发生 | 可能发生 | 不会发生 |
| 可序列化 | 不会发生 | 不会发生 | 不会发生 |
60. 关于 WAL(Write Ahead Logging),你能说些什么?
Write Ahead Logging 是一种通过在对数据库进行任何更改之前记录更改来提高数据库可靠性的功能。这通过帮助确定工作完成的时间点并从停止工作的时间点提供起点,确保我们在发生数据库崩溃时获得足够的信息。
如需更多信息,请参阅此处。
61. 使用 DROP TABLE 命令从现有表中删除数据的主要缺点是什么?
DROP TABLE命令从表中删除完整的数据,同时也删除完整的表结构。如果我们的要求只需要删除数据,那么我们需要重新创建表以在其中存储数据。在这种情况下,建议使用 TRUNCATE 命令。
62. PostgreSQL 中如何使用正则表达式进行不区分大小写的搜索?
要使用正则表达式执行不区分大小写的匹配,我们可以使用(~*)来自模式匹配运算符的POSIX表达式。例如:
'interviewbit' ~* '.*INTervIewBit.*'63. 你将如何备份 PostgreSQL 中的数据库?
我们可以通过使用 pg_dump 工具将数据库中的所有对象内容转储到单个文件中来实现这一点。步骤如下:
步骤1:导航到PostgreSQL安装路径的bin文件夹。
C:\>cd C:\Program Files\PostgreSQL\10.0\bin步骤 2:执行 pg_dump 程序将数据转储到 .tar 文件夹,如下所示:
pg_dump -U postgres -W -F t sample_data > C:\Users\admin\pgbackup\sample_data.tar数据库转储将存储在指定位置的 sample_data.tar 文件中。
64. PostgreSQL 是否支持全文搜索?
SQL常见的面试题有哪些?全文搜索是在基于全文的数据库中搜索存储在计算机上的单个文档或文档集合的方法。这主要在 SOLR 或 ElasticSearch 等高级数据库系统中得到支持。但是,该功能存在但在 PostgreSQL 中非常基础。
65. 什么是 PostgreSQL 中的并行查询?
并行查询支持是 PostgreSQL 中提供的一项功能,用于设计能够利用多个 CPU 处理器更快地执行查询的查询计划。
66. 区分提交和检查点。
提交动作确保事务的数据一致性得到维护,并在节中结束当前事务。Commit 在日志中添加一条新记录,描述内存中的 COMMIT。而检查点用于将提交到磁盘的所有更改写入到 SCN,这些更改将保存在数据文件头和控制文件中。
SQL常见的面试题和答案合集结论:
SQL 是一种数据库语言。它具有广泛的范围和强大的功能,可以使用 CREATE、ALTER、DROP 等命令创建和操作各种数据库对象,以及使用 INSERT 等命令加载数据库对象。它还提供使用 DELETE、TRUNCATE 等命令进行数据操作的选项,并使用 FETCH、SELECT 等游标命令有效检索数据。有许多此类命令为程序员提供大量控制以与数据库交互以一种有效的方式而不浪费很多资源。SQL 的普及程度如此之高,以至于几乎每个程序员都依赖它来实现其应用程序的存储功能,从而使其成为一种令人兴奋的学习语言。
PostgreSQL 是一个开源数据库系统,具有极其强大和复杂的 ACID、索引和事务支持,在开发人员社区中广受欢迎。

