
NumPy或Numeric Python是用于在均匀n维数组上进行计算的软件包。在numpy中, 尺寸称为轴。
为什么我们需要NumPy?
出现一个问题, 为什么在已经存在python列表的情况下我们为什么需要NumPy。答案是我们不能直接对两个列表的所有元素执行操作。例如, 我们不能直接将两个列表相乘, 而必须逐个元素地进行。这就是NumPy发挥作用的地方。
范例1:
# Python program to demonstrate a need of NumPy
list1 = [1, 2, 3, 4 , 5, 6]
list2 = [10, 9, 8, 7, 6, 5]
# Multiplying both lists directly would give an error.
print(list1*list2)输出:
TypeError: can't multiply sequence by non-int of type 'list'使用NumPy数组可以轻松完成此操作。
范例2:
# Python program to demonstrate the use of NumPy arrays
import numpy as np
list1 = [1, 2, 3, 4, 5, 6]
list2 = [10, 9, 8, 7, 6, 5]
# Convert list1 into a NumPy array
a1 = np.array(list1)
# Convert list2 into a NumPy array
a2 = np.array(list2)
print(a1*a2)输出:
array([10, 18, 24, 28, 30, 30])python的Numpy软件包具有以不同方式进行索引的强大功能。
使用索引数组建立索引
通过使用数组作为索引, 可以在numpy中完成索引。如果是切片, 则返回数组的视图或浅表副本, 但在索引数组中, 返回原始数组的副本。 Numpy数组可以与其他数组或任何其他序列(元组除外)建立索引。最后一个元素的索引为-1秒, 最后一个索引为-2, 依此类推。
范例1:
# Python program to demonstrate
# the use of index arrays.
import numpy as np
# Create a sequence of integers from
# 10 to 1 with a step of -2
a = np.arange(10, 1, -2)
print("\n A sequential array with a negative step: \n", a)
# Indexes are specified inside the np.array method.
newarr = a[np.array([3, 1, 2 ])]
print("\n Elements at these indices are:\n", newarr)输出:
A sequential array with a negative step:
[10 8 6 4 2]
Elements at these indices are:
[4 8 6]范例2:
import numpy as np
# NumPy array with elements from 1 to 9
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
# Index values can be negative.
arr = x[np.array([1, 3, -3])]
print("\n Elements are : \n", arr)输出:
Elements are:
[2 4 7]索引类型
索引有两种类型:
基本切片和索引编制:考虑语法x [obj], 其中x是数组, 而obj是索引。切片对象是基本切片时的索引。基本切片发生在obj为时:
- 一个切片对象, 其形式为start:stop:step
- 一个整数
- 或切片对象和整数的元组
通过基本切片生成的所有阵列始终都是原始阵列的视图。
代码1:
# Python program for basic slicing.
import numpy as np
# Arrange elements from 0 to 19
a = np.arange(20)
print("\n Array is:\n ", a)
# a[start:stop:step]
print("\n a[-8:17:1] = ", a[-8:17:1])
# The : operator means all elements till the end.
print("\n a[10:] = ", a[10:])输出:
Array is:
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
a[-8:17:1] = [12 13 14 15 16]
a[10:] = [10 11 12 13 14 15 16 17 18 19]代码2:
# Python program for basic slicing
# and indexing
import numpy as np
# A 3-Dimensional array
a = np.array([[0, 1, 2, 3, 4, 5]
[6, 7, 8, 9, 10, 11]
[12, 13, 14, 15, 16, 17]
[18, 19, 20, 21, 22, 23]
[24, 25, 26, 27, 28, 29]
[30, 31, 32, 33, 34, 35]]
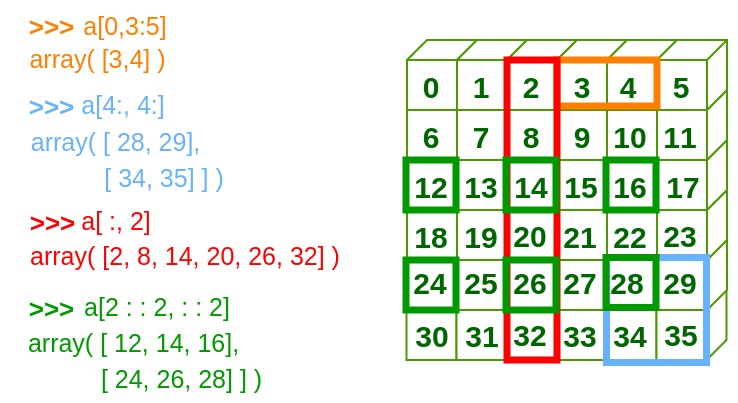
print("\n Array is:\n ", a)
# slicing and indexing
print("\n a[0, 3:5] = ", a[0, 3:5])
print("\n a[4:, 4:] = ", a[4:, 4:])
print("\n a[:, 2] = ", a[:, 2])
print("\n a[2:;2, ::2] = ", a[2:;2, ::2])输出:
Array is:
[[0 1 2 3 4 5]
[6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]
[30 31 32 33 34 35]]
a[0, 3:5] = [3 4]
a[4:, 4:] = [[28 29], [34 35]]
a[:, 2] = [2 8 14 20 26 32]
a[2:;2, ::2] = [[12 14 16], [24 26 28]]下图使概念更清晰:
省略号也可以与基本切片一起使用。省略号(…)是使选择元组的长度与数组维数相同的:对象的数量。
# Python program for indexing using
# basic slicing with ellipsis
import numpy as np
# A 3 dimensional array.
b = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
print(b[..., 1]) #Equivalent to b[: , : , 1 ]输出:
[[ 2 5]
[ 8 11]]高级索引:
当obj为–时, 将触发高级索引
- 整数或布尔类型的ndarray
- 或具有至少一个序列对象的元组
- 是一个非元组序列对象
高级索引返回数据的副本, 而不是其视图。高级索引有整数和布尔两种类型。
纯整数索引:当整数用于索引时。第一维的每个元素与第二维的元素配对。因此, 在这种情况下元素的索引为(0, 0), (1, 0), (2, 1), 并选择了相应的元素。
# Python program showing advanced indexing
import numpy as np
a = np.array([[1 , 2 ], [3 , 4 ], [5 , 6 ]])
print(a[[0 , 1 , 2 ], [0 , 0 , 1]])输出:
[1 3 6]结合高级索引和基本索引:当索引中至少有一个切片(:), 省略号(...)或换轴符(或数组的维数多于高级索引)时, 行为可能会更加复杂。就像将每个高级索引元素的索引结果连接起来一样
在最简单的情况下, 只有一个高级索引。例如, 单个高级索引可以替换切片, 并且结果数组将相同, 但是, 它是一个副本, 并且可能具有不同的内存布局。如果可能的话, 切片是优选的。
# Python program showing advanced
# and basic indexing
import numpy as np
a = np.array([[0 , 1 , 2], [3 , 4 , 5 ], [6 , 7 , 8], [9 , 10 , 11]])
print(a[1:2 , 1:3 ])
print(a[1:2 , [1, 2]])输出:
[4, 5]
[4, 5]了解情况的最简单方法可能是根据结果形状进行思考。索引操作分为两部分, 基本索引定义的子空间(不包括整数)和高级索引部分的子空间。需要区分索引组合的两种情况:
高级索引由切片, 省略号或新轴分隔。例如
x [arr1, :, arr2]
.
高级索引彼此相邻。例如
x [..., arr1, arr2, :]
但不是
x [arr1, :, 1]
因为1是这方面的高级索引。
在第一种情况下, 由高级索引操作产生的维数首先出现在结果数组中, 然后是子空间维数。在第二种情况下, 将来自高级索引操作的维度插入到结果数组中, 其位置与初始数组中的位置相同(后一种逻辑使简单的高级索引表现得像切片一样)。
布尔数组索引:
该索引具有一些布尔表达式作为索引。返回满足该布尔表达式的那些元素。它用于过滤所需的元素值。
代码#1
# You may wish to select numbers greater than 50
import numpy as np
a = np.array([10, 40, 80, 50, 100])
print(a[a>50])输出:
[80 100]代码#2
# You may wish to square the multiples of 40
import numpy as np
a = np.array([10, 40, 80, 50, 100])
print(a[a%40==0]**2)输出:
[1600 6400])代码#3
# You may wish to select those elements whose
# sum of row is a multiple of 10.
import numpy as np
b = np.array([[5, 5], [4, 5], [16, 4]])
sumrow = b.sum(-1)
print(b[sumrow%10==0])输出:
array([[ 5, 5], [16, 4]])![从字法上最小长度N的排列,使得对于正好为K个索引,a[i] a[i]+1](https://www.lsbin.com/wp-content/themes/begin%20lts/img/loading.png)
